标签:正则表达式
小编最近学习了新技能,利用这个技能,我能快速的找到自己想要的结果,是不是好神奇呢?  下面我就隆重介绍一下这个新技能,它就是Linux中的正则表达式。可能很多人都想问,正则表达式是什么呢?它就是由一类特殊字符及文本字符所编写的模式,我们可以通过这种模式对目标文本逐行进行匹配检查,从而可以看到匹配的行。简单的说,它就是一种过滤条件。因为正则表达式的内容非常之广,所以小编我呢就给大家介绍几种常用的正则表达式。
下面我就隆重介绍一下这个新技能,它就是Linux中的正则表达式。可能很多人都想问,正则表达式是什么呢?它就是由一类特殊字符及文本字符所编写的模式,我们可以通过这种模式对目标文本逐行进行匹配检查,从而可以看到匹配的行。简单的说,它就是一种过滤条件。因为正则表达式的内容非常之广,所以小编我呢就给大家介绍几种常用的正则表达式。
字符匹配:
(1). 匹配任意单个字符。 如图所示
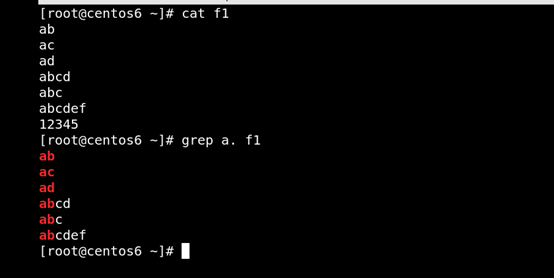
(2)[ ]匹配指定范围内的任意单个字符 如图所示:
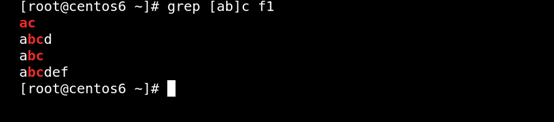
(3) [^] 匹配指定范围外的任意单个字符 如图所示:
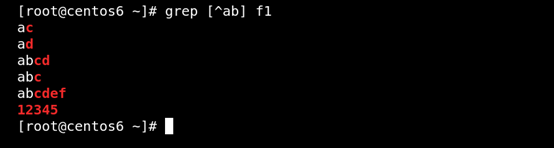
(4)[:alnum:]或[0-9a-zA-Z] 匹配字母和数字 如图所示:
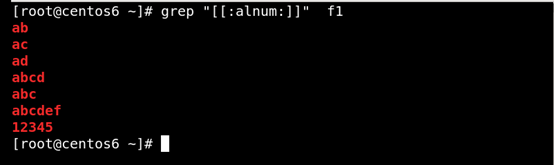
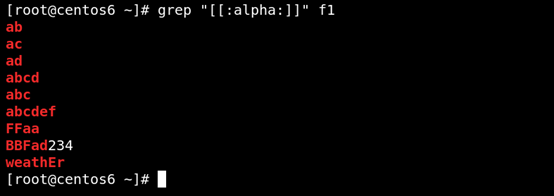
(5)[:alpha:]匹配任何英文大小写字符 如图所示:
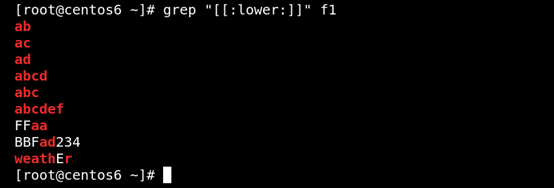
(6)[:lower:]匹配小写字母 如图所示:
(7)[:upper:]匹配大写字母 如图所示:

(8)[:digit:]匹配十进制数字 如图所示:

匹配次数:用在要指定次数的字符后面,用于指定前面的字符要出现的次数。
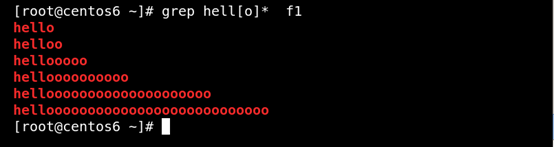
(1)* 匹配前面的字符任意次,包括0次 贪婪模式:
能尽可能长的匹配。如图所示:
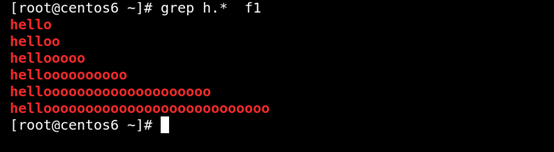
(2) .* 任意长度的任意字符 如图所示:
(3)\? 匹配前面的字符0或一次 如图所示:
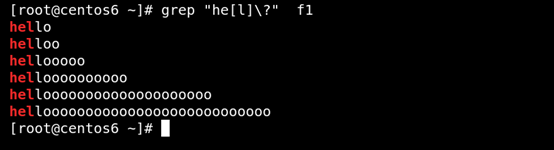
(4) \+ 匹配其前面的字符至少一次 如图所示:
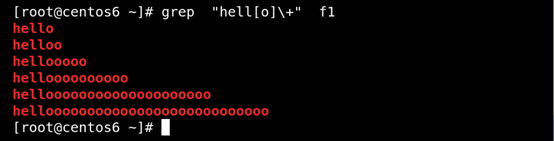
(5)\{n\} 匹配前面的字符n次 如图所示:

(6)\{m,n\} 匹配前面的字符至少m次,至多n次 如图所示:

(7)\{, n\} 匹配前面的字符至多n次 如图所示:
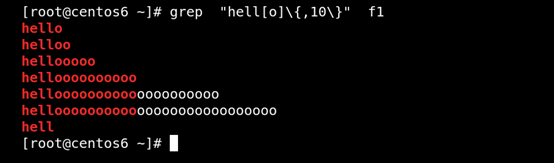
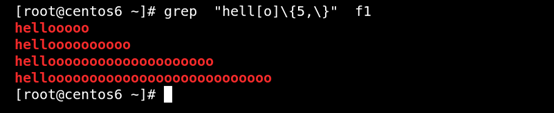
(8)\{n,\} 匹配前面的字符至少n次 如图所示:
位置锚定:定位出现的位置
(1)^ 行首锚定,用于模式的最左侧 如图所示:

(2)$ 行尾锚定,用于模式的最右侧 如图所示:
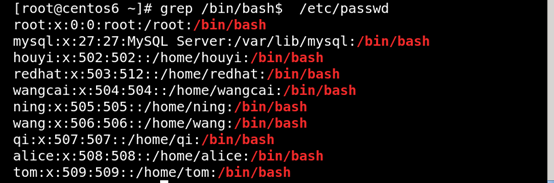
(3)^PATTERN$ 用于模式匹配整行 如图所示:

(4)\< 或\b 词首锚定,用于单词模式的左侧 如图所示:

(5)\>或\b 词尾锚定,用于单词模式的最右侧 如图所示:

(6)\<PATTERN\> 匹配整个单词 如图所示:

补充:这里也可以用 -w 如图所示 :

分组:\(\) 将一个或多个字符捆绑在一起,当作一个整体进行处理。分组括号中的模式匹配到的内容会被正则表达式引擎记录于内部的变量中,这些变量的命名方式为: \1, \2, \3 等。
\1 表示从左侧起第一个左括号以及与之匹配右括号之间的模式所匹配到的字符 如图所示:

或者:\| 如图所示:

补充:也可以用 grep -e 如图所示:

小编心得:想要熟练掌握正则表达式没有捷径,只有多练,只有练的多了,自然就会了。
标签:正则表达式
原文地址:http://13017865.blog.51cto.com/13007865/1952102