标签:produce 训练 地方 big 获取 人工 替换 rect --
上次 踩坑日志之一 遗留的问题终于解决了,所以作者(也就是我)终于有脸出来写第二篇了。
首先还是贴上 卷积算法的示例代码地址 :https://github.com/tensorflow/models
这个库里面主要是一些常用的模型用tensorflow实现之后的代码。其中我用的是
models/tree/master/tutorials/image/cifar10 这个示例,上一篇也大致讲过了。
关于上次遇到问题是:
虽然训练了很多次,但是每次实际去用时都是相同的结果。这个问题主要原因是
在核心代码文件cifar10.py里
tf.app.flags.DEFINE_integer(‘batch_size‘, 128,
"""Number of images to process in a batch.""")
被我改成 batch_size =1
一开始我误以为这个batch要跟训练文件的.bin 文件里面的图片数量对应,其实不然。这个batch_size 是为了用
cifar10_input.py
images, label_batch = tf.train.batch(
[image, label],
batch_size=batch_size,
num_threads=num_preprocess_threads,
capacity=min_queue_examples + 3 * batch_size)
创建一个图片跟标签的队列,每个队列128个元素,便于分布式处理。
由于改成1之后可能是影响是训练效果。导致整体的loss很高,所以识别率很差。有待进一步验证。
另外一个原因很可能是最致命的
上一篇讲到label的对应方式是
# Create a queue that produces the filenames to read.
filename_queue = tf.train.string_input_producer(filenames)
label 也是用string_input_producer 做了另外一条字符串队列
因为label 是分类名称,也是图片所在文件夹的名称,所以我在外面把图片文件夹名称都丢到一个label的string队列里,然后里面做出队 depuqeue。
这其实是错误的,因为两条队列要完美保持一致,而且还不能加
shuffle 参数 这个参数可以随机获取图片文件,以便训练模型效果更具备泛化能力。
# Create a queue that produces the filenames to read.
filename_queue = tf.train.string_input_producer(filenames,name="filename_queue_hcq",shuffle=True)
shuffle=true 还是要加的。
label的获取方式就得另外想办法。
把 cifar10_input.py 方法 read_cifar10 改造如下:
def read_cifar10(filename_queue):
class CIFAR10Record(object):
pass
reader = tf.WholeFileReader()
key, value = reader.read(filename_queue)
image0 = tf.image.decode_jpeg(value,3)
esized_image = tf.image.resize_images(image0, [32, 32],
method=tf.image.ResizeMethod.AREA)
result = ImageNetRecord()
re2=splitfilenames(tf.constant( filenames),len(filenames))
key=splitfilenames(tf.reshape(key,[1],name="key_debug"),1)
label=diff(re2,key)
其中 splitilenames 方法是我新增的,主要是为了把文件所在目录的路劲切出来
def splitfilenames(inputs,allstringlen):
a = tf.string_split(inputs, "/\\")
bigin = tf.cast(tf.size(a.values) / allstringlen -2, tf.int32)
slitsinglelen = tf.cast(tf.size(a.values) / allstringlen, tf.int32)
val = tf.reshape(a.values, [allstringlen, slitsinglelen])
re2 = tf.cast(tf.slice(val, [0, bigin], [allstringlen, 1]),tf.string)
re2 =tf.reshape(re2,[allstringlen])
re2 =tf.unique(re2).y
return re2
比如”H:\imagenet\fortest\n01440764“ 切出来 “n01330764”。 这个方法是支持批量处理的。
之所以写的这么麻烦。是因为输入量是tensor,所以所有操作都必须按照tensorflow的api写。
diff方法 是为了判定key 的分类名在所有分类里面的位置。用这个位置作为label。
这里 读者估计有一个疑问
“为啥不直接用分类名‘n01330764’作为label标签去训练呢?”
这里也是迫于无奈,因为后续的代码有2个限制,1,label必须是int型,2label最大值不能大于分类总数。所以不能简单把“n”删除然后转成数字 1330764 。
虽然不太优雅,各位看官轻拍。
def diff(re2,key):
keys = tf.fill([tf.size(re2)],key[0])
numpoi= tf.cast(tf.equal(re2, keys),tf.int32)
numpoi=tf.argmax(numpoi)
return numpoi
好了,到止为止,train的代码就改完了,先训练一段时间。
cifar10_eval.py 这边需要改个地方。
if len(sys.argv)==1:
SinglePicPath = "/tmp/8.jpg"
else:
SinglePicPath =sys.argv[1]
通过参数传入 单图片的地址,用来执行识别程序。
先跑一下8.jpg

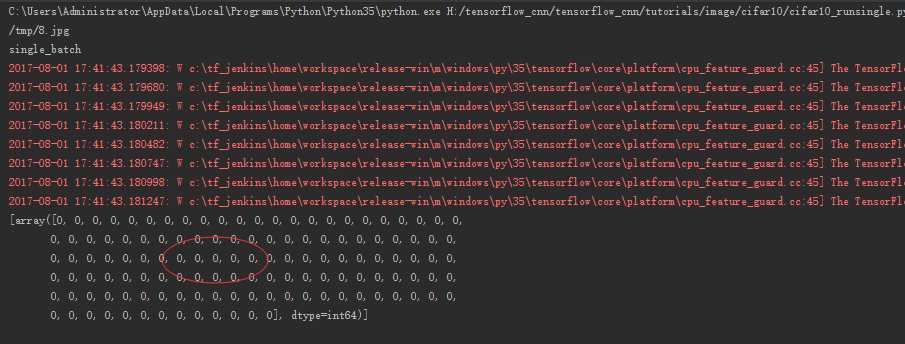
得出来结果是0 之所以有这么多,是因为batchsize=128 不过都是一样的。
然后我用C# MVC写了一个页面。用来上传图片,然后输出中文结果。
主要核心代码是:
Thumbnails.Of(file).ZoomMethod(Thumbnails.ThumbnailZoomMethod.CUT).Resize(32, 32).ToFiles(imagepath);
var p = new Process();
//C:\Users\Administrator\AppData\Local\Programs\Python\Python35\python.exe
p.StartInfo.FileName = @"C:\Users\Administrator\AppData\Local\Programs\Python\Python35\python.exe";
p.StartInfo.Arguments = @"H:\tensorflow_cnn\tensorflow_cnn\tutorials\image\cifar10\cifar10_runsingle.py " + imagepath;
p.StartInfo.WorkingDirectory = @"H:\";
p.StartInfo.RedirectStandardOutput = true;
p.StartInfo.RedirectStandardError = true;
p.StartInfo.UseShellExecute = false;
p.Start();
string output = p.StandardOutput.ReadToEnd();
string errmsg = p.StandardError.ReadToEnd();
p.WaitForExit();
p.Close();
var num = Regex.Replace(output, @".*\[array\(\[(\d+),.*\].*", "$1", RegexOptions.Singleline);
string result;
主要是把图片改为 32*32 然后用Process 拉起python 去执行 cifar10_runsingle.py (这个是cifar10_eval.py 改造后的)。
然后用正则把 结果的数字切出来。
剩下就是把位置比如 0替换成“n01330764”
“n01330764” 再替换成中文,上一篇有下载中文的链接。
测试一下
------------------------------------------
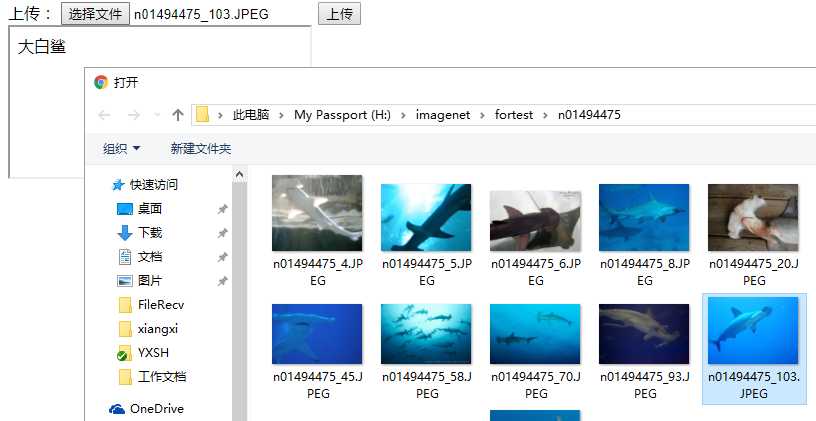
--------------------------------------
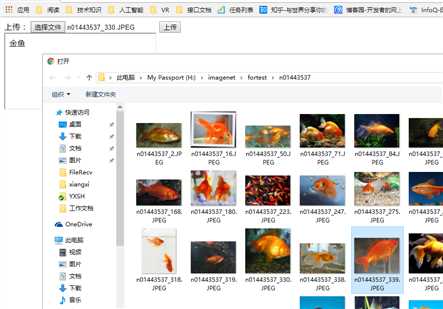
-------------------
因为把eval改成执行代码了,所以eval 测试集反而没应用上了。不能判断识别率高低了。这是下一步要改造的地方。
不过imagenet 的数量级太大,正正经经训练一次,估计要很久很久很久。
另外还要切换成GPU模式,估计不太难。有教程。
期待踩坑日志之三吧,烧年们。
另外说一点关于tensorboard的,这东西真是厉害。安装方便。直接命令行 pip tensorboard
然后

logdir 指向
wt = tf.summary.FileWriter("/tmp/broaddata3")
代码中设置的 summary的地址。
然后打开浏览器查看。
这里有个坑需要注意, tensorboard的运行盘符必须跟log所在盘符一致,否则一直提示拿不到文件。
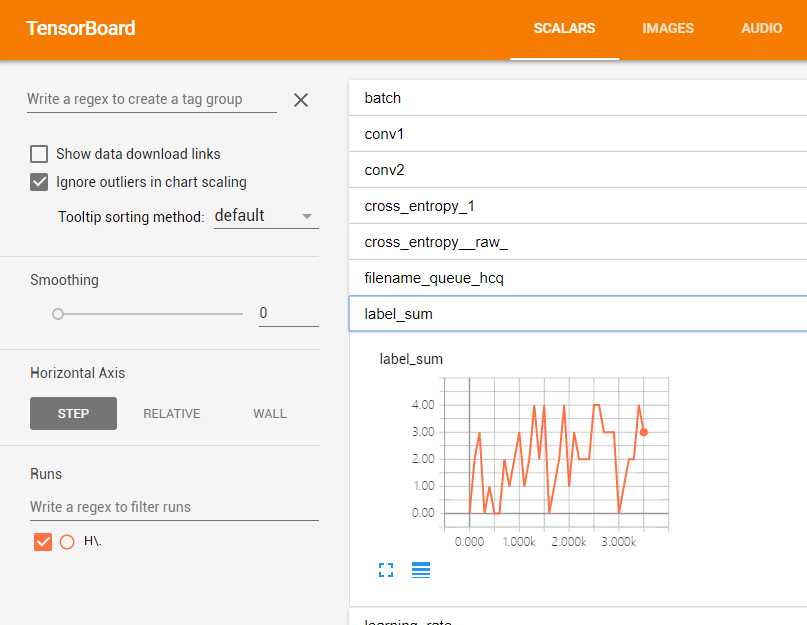
这里可以看到我新增了一个label_sum 的曲线图,可以看到确实拿到不同的label了,而且最小是从0开始的。
此致敬礼。
标签:produce 训练 地方 big 获取 人工 替换 rect --
原文地址:http://www.cnblogs.com/7rhythm/p/7270207.html