标签:变化 pos ilo data 影响 app change 本质 otto
(标题不能再中二了)本文仅对一些常见的优化方法进行直观介绍和简单的比较,各种优化方法的详细内容及公式只好去认真啃论文了,在此我就不赘述了。
此处的SGD指mini-batch gradient descent,关于batch gradient descent, stochastic gradient descent, 以及 mini-batch gradient descent的具体区别就不细说了。现在的SGD一般都指mini-batch gradient descent。
SGD就是每一次迭代计算mini-batch的梯度,然后对参数进行更新,是最常见的优化方法了。即:
其中,是学习率,
是梯度 SGD完全依赖于当前batch的梯度,所以
可理解为允许当前batch的梯度多大程度影响参数更新
缺点:(正因为有这些缺点才让这么多大神发展出了后续的各种算法)
momentum是模拟物理里动量的概念,积累之前的动量来替代真正的梯度。公式如下:
其中,是动量因子
特点:
nesterov项在梯度更新时做一个校正,避免前进太快,同时提高灵敏度。 将上一节中的公式展开可得:
可以看出,并没有直接改变当前梯度
,所以Nesterov的改进就是让之前的动量直接影响当前的动量。即:
所以,加上nesterov项后,梯度在大的跳跃后,进行计算对当前梯度进行校正。如下图:
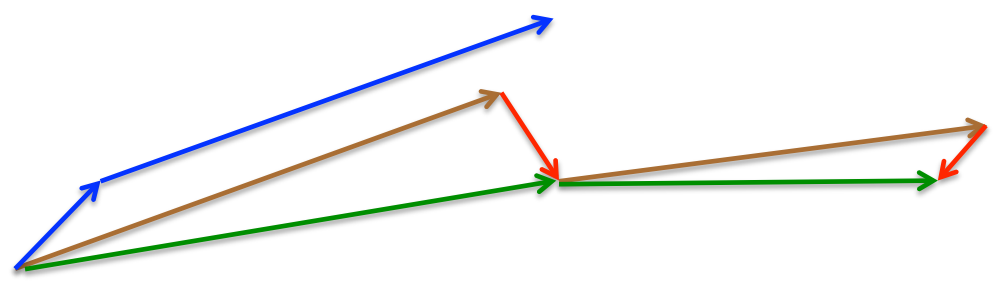
momentum首先计算一个梯度(短的蓝色向量),然后在加速更新梯度的方向进行一个大的跳跃(长的蓝色向量),nesterov项首先在之前加速的梯度方向进行一个大的跳跃(棕色向量),计算梯度然后进行校正(绿色梯向量)
其实,momentum项和nesterov项都是为了使梯度更新更加灵活,对不同情况有针对性。但是,人工设置一些学习率总还是有些生硬,接下来介绍几种自适应学习率的方法
Adagrad其实是对学习率进行了一个约束。即:
此处,对从1到
进行一个递推形成一个约束项regularizer,
,
用来保证分母非0
特点:
Adadelta是对Adagrad的扩展,最初方案依然是对学习率进行自适应约束,但是进行了计算上的简化。 Adagrad会累加之前所有的梯度平方,而Adadelta只累加固定大小的项,并且也不直接存储这些项,仅仅是近似计算对应的平均值。即:
在此处Adadelta其实还是依赖于全局学习率的,但是作者做了一定处理,经过近似牛顿迭代法之后:
其中,代表求期望。
此时,可以看出Adadelta已经不用依赖于全局学习率了。
特点:
RMSprop可以算作Adadelta的一个特例:
当时,
就变为了求梯度平方和的平均数。
如果再求根的话,就变成了RMS(均方根):
此时,这个RMS就可以作为学习率的一个约束:
特点:
Adam(Adaptive Moment Estimation)本质上是带有动量项的RMSprop,它利用梯度的一阶矩估计和二阶矩估计动态调整每个参数的学习率。Adam的优点主要在于经过偏置校正后,每一次迭代学习率都有个确定范围,使得参数比较平稳。公式如下:
其中,,
分别是对梯度的一阶矩估计和二阶矩估计,可以看作对期望
,
的估计;
,
是对
,
的校正,这样可以近似为对期望的无偏估计。 可以看出,直接对梯度的矩估计对内存没有额外的要求,而且可以根据梯度进行动态调整,而
对学习率形成一个动态约束,而且有明确的范围。
特点:
Adamax是Adam的一种变体,此方法对学习率的上限提供了一个更简单的范围。公式上的变化如下:
可以看出,Adamax学习率的边界范围更简单
Nadam类似于带有Nesterov动量项的Adam。公式如下:
可以看出,Nadam对学习率有了更强的约束,同时对梯度的更新也有更直接的影响。一般而言,在想使用带动量的RMSprop,或者Adam的地方,大多可以使用Nadam取得更好的效果。
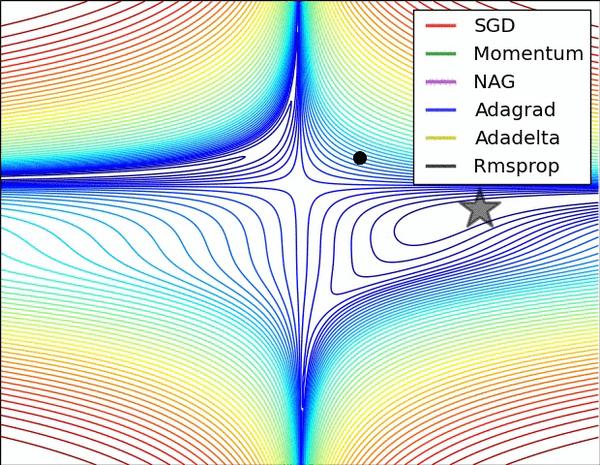 损失平面等高线
损失平面等高线
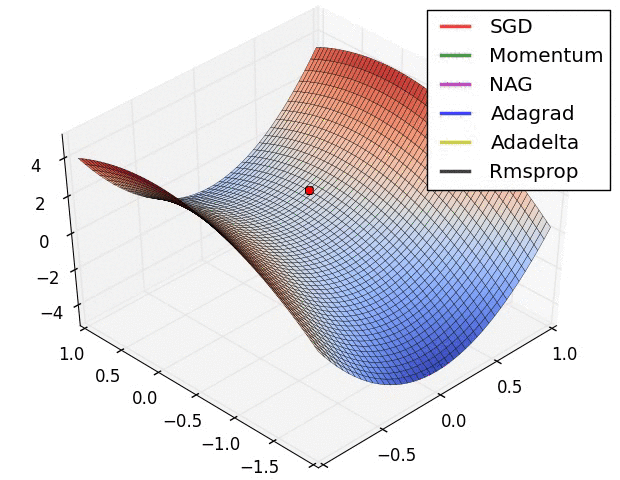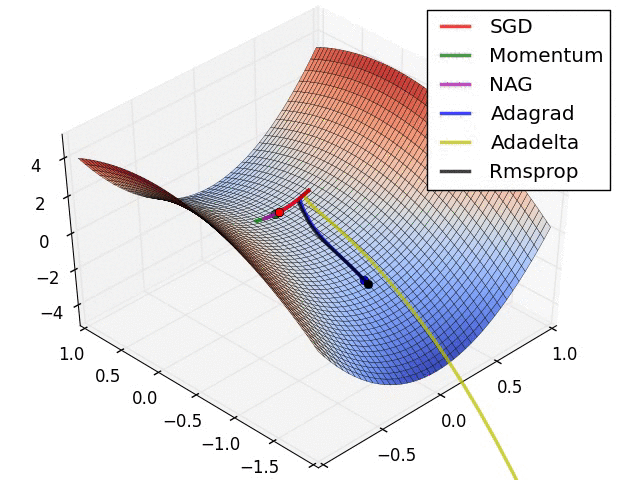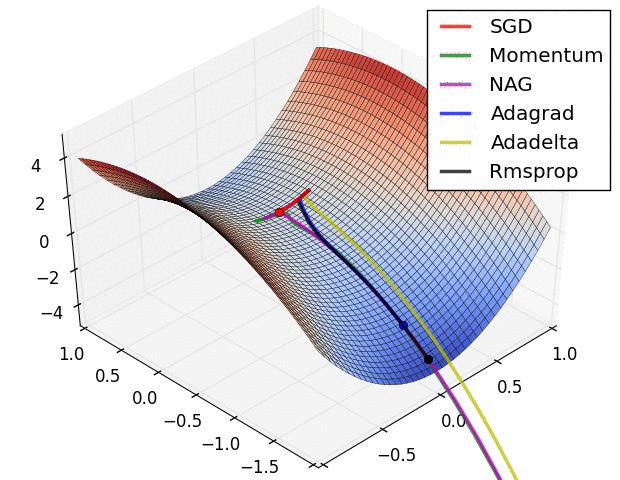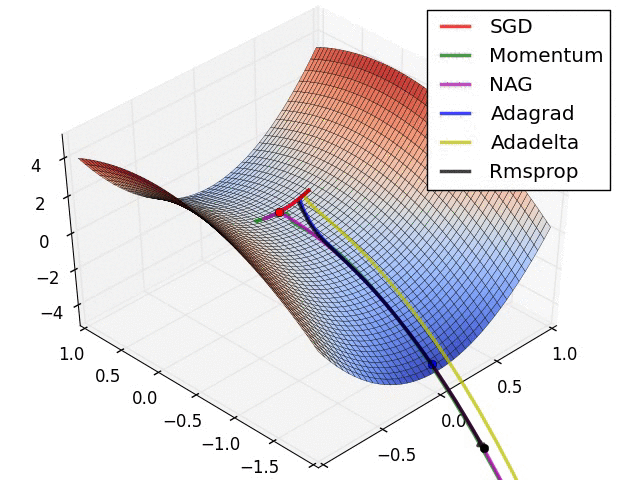 在鞍点处的比较
在鞍点处的比较
标签:变化 pos ilo data 影响 app change 本质 otto
原文地址:http://www.cnblogs.com/wuxiangli/p/7258510.html