标签:通过 操作系统 节点 文件读写 顺序 分布 删除 ora mil
Kafka是linkedin用于日志处理的分布式消息队列,linkedin的日志数据容量大,但对可靠性要求不高,其日志数据主要包括用户行为(登录、浏览、点击、分享、喜欢)以及系统运行日志(CPU、内存、磁盘、网络、系统及进程状态
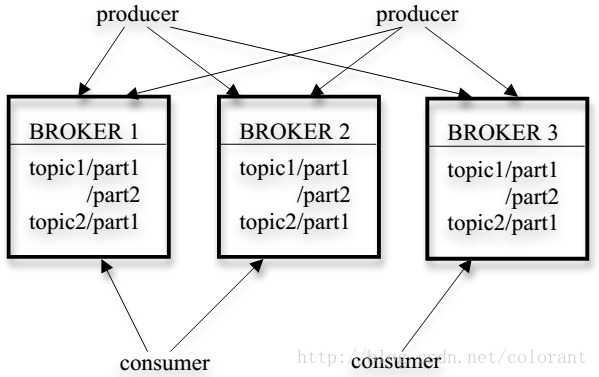
kafka的集群由多个Broker服务器组成,每个类型的消息被定义为topic,同一topic内部的消息按照一定的key和算法被分区(partition)存储在不同的Broker上,消息生产者 producer 和消费者consumer可以在多个Broker上生产/消费topic
(1)消息队列是以log文件的形式存储,消息生产者只能将消息添加到既有的文件尾部,没有任何ID信息用于消息的定位,完全依靠文件内的位移,因此消息的使用者只能依靠文件位移顺序读取消息,这样也就不需要维护复杂的支持随即读取的索引结构。
(2)kafka broker完全不维护和协调多用户使用消息的行为模式,用户自己维护位移用来索引消息
(3)最小的并发访问单位就是partition分区,同一用户组内的所有用户(可以理解为同一个应用的所有并发进程)只能有一个访问同一分区,同时分区的个数是固定的,不支持动态调整。这样最大简化了多进程/分布式client之间对消息处理访问的并发控制的复杂度,当然也带来一定的使用模式上的限制(比如最大并发度完全取决于预先规划的partition的个数),此外分区也带来一个问题就是消息只是分区内部有序而不是全局有序的。如果需要全局有序,应用需要自己靠别的机制来保证
(4)使用主动拉(Pull)的模式派发消息,消息的使用情况,比如是否还有consumer没有读取,是否重复读取(改进中)等,在Broker端也完全不跟踪维护,消息的过期处理简单的由定时器定时删除(比如保留7天),由此简化各种消息跟踪维护的开销。
(5)在0.8版本中,添加了数据replica的机制,一个消息分区的多个replica分布在不同的Broker上,由leader replica负责日常读写,通过zookeeper监督follower,不同的分区的leader replica均衡负载到不同的Broker上。在这种情况下,producer可以选择不等待leader replica的Ack,部分Ack,或者完全备份完毕后Ack等不同的ack机制。这三种机制,性能依次递减 (producer吞吐量降低1-3倍),数据健壮性则依次递增。
(6) 采取各种方式最大化数据传输效率,比如生产者和消费者可以批量读写消息减少RPC开销,使用Zero Copy方式在内核层直接将文件内容传送给网络Socket,避免应用层数据拷贝
(7)激进的内存管理模式,基本的意思就是不管理。kafka不在JVM进程内部维护消息Cache,消息直接从文件中读写,完全依赖操作系统在文件系统层面的cache,避免在JVM中管理Cache带来的额外数据结构开销和GC带来的性能代价。基于批量处理和顺序读写的应用模式,最大化利用文件系统的Cache机制和规避文件读写相对内存读写的性能代价。
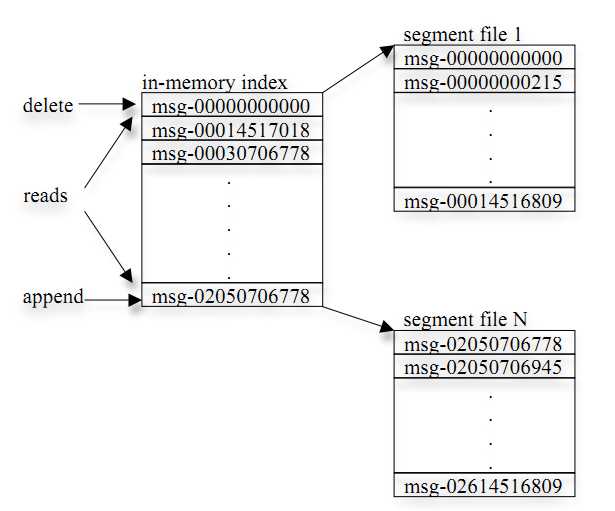
(1) kafka以topic来进行消息管理,每个topic包含多个partition,每个 partition 对应一个逻辑 log,由多个segment组成
(2) 每个segment中存储多条消息,如下图所示,消息id由其逻辑位置决定,即从消息id可直接定位到消息的存储位置,避免id到位置的额外映射。
(3) 每个partition 在内存中对应一个index,记录每个segment中的第一条消息偏移。
(4) 发布者发到某个topic的消息会被均匀的分布到多个partition上(随机或根据用户指定的回调函数进行分布),broker收到发布消息往对应part的最后一个segment上添加该消息,当某个segment上的消息条数达到配置值或消息发布时间超过阈值时,segment上的消息会被flush到磁盘,只有flush到磁盘上的消息订阅者才能订阅到,segment达到一定的大小后将不会再往该segment写数据,broker会创建新的segment。
(1) 发布消息时,kafka client先构造一条消息,将消息加入到消息集set中( kafka支持批量发布,可以往消息集合中添加多条消息,一次行发布),send消息时,client需指定消息所属的topic。
(2)订阅消息时,kafka client需指定topic以及partition num(每个partition对应一个逻辑日志流,如topic代表某个产品线,partition代表产品线的日志按天切分的结果)client订阅后,就可迭代读取消息,如果没有消息,client会阻塞直到有新的消息发布。
(3)consumer可以累积确认接收到的消息,当其确认了某个offset的消息,意味着之前的消息也都已成功接收到,此时broker会更新zookeeper上地offset registry。
(4)一个topic可以被多个 Consumer group 分别消费 ,但是每个Consumer group中只能有一个Consumer消费此消息,一个group内的consumer只能消费不同的partition,即一个partition只能被一个consumer消费
(1) 管理broker与consumer的动态加入与离开,每个broker启动后,会在zookeeper上注册一个临时的节点(broker registry):包含broker的ip地址和端口号,所存储的topics和partitions信息。每个consumer启动后会在zookeeper上注册一个临时的节点(consumer registry):包含consumer所属的consumer group以及订阅的topics。
(2) 触发负载均衡,当broker或consumer加入或离开时会触发负载均衡算法,使得一个consumer group内的多个consumer的订阅负载平衡。
(3) 维护消费关系及每个partion的消费信息。每个consumer group关联一个临时的owner registry和一个持久的offset registry。对于被订阅的每个partition包含一个owner registry,内容为订阅这个partition的consumer id;同时包含一个offset registry,内容为上一次订阅的offset。
标签:通过 操作系统 节点 文件读写 顺序 分布 删除 ora mil
原文地址:http://www.cnblogs.com/sunfie/p/7252523.html