标签:style 过程 兴趣 传统 http 开放 访问 集群 永久
一、Zookeeper背景
随着互联网技术的发展,企业对计算机系统的计算,存储能力要求越来越高,各大IT企业都在追求高并发,海量存储的极致,在这样的背景下,单纯依靠少量高性能单机来完成计算机,云计算的任务已经无法满足需求,企业的IT架构逐渐由集中式往分布式过渡。所谓的分布式是指:把一个计算任务分解成若干个计算单元,并分派到不同的计算机中去执行,最终汇总计算结果的过程。
二、Zookeeper概述
Zookeeper是源代码开放的分布式协调服务,是一个高性能的分布式数据一致性的解决方案,它将那些复杂的,容易出错的分布式一致性服务封装起来。用户可以通过调用Zookeeper提供的接口来解决一些分布式应用中的实际问题。
三、Zookeeper典型应用场景
(1)数据发布/订阅
数据的发布与订阅,顾名思义就是一方把数据发布出来,另一方通过某种手段获取。
通常数据发布与订阅有两种模式:推模式和拉模式,推模式一般是服务器主动往客户端推送信息,拉模式是客户端主动去服务端请求目标数据(通常采用定时轮询的方式)
Zookeeper采用两种方式互相结合:发布者将数据发布到Zookeeper集群节点上,订阅者通过一定的方法告诉Zookeeper服务器,自己对哪个节点的数据感兴趣,那么在服务端数据发生变化时,就会通知客户端去获取这些信息。
(2)负载均衡
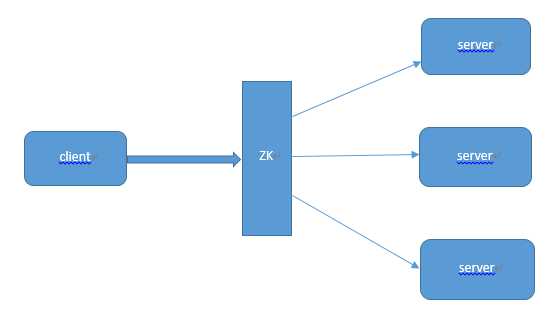
首先在服务端启动的时候,把自己在zookeeper服务器上注册成一个临时节点。zookeeper拥有两种形式的节点,一种是临时节点,一种是永久节点。这两种节点后面的博客会有较为详细的介绍。注册成临时节点后,再服务端出问题时,节点会自动的从zookeeper上删除,如此zookeeper服务器上的列表就是最新的可用的列表。
客户端在需要访问服务器的时候首先会去Zookeeper获得所有可用的服务端的连接信息。
客户端通过一定的策略(如随机)选择一个与之建立连接。
当客户端发现连接不可用时,会再次从zookeeper上获取可用的服务端连接,并同时删除之前获取的连接列表。
(3)命名服务
提供名称的服务。如一般使用较多的有两种id,一种是数据库自增长id,一种是UUID,两种id都有局限,自增长id仅适合在单表单库中使用,uuid适合在分布式系统中使用但由于id没有规律难以理解。而ZK提供了一定的接口可以用来获取一个顺序增长的,可以在集群环境下使用的id。
(4)分布式协调,通知,心跳服务
在分布式服务系统中,我们常常需要知道哪个服务是可用的,哪个服务是不可用的,传统的方式是通过ping主机来实现的,ping得200的结果说明说明该服务是OK的。
而在使用 zookeeper时,可以将所有的服务都注册成一个临时节点,我们判断一个服务是否可用,只需要判断这个节点是否在zookeeper集群中存在就可以了,不需要直接去连接和ping服务所在主机,减少系统的复杂度和对服务主机的压力。
四、Zookeeper优势
(1)源代码开放
(2)高性能,易用稳定,该优势已在众多分布式系统中得到验证
(3)有着广泛的应用,并且与众多大数据相关技术能实现良好的融合开发。
标签:style 过程 兴趣 传统 http 开放 访问 集群 永久
原文地址:http://www.cnblogs.com/jiyukai/p/7256019.html