标签:upd over ref kotlin mkdir dir web selenium .config
对于QQ空间的数据一直来是垂涎不已,老早就想偷过来研究研究,这几天闲下来便开始动手。。。
整个程序的流程为:登录-->获取cookie-->获取所有的好友qq_number-->根据所有的好友qq遍历他们的说说-->get所有好友的说说数据
程序跑了20多分钟就跑完了,,共282好友,,跑了60000+说说
有些个人隐私我抹掉了。。甭介意。嘿嘿
1.登录-->获取cookie
打开http://i.qq.com/,如下图
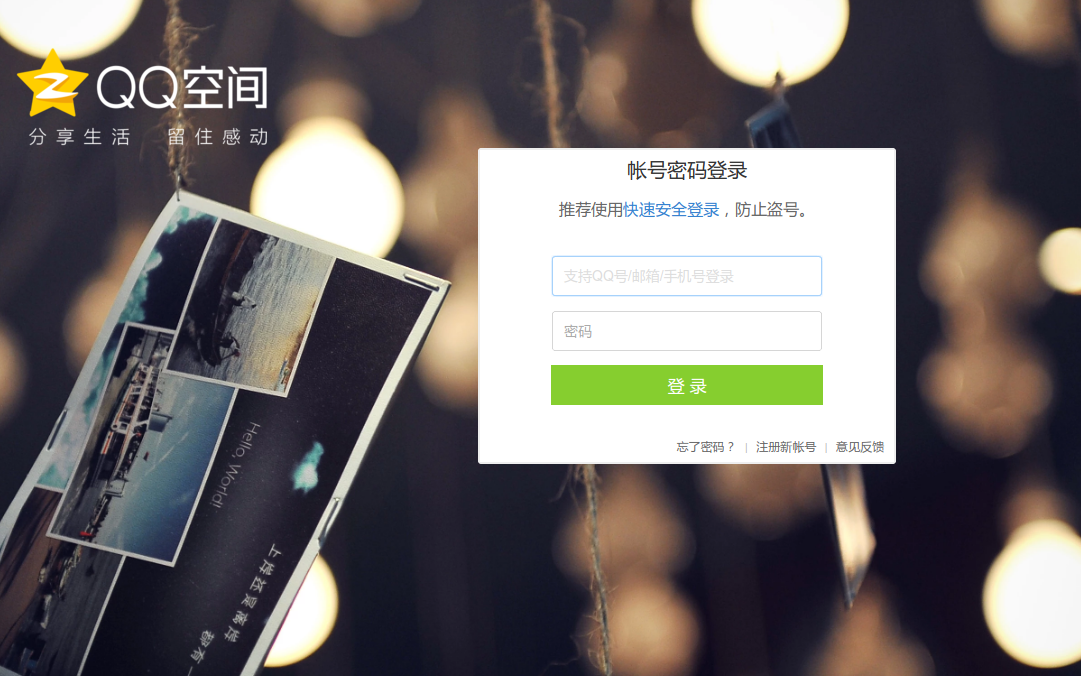
但大多数时候是这样的

我们这里使用账号密码登录,为了方便使用selenium自动化神器(关于selenium的用法可以参考https://my.oschina.net/u/3264690/blog/899229,这里不做过多阐述)
QQ账号,QQ密码存储在userinfo.ini文件中,然后用configparser将其读取出来
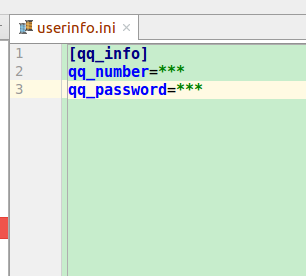
读取的代码如下
configparser是一个读取配置文件的库,这里读取的格式为get(‘[配置文件中括号里的值]‘,‘相对应的key值’)
import configparser
config = configparser.ConfigParser(allow_no_value=False)
config.read(‘userinfo.ini‘)
self.__username =config.get(‘qq_info‘,‘qq_number‘)
self.__password=config.get(‘qq_info‘,‘qq_password‘)用户信息读取出来后就可以登录了
有些盆友用selenium的时候,可能会发现有些元素定位不到,这是因为有些网页套了一个iFrame
selenium根据id定位到该iframe
self.web.switch_to_frame(‘login_frame‘)
自动登录且获取cookie的代码
def login(self):
self.web.switch_to_frame(‘login_frame‘)
log=self.web.find_element_by_id("switcher_plogin")
log.click()
time.sleep(1)
username=self.web.find_element_by_id(‘u‘)
username.send_keys(self.__username)
ps=self.web.find_element_by_id(‘p‘)
ps.send_keys(self.__password)
btn=self.web.find_element_by_id(‘login_button‘)
time.sleep(1)
btn.click()
time.sleep(2)
self.web.get(‘https://user.qzone.qq.com/{}‘.format(self.__username))
cookie=‘‘
for elem in self.web.get_cookies():
cookie+=elem["name"]+"="+ elem["value"]+";"
self.cookies=cookie
self.get_g_tk()
self.headers[‘Cookie‘]=self.cookies
self.web.quit()
2.获取所有好友的QQ_number
研究好久后发现在QQ空间主页中权限设置页面中,点击仅限QQ好友,会有下面这样的页面出来
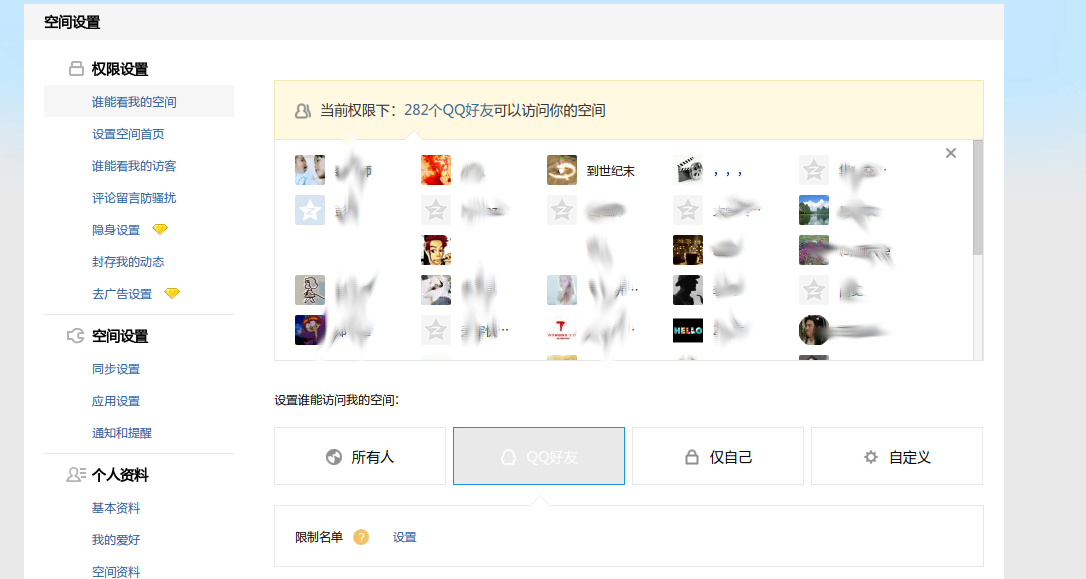
按F12后研究js文件发现有这样一个文件
这个js文件里有好友的qq_number
于是请求这个文件得到qq_number
def get_frends_url(self):
url=‘https://h5.qzone.qq.com/proxy/domain/base.qzone.qq.com/cgi-bin/right/get_entryuinlist.cgi?‘
params = {"uin": self.__username,
"fupdate": 1,
"action": 1,
"g_tk": self.g_tk}
url = url + parse.urlencode(params)
return url
def get_frends_num(self):
t=True
offset=0
url=self.get_frends_url()
while(t):
url_=url+‘&offset=‘+str(offset)
page=self.req.get(url=url_,headers=self.headers)
if "\"uinlist\":[]" in page.text:
t=False
else:
if not os.path.exists("./frends/"):
os.mkdir("frends/")
with open(‘./frends/‘+str(offset)+‘.json‘,‘w‘,encoding=‘utf-8‘) as w:
w.write(page.text)
offset += 50
这里有一个函数self.g_tk()它返回一个加密的p_skey , 在这个js文件中qzfl_v8_2.1.61.js,有这样一段代码
QZFL.pluginsDefine.getACSRFToken = function(url) {
url = QZFL.util.URI(url);
var skey;
if (url) {
if (url.host && url.host.indexOf("qzone.qq.com") > 0) {
try {
skey = parent.QZFL.cookie.get("p_skey");
} catch (err) {
skey = QZFL.cookie.get("p_skey");
}
} else {
if (url.host && url.host.indexOf("qq.com") > 0) {
skey = QZFL.cookie.get("skey");
}
}
}
if (!skey) {
skey = QZFL.cookie.get("p_skey") || (QZFL.cookie.get("skey") || (QZFL.cookie.get("rv2") || ""));
}
return arguments.callee._DJB(skey);
};
QZFL.pluginsDefine.getACSRFToken._DJB = function(str) {
var hash = 5381;
for (var i = 0, len = str.length;i < len;++i) {
hash += (hash << 5) + str.charCodeAt(i);
}
return hash & 2147483647;
};把它写成python版的如下
def get_g_tk(self):
p_skey = self.cookies[self.cookies.find(‘p_skey=‘)+7: self.cookies.find(‘;‘, self.cookies.find(‘p_skey=‘))]
h=5381
for i in p_skey:
h+=(h<<5)+ord(i)
print(‘g_tk‘,h&2147483647)
self.g_tk=h&2147483647
因为将好友信息存储为json文件,因此需要解析文件信息
#coding:utf-8
import json
import os
def get_Frends_list():
k = 0
file_list=[i for i in os.listdir(‘./frends/‘) if i.endswith(‘json‘)]
frends_list=[]
for f in file_list:
with open(‘./frends/{}‘.format(f),‘r‘,encoding=‘utf-8‘) as w:
data=w.read()[95:-5]
js=json.loads(data)
# print(js)
for i in js:
k+=1
frends_list.append(i)
return frends_list
frends_list=get_Frends_list()
print(frends_list)
3.获取所有好友说说
与之前类似,进入好友的说说主页后发现也有这样一个js文件将所有说说以json形式显示出来
![]()
类似的,写了获取说说的代码(经过测试,参数中的num最好写20,否则会出现未知的结果。。。)
def get_mood_url(self):
url=‘https://h5.qzone.qq.com/proxy/domain/taotao.qq.com/cgi-bin/emotion_cgi_msglist_v6?‘
params = {
"sort":0,
"start":0,
"num":20,
"cgi_host": "http://taotao.qq.com/cgi-bin/emotion_cgi_msglist_v6",
"replynum":100,
"callback":"_preloadCallback",
"code_version":1,
"inCharset": "utf-8",
"outCharset": "utf-8",
"notice": 0,
"format":"jsonp",
"need_private_comment":1,
"g_tk": self.g_tk
}
url = url + parse.urlencode(params)
return url
def get_mood_detail(self):
from getFrends import frends_list
url = self.get_mood_url()
for u in frends_list[245:]:
t = True
QQ_number=u[‘data‘]
url_ = url + ‘&uin=‘ + str(QQ_number)
pos = 0
while (t):
url__ = url_ + ‘&pos=‘ + str(pos)
mood_detail = self.req.get(url=url__, headers=self.headers)
print(QQ_number,u[‘label‘],pos)
if "\"msglist\":null" in mood_detail.text or "\"message\":\"对不起,主人设置了保密,您没有权限查看\"" in mood_detail.text:
t = False
else:
if not os.path.exists("./mood_detail/"):
os.mkdir("mood_detail/")
if not os.path.exists("./mood_detail/"+u[‘label‘]):
os.mkdir("mood_detail/"+u[‘label‘])
with open(‘./mood_detail/‘+u[‘label‘]+"/" +str(QQ_number)+"_"+ str(pos) + ‘.json‘, ‘w‘,encoding=‘utf-8‘) as w:
w.write(mood_detail.text)
pos += 20
time.sleep(2)将需要的说说数据存入数据库
#存入数据库
def dataToMysql():
con=pymysql.connect(
host=‘127.0.0.1‘,
user=‘root‘,
password="×××",
database=‘qq_z‘,
port=3306,
)
cur=con.cursor()
sql="insert into info (qq_number,created_time,content,commentlist,source_name,cmtnum,name) values ({},{},{},{},{},{},{});"
d=[i for i in os.listdir(‘mood_detail‘) if not i.endswith(‘.xls‘)]
for ii in d:
fl=[i for i in os.listdir(‘mood_detail/‘+ii) if i.endswith(‘.json‘)]
print(‘mood_detail/‘+ii)
k=1
for i in fl:
with open(‘mood_detail/‘+ii+"/"+i,‘r‘,encoding=‘latin-1‘) as w:
s=w.read()[17:-2]
js=json.loads(s)
print(i)
for s in js[‘msglist‘]:
m=-1
if not s[‘commentlist‘]:
s[‘commentlist‘]=list()
cur.execute(sql.format(int(i[:i.find(‘_‘)]),s[‘created_time‘],str(s[‘content‘]),str([(x[‘content‘],x[‘createTime2‘],x[‘name‘],x[‘uin‘]) for x in list(s[‘commentlist‘])]),str(s[‘source_name‘]),int(s[‘cmtnum‘]),str(s[‘name‘])))
k+=1
con.commit()
con.close()将需要的说说数据存入Excel
def dataToExcel():
d=[i for i in os.listdir(‘mood_detail‘) if not i.endswith(‘.xls‘)]
for ii in d:
wb=xlwt.Workbook()
sheet=wb.add_sheet(‘sheet1‘,cell_overwrite_ok=True)
sheet.write(0,0,‘content‘)
sheet.write(0,1,‘createTime‘)
sheet.write(0,2,‘commentlist‘)
sheet.write(0,3,‘source_name‘)
sheet.write(0,4,‘cmtnum‘)
fl=[i for i in os.listdir(‘mood_detail/‘+ii) if i.endswith(‘.json‘)]
print(‘mood_detail/‘+ii)
k=1
for i in fl:
with open(‘mood_detail/‘+ii+"/"+i,‘r‘,encoding=‘latin-1‘) as w:
s=w.read()[17:-2]
js=json.loads(s)
print(i)
for s in js[‘msglist‘]:
m=-1
sheet.write(k,m+1,str(s[‘content‘]))
sheet.write(k,m+2,str(s[‘createTime‘]))
if not s[‘commentlist‘]:
s[‘commentlist‘]=list()
sheet.write(k,m+3,str([(x[‘content‘],x[‘createTime2‘],x[‘name‘],x[‘uin‘]) for x in list(s[‘commentlist‘])]))
sheet.write(k,m+4,str(s[‘source_name‘]))
sheet.write(k,m+5,str(s[‘cmtnum‘]))
k+=1
if not os.path.exists(‘mood_detail/Excel/‘):
os.mkdir(‘mood_detail/Excel/‘)
try:
wb.save(‘mood_detail/Excel/‘+ii+‘.xls‘)
except Exception:
print("error")4.分析数据
24小时发布的说说数
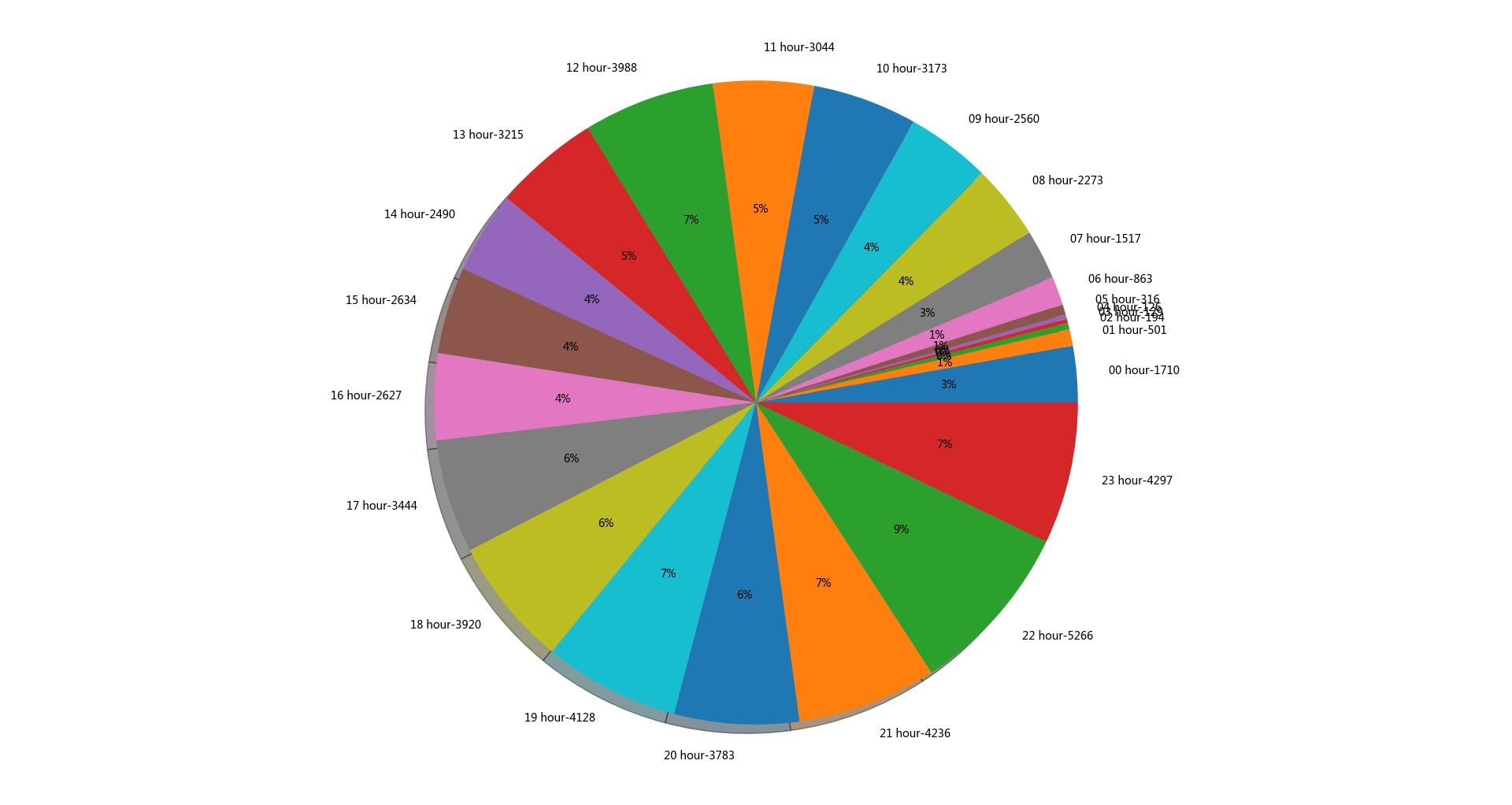
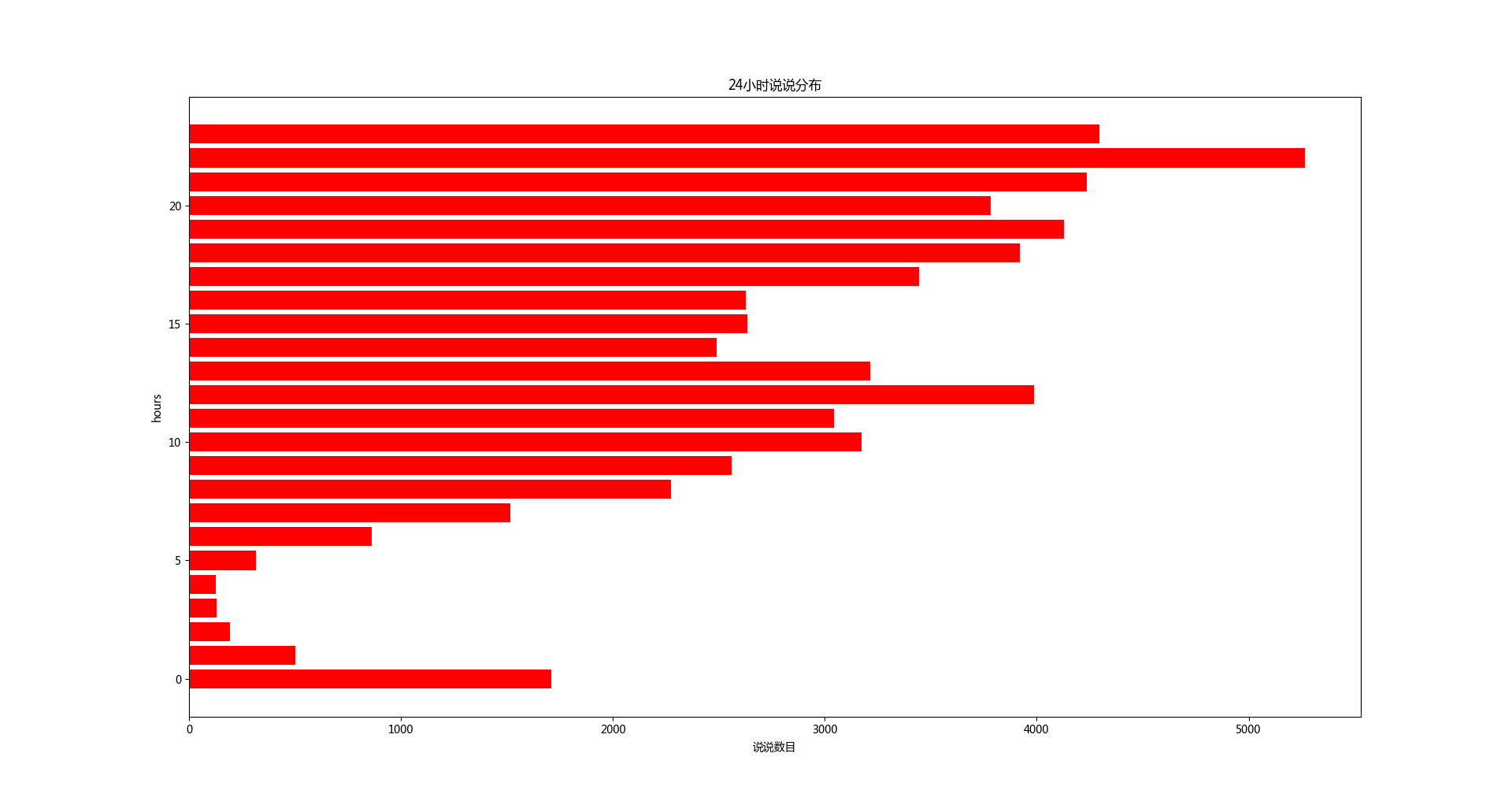
大家在中午和晚上发布的说说比较多,凌晨比较少
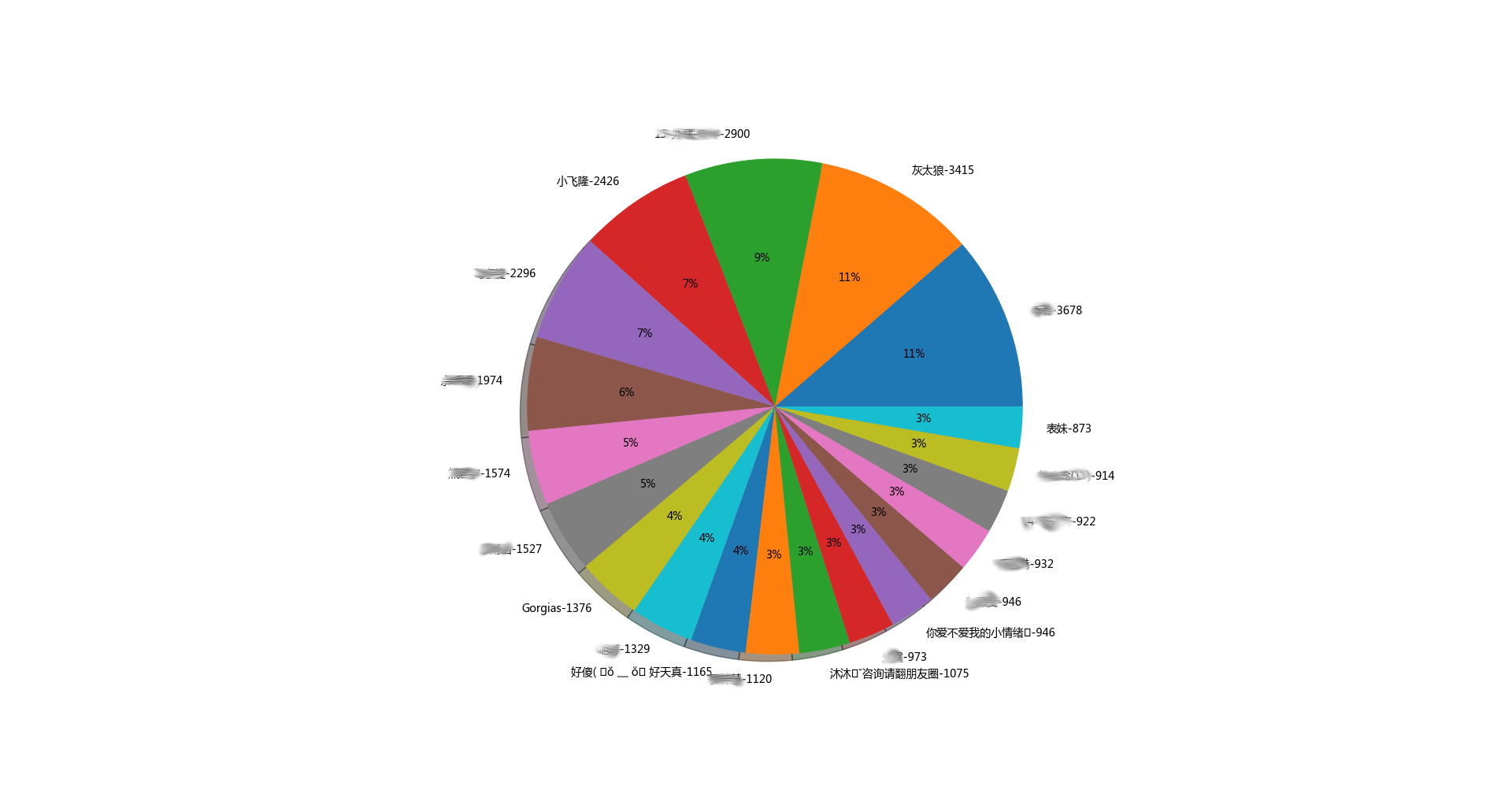
说说最多排行top20
说说最少排行top20
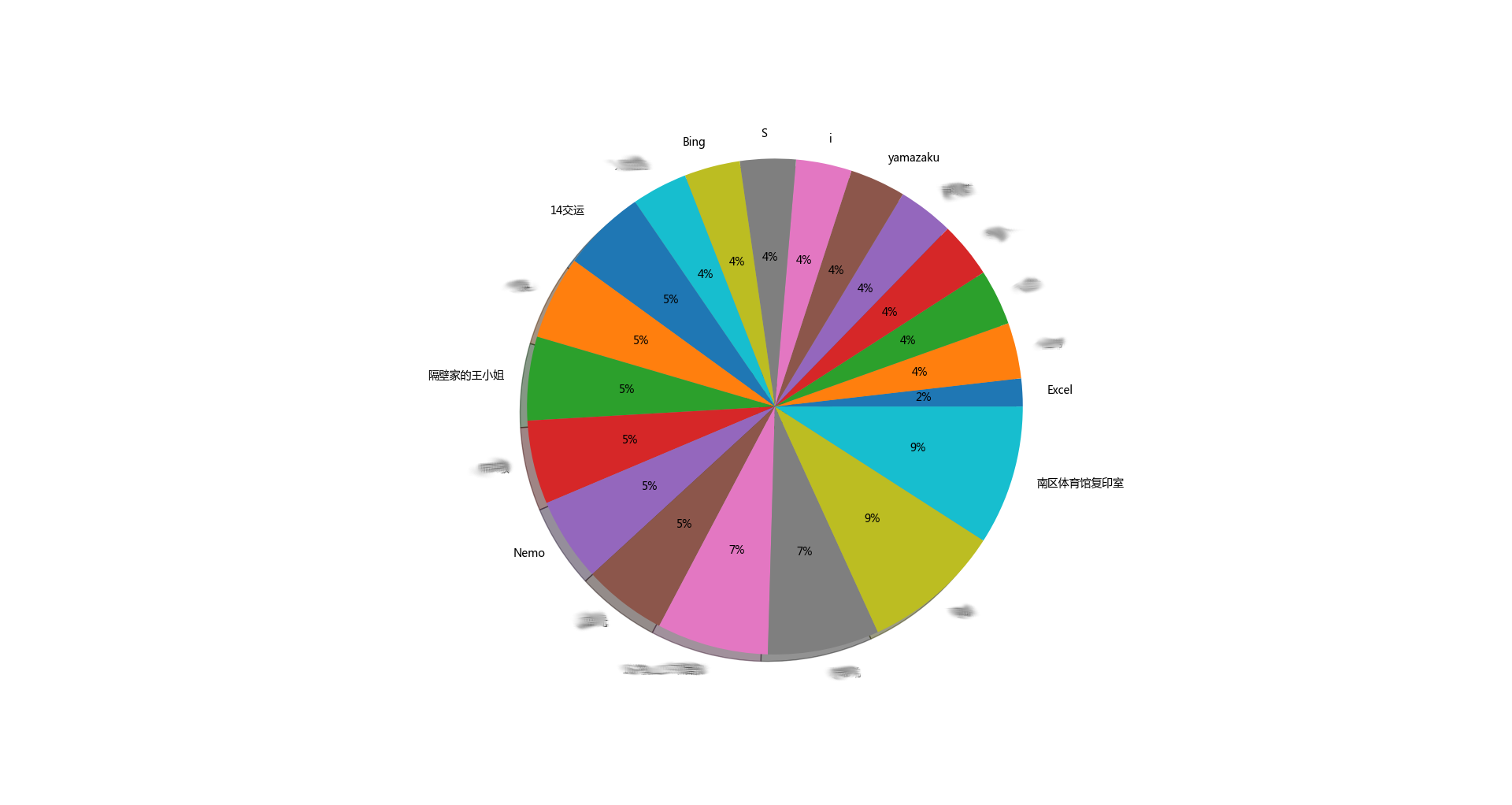
果然,,闷骚的人发的说说比较多。。。哈哈哈
从2000年到2018年,说说分布如下
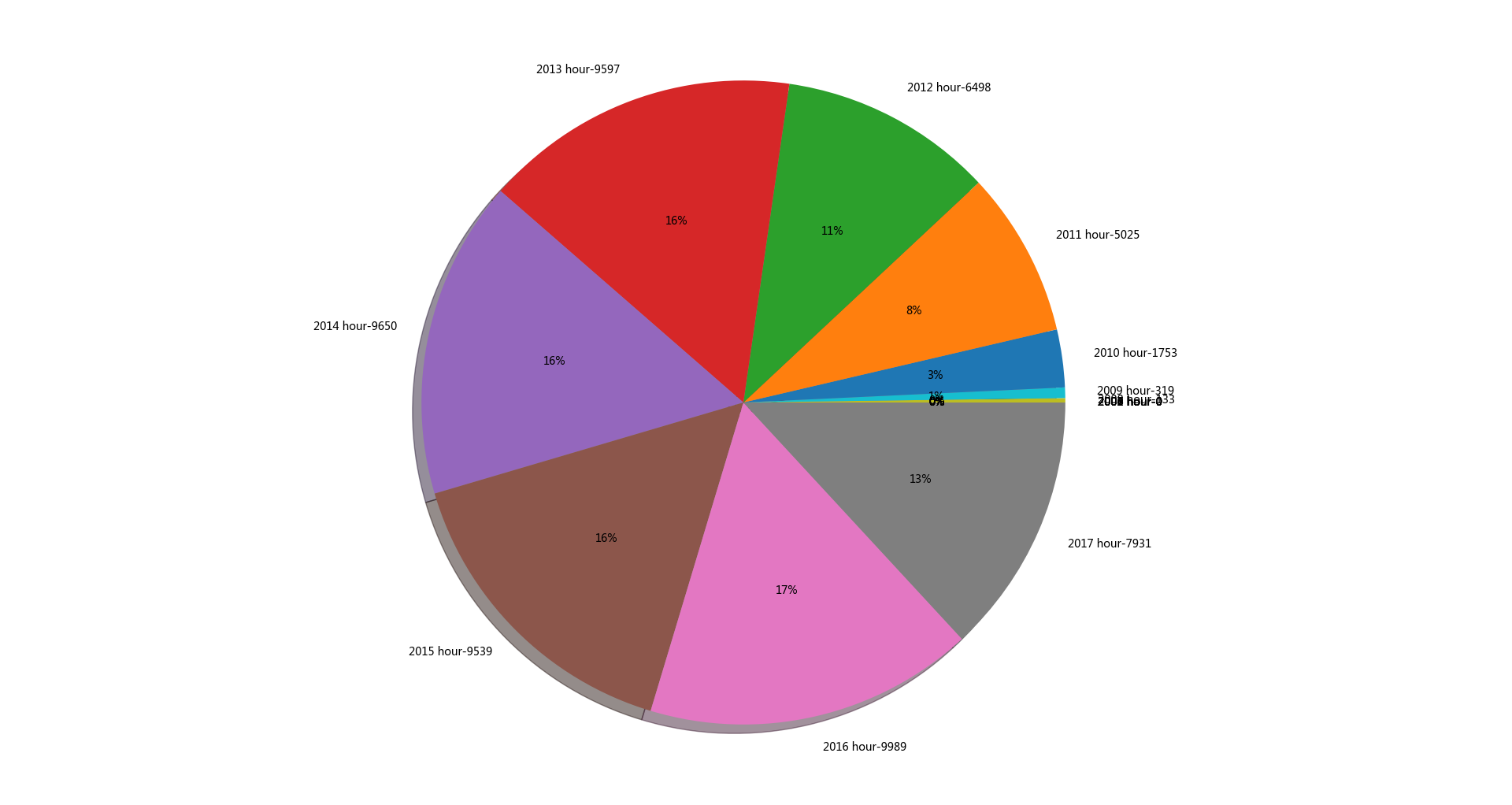
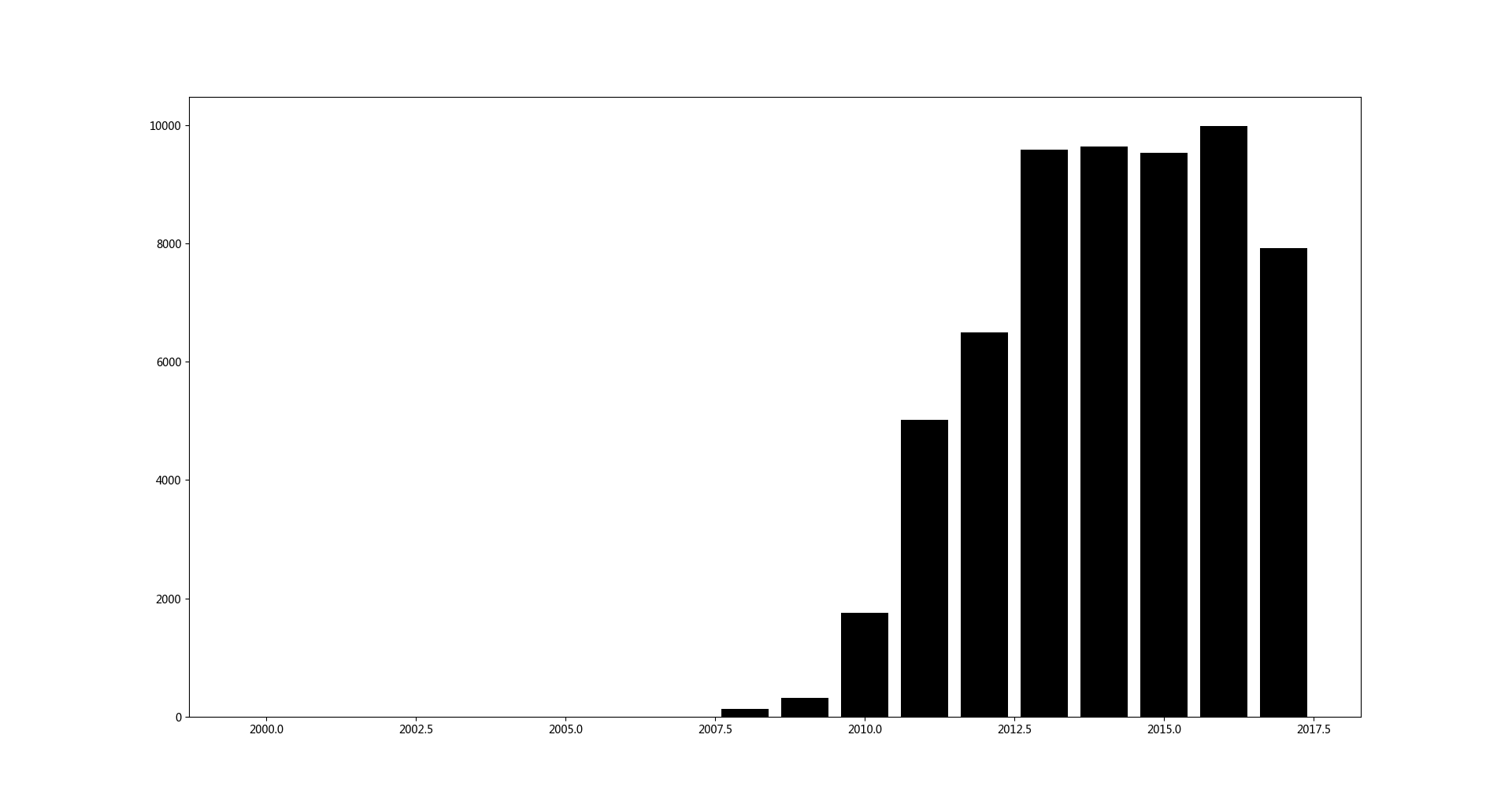
看来我的朋友们年轻的时候蛮闷骚,,随着年纪增大,,说说越来越少。。
感谢https://zhuanlan.zhihu.com/p/24656161给我的提示。。。少走了许多弯路
数据抓取速度贼快,,20分钟抓取了我所有好友(282+)60000+说说。。
项目已传到
朋友们,觉得有用来个star噢。。蟹蟹。。。
标签:upd over ref kotlin mkdir dir web selenium .config
原文地址:http://www.cnblogs.com/txjwd/p/7269508.html