标签:9.png 多个 logs 就会 方式 解码 log 还原 不一致
参考:https://segmentfault.com/a/1190000004450876
Bytes 对象是由单个字节作为基本元素(8位,取值范围 0-255)组成的序列,为不可变对象。
Bytes 对象只负责以二进制字节序列的形式记录所需记录的对象,至于该对象到底表示什么(比如到底是什么字符)则由相应的编码格式解码所决定。我们可以通过调用 bytes() 类(没错,它是类,不是函数)生成 bytes 实例,其值形式为 b‘xxxxx‘,其中 ‘xxxxx‘ 为一至多个转义的十六进制字符串(单个 x 的形式为:\xHH,其中 \x 为小写的十六进制转义字符,HH 为二位十六进制数)组成的序列,每个十六进制数代表一个字节(八位二进制数,取值范围 0-255),对于同一个字符串如果采用不同的编码方式生成 bytes 对象,就会形成不同的值:
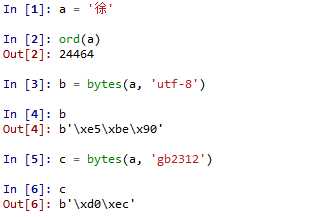
比如上例中的 a 字符串对象,其十进制 unicode 值为 24464,分别使用 ‘utf-8‘ 和 ‘gb2312‘ 两种编码格式将其转换成 bytes 对象 b 和 c ,结果 b 和 c 的值是完全不同的,由于基于的编码格式不一致, b c 长度甚至都不相同,前者有 3 个字节长度,后者有 2 个字节长度:
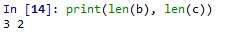
另外,对于 ASCII 字符串,可以直接使用 b‘xxxx‘ 赋值创建 bytes 实例,但对于非 ASCII 编码的字符则不能通过这种方式创建 bytes 实例:
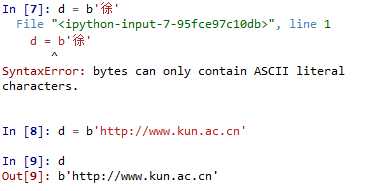
由于 bytes 是序列,因此我们可以通过索引或切片访问它的元素:
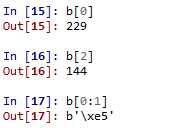
可以发现如果以单个索引的形式访问元素,其会直接返回单个字节的十进制整数,而以序列片段的形式访问时,则返回相应的十六进制字符序列。
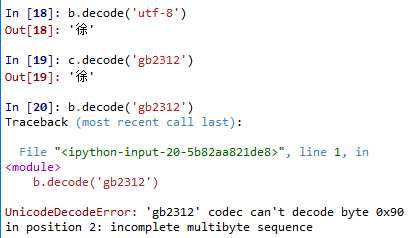
对于 bytes 实例,如果需要还原成相应的字符串,则需要借助内置的解码函数 decode(),借助相应的编码格式解码为正常字符串对象,如果采用错误的编码格式解码,则有可能发生错误:
标签:9.png 多个 logs 就会 方式 解码 log 还原 不一致
原文地址:http://www.cnblogs.com/revo/p/7249595.html
{kind=link}