标签:设置 没有 san 冒号 linux set ati image frame
首先先不看理论,搭建起环境之后再看;
搭建伪分布式是为了模拟环境,调试方便。
电脑是win10,用的虚拟机VMware Workstation 12 Pro,跑的Linux系统是centos6.5 ,装的hadoop2.6.0,jdk1.8;
1.准备工作
准备工作:把JDK和Hadoop安装包上传到linux系统(hadoop用户的根目录)
系统环境:IP:192.168.80.99,
linux用户:
root/123456,hadoop/123456
主机名:node
把防火墙关闭,root执行:service iptables stop
2.jdk安装
1.在hadoop用户的根目录,Jdk解压,(hadoop用户操作)tar -zxvf jdk-8u65-linux-x64.tar.gz 解压完成后,在hadoop用户的根目录有一个jdk1.8.0_65目录
2.配置环境变量,需要修改/etc/profile文件(root用户操作)切到root用户,输入su命令 vi /etc/profile 进去编辑器后,输入i,进入vi编辑器的插入模式在profile文件最后添加
|
JAVA_HOME=/home/hadoop/jdk1.8.0_65 export PATH=$PATH:$JAVA_HOME/bin |
编辑完成后,按下esc退出插入模式输入:,这时在左下角有一个冒号的标识
q 退出不保存
wq 保存退出
q! 强制退出
3.把修改的环境变量生效(hadoop用户操作)
执行source /etc/profile
4.执行 java -version 查看版本,如果成功证明jdk配置成功
3.Hadoop 安装
1.在hadoop用户的根目录,解压(hadoop用户操作)
tar -zxvf hadoop-2.6.0.tar.gz
解压完成在hadoop用户的根目录下有一个hadoop-2.6.0目录
2.修改配置文件hadoop-2.6.0/etc/hadoop/hadoop-env.sh(hadoop用户操作)
export JAVA_HOME=/home/hadoop/jdk1.8.0_65
3.修改配置文件hadoop-2.6.0/etc/hadoop/core-site.xml,添加(hadoop用户操作)
|
<property> <name>fs.defaultFS</name> <value>hdfs://node:9000</value> </property> |
4.修改配置文件hadoop-2.6.0/etc/hadoop/hdfs-site.xml,添加(hadoop用户操作)
|
<property> <name>dfs.replication</name> <value>1</value> </property> |
5.修改修改配置文件hadoop-2.6.0/etc/hadoop/mapred-site.xml (hadoop用户操作),这个文件没有,需要复制一份
cp etc/hadoop/mapred-site.xml.template etc/hadoop/mapred-site.xml
添加
|
<property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> |
6.修改配置文件hadoop-2.6.0/etc/hadoop/yarn-site.xml,添加(hadoop用户操作)
|
<property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> |
7.修改主机名称(root用户操作),重启生效
vi /etc/sysconfig/network
修改HOSTNAME的值为用户名
8.修改/etc/hosts文件(root用户操作),添加: ip 主机名称
192.168.44.199(用自己的ip,下边讲如何获得) node
附:查看ip地址
编辑-->虚拟网络编辑器
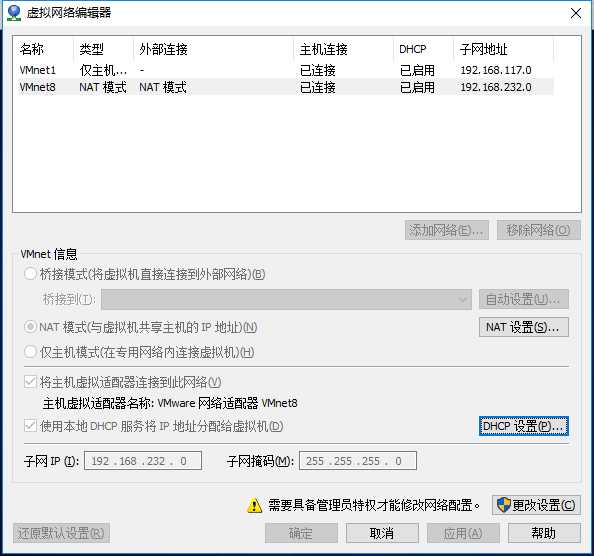
net模式,选DHCP设置,得到ip地址起始
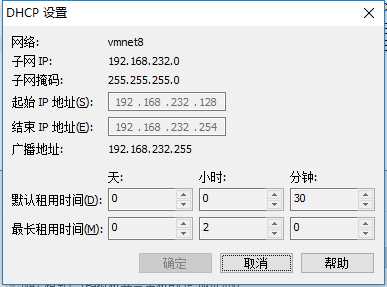
net设置,得到网关
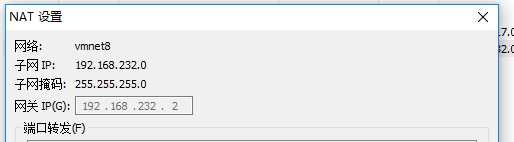
点右边小电脑,选择 VPN Connections-->Configue VPN
选中eth0,点有右边edit
选择IP Settings ,根据自己的ip按图修改,Address就是你的ip地址,在起始ip地址和结束ip地址之间选一个就行
9.格式化HDFS,在hadoop解压目录下,执行如下命令:(hadoop用户操作)
bin/hdfs namenode -format
注意:格式化只能操作一次,如果因为某种原因,集群不能用, 需要再次格式化,需要把上一次格式化的信息删除,在/tmp目录里执行 rm –rf *
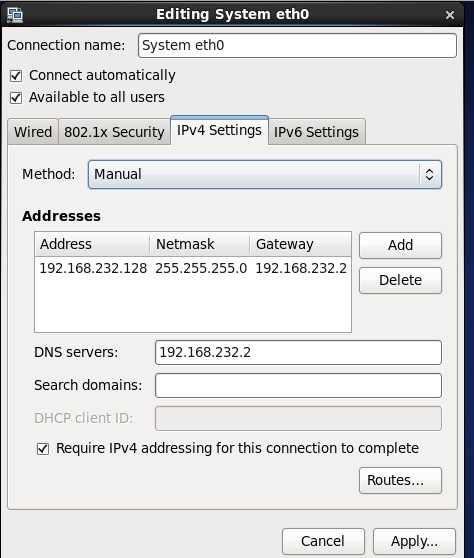
10.启动集群,在hadoop解压目录下,执行如下命令:(hadoop用户操作,截图用机后来改过,主机为gp)
启动集群:sbin/start-all.sh 需要输入四次当前用户的密码(通过配置ssh互信解决,截图用机已经配置过ssh不用输密码)
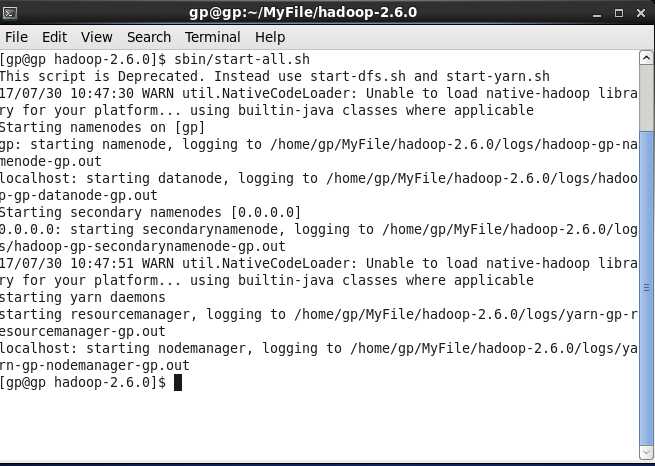
启动后,在命令行输入jps有以下输出
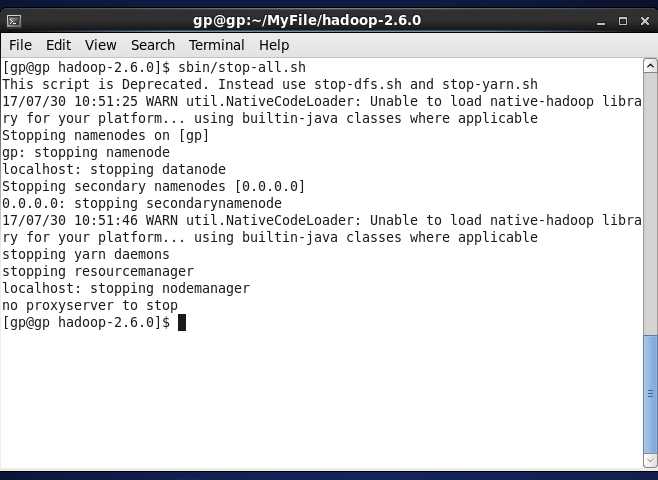
关闭集群:sbin/stop-all.sh 需要输入四次当前用户的密码(通过配置ssh互信解决,我的同上)
4.SSH互信配置(hadoop用户操作)
rsa加密方法,公钥和私钥
1.生成公钥和私钥
在命令行执行ssh-keygen,然后回车,然后会提示输入内容,什么都不用写,一路回车
在hadoop用户根目录下,有一个.ssh目录
id_rsa 私钥
id_rsa.pub 公钥
known_hosts 通过SSH链接到本主机,都会在这里有记录
2.把公钥给信任的主机(本机)
在命令行输入ssh-copy-id 主机名称
ssh-copy-id hadoop
复制的过程中需要输入信任主机的密码
3.验证,在命令行输入:ssh 信任主机名称
ssh hadoop
如果没有提示输入密码,则配置成功

至此,大功告成。
Hadoop新生报到(一) hadoop2.6.0伪分布式配置详解
标签:设置 没有 san 冒号 linux set ati image frame
原文地址:http://www.cnblogs.com/alexfly/p/7258509.html