标签:struts hello tcl init 另一个 XML 标签 ima 反射原理
以下是个人中学习过程中对struts2的一些理解,有不对的地方大家多多提出指正,小弟拜谢!
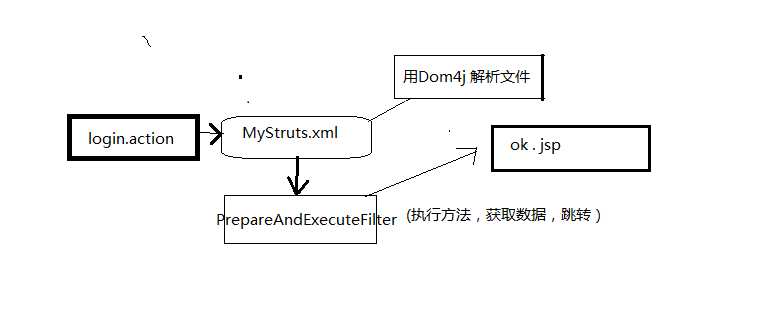
解析MyStruts.xml文件的过程:
需要几个核心类:包括
StrutsInfo类,用来装struts标签里的属性参数name、class、method,
还需要一个集合用来装result标签里的属性,所以需要另一个类:
ResultInfo类,同样是装result标签里的属性参数,name、type、location(是跳转的地址)
然后需要一个ActionMapper来解析该文件,内有一个解析的方法parse(),和一个装ActionInfo的Map集合
/*Map<String,ActionInfo> actionMap 如请求为hello.action, 则String为hello,交给ActionInfo这个类来处理;*/
注意:该解析xml方法parse()可以放到过滤器PreparedAndExecuteFilter到init方法中,因为只需要解析一次
而在真正的doFilter方法中执行,步骤如下:
1,根据请求request可以找到对应的action对象(如hello.action,可以得到name为hello的action对象)
ActionInfo actionInfo = request.getReqUri() ----/hello.action 字符串拼接得到action
通过actionMap.get("hello"),可以得到hello的actionInfo对象
2,创建一个统一的代理对象,以便后面保证是同一个对象
Object actionProxy = actionInfo.getClassName() Class.forName(className).newInstance(); 利用反射的原理
3,调用actionInfo类 和方法去执行,需要actionProxy 和actionInfo
利用反射原理得到该类中所有方法,得到result = method.invoke(actionProxy);
4,根据得到的result可以得到resultInfo对象
5,根据resultInfo得到包含的数据,并响应到客户端(根据type类型来实现转发还是重定向)。
标签:struts hello tcl init 另一个 XML 标签 ima 反射原理
原文地址:http://www.cnblogs.com/wuhu/p/7255954.html