标签:path gem exec 集群架构图 com http $path 界面 版本
本节内容:
Apache Storm是自由开源的分布式实时计算系统,擅长处理海量数据,适用于数据实时处理而非批处理。
批处理使用的大多是鼎鼎大名的hadoop或者hive,作为一个批处理系统,hadoop以其吞吐量大、自动容错等优点,在海量数据处理上得到了广泛的使用。但是,hadoop不擅长实时计算,因为它天然就是为批处理而生的,这也是业界一致的共识。否则最近几年也不会有s4,storm,puma这些实时计算系统如雨后春笋般冒出来啦。
举个搜索场景中的例子,当一个卖家发布了一条宝贝信息时,他希望的当然是这个宝贝马上就可以被卖家搜索出来、点击、购买啦,相反,如果这个宝贝要等到第二天或者更久才可以被搜出来,估计就会有不少损失了。 再举一个推荐的例子,如果用户昨天在淘宝上买了一双袜子,今天想买一副泳镜去游泳,但是却发现系统在不遗余力地给他推荐袜子、鞋子,根本对他今天寻找泳镜的行为视而不见,这样商家的利益就有所损失。这是因为后台系统做的是每天一次的全量处理,而且大多是在夜深人静之时做的,那么客户今天白天做的事情要到明天才能反映出来。这也就是为什么需要实时处理的原因。
1. Storm集群架构图
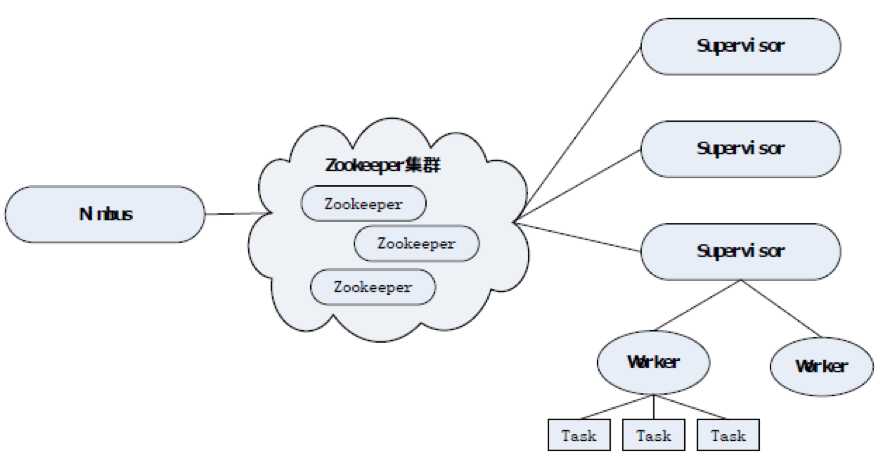
Zookeeper集群在Storm集群中的作用:
Zookeeper集群负责Nimbus节点和Supervior节点之间的通信,监控各个节点之间的状态。比如通常我们提交任务的时候是在Nimbus节点上执行的,Nimbus节点通过zk集群将任务分发下去,而Supervisor是真正执行任务的地方。Nimbus节点通过zk集群监控各个Supervisor节点的状态,当某个Supervisor节点出现故障的时候,Nimbus节点就会通过zk集群将那个Supervisor节点上的任务重新分发,在其他Supervisor节点上执行。这就意味着Storm集群也是高可用集群,如果Nimbus节点出现故障的时候,整个任务并不会停止,但是任务的管理会出现影响,通常这种情况下我们只需要将Nimbus节点恢复就可以了。Nimbus节点不支持高可用,这也是Storm目前面临的问题之一。不过一般情况下,Nimbus节点的压力不大,通常不会出现问题。
一般情况下,Zookeeper集群的压力并不大,一般只需要部署3台就够了。Zookeeper集群在Storm集群中逻辑上是独立的,但在实际部署的时候,一般会将zk节点部署在Nimbus节点或Supervisor节点上。
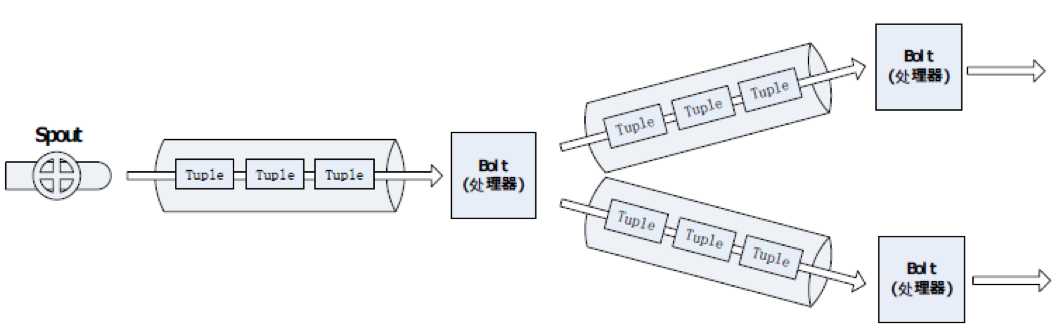
2. 数据处理流程图
storm处理数据的特点:数据源源不断,不断处理。
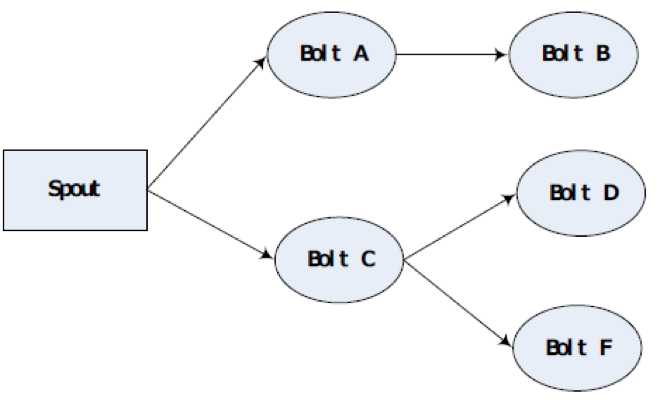
3. 拓扑图分析
storm中是没有数据存储结构的,我们需要自己设计数据落地接口,指明数据存储到哪一部分中。Storm本身是不存储数据的。
1. 环境信息
| 主机名 | 操作系统版本 | IP地址 | 安装软件 |
| log1 | CentOS 7.0 | 114.55.29.86 | JDK1.7、zookeeper-3.4.6、apache-storm-1.0.0 |
| log1 | CentOS 7.0 | 114.55.29.241 | JDK1.7、zookeeper-3.4.6、apache-storm-1.0.0 |
| log3 | CentOS 7.0 | 114.55.253.15 | JDK1.7、zookeeper-3.4.6、apache-storm-1.0.0 |
2. 安装Zookeeper集群
参见之前的文章《Zookeeper介绍及安装部署》。
3. 安装Storm集群
log1、log2和log3部署storm集群,log1作为Nimbus节点,log2和log3作为surpervisor节点。
(1)下载安装软件并解压
[root@log1 local]# wget http://apache.fayea.com/storm/apache-storm-1.0.0/apache-storm-1.0.0.tar.gz [root@log1 local]# tar zxf apache-storm-1.0.0.tar.gz
(2)配置storm
[root@log1 ~]# cd /usr/local/apache-storm-1.0.0/ [root@log1 apache-storm-1.0.0]# vim conf/storm.yaml

storm.local.dir: "/usr/local/apache-storm-1.0.0/status"
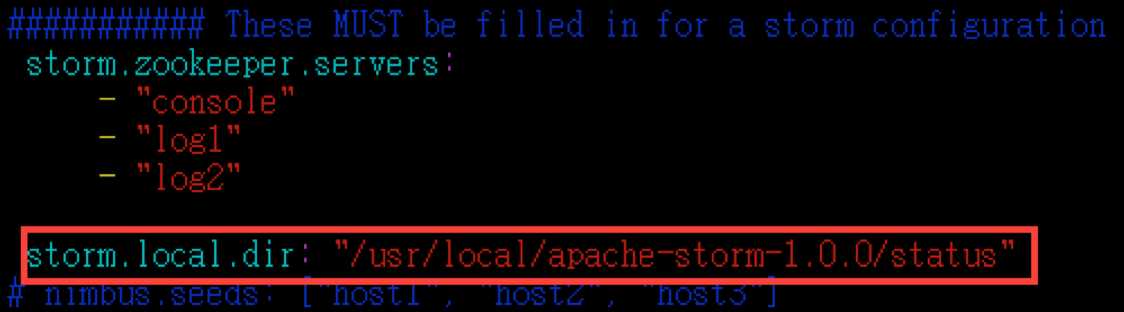
这个status目录在storm启动的时候会自动创建,当然也可以提前创建好。

supervisor.slots.ports: - 6700 - 6701 - 6702 - 6703
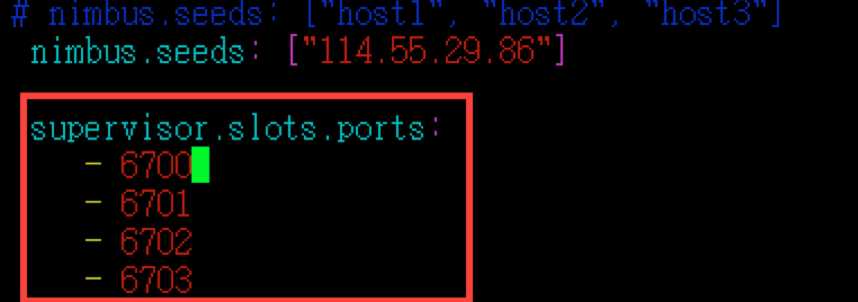
配置工作节点上的进程端口。你配置一个端口,意味着工作节点上启动一个worker,在实际的生产环境中,我们需要根据实际的物理配置以及每个节点上的负载情况来配置这个端口的数量。在这里每个节点我象征性的配置4个端口。
注意:以上配置,凡是有冒号的地方,冒号后都要有个空格。
log2和log3主机也是同样的配置。拷贝这台机器的storm包到log2和log3主机:
[root@log1 local]# scp -pr apache-storm-1.0.0 root@114.55.29.241:/usr/local/ [root@log1 local]# scp -pr apache-storm-1.0.0 root@114.55.253.15:/usr/local/
supervisor.childopts: -verbose:gc -XX:+PrintGCTimeStamps -XX:+PrintGCDetails -Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.ssl=false -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.port=9998

9998就是用于通过JMX收集supervisior JVM指标的端口。
(3)配置storm环境变量
[root@log1 apache-storm-0.10.0]# vim /etc/profile export STORM_HOME=/usr/local/apache-storm-0.10.0 export PATH=$STORM_HOME/bin:$PATH [root@log1 apache-storm-0.10.0]# source /etc/profile
log1节点启动nimbus和storm ui:
[root@log1 ~]# nohup storm ui >/dev/null 2>&1 & [root@log1 ~]# nohup storm nimbus >/dev/null 2>&1 &
log2和log3主机启动Supervisor节点:
[root@log2 ~]# nohup storm supervisor >/dev/null 2>&1 & [root@log3 ~]# nohup storm supervisor >/dev/null 2>&1 &
访问ui页面: http://114.55.29.86:8080/
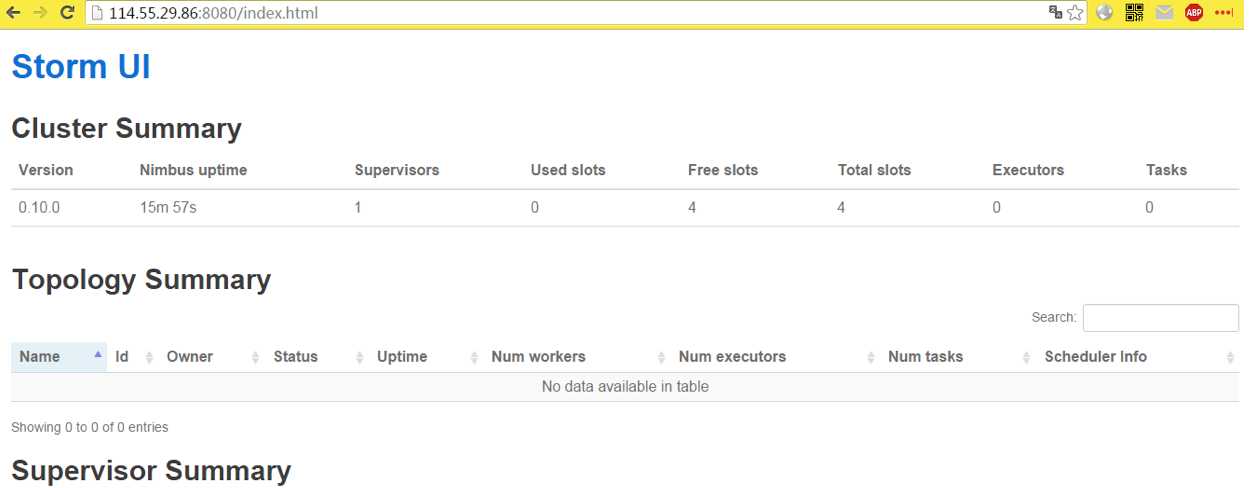
界面简单介绍:
标签:path gem exec 集群架构图 com http $path 界面 版本
原文地址:http://www.cnblogs.com/zhaojiankai/p/7257617.html