标签:art daemon rbac 字段 对象存储 mmu contain nec property
· 概况
· 手工搭建集群
· 引言
· 安装Scala
· 配置文件
· 启动与测试
· 应用部署
· 部署架构
· 应用程序部署
· 核心原理
· RDD概念
· RDD核心组成
· RDD依赖关系
· DAG图
· 应用程序资源构建
· API
· RDD构建
· RDD分区数
· 共享变量
· DoubleRDDFunctions常用Operation
· PairRDDFunctions间操作Operation
· OrderedRDDFunctions常用Operation
· 数据准备
· 加载&预处理
· 统计DAU
· 统计MAU
1. Spark相对MapReduce的优势:
a) 支持迭代计算;
b) 中间结果存储在内存而不是硬盘,降低延迟。
2. Spark已成为轻量级大数据快速处理统一平台,“One stack to rule them all”,一个平台完成:即席查询(ad-hoc queries)、批处理(batch processing)、流式处理(stream processing)。

3. Spark集群搭建方式:
a) 集成部署工具,如Cloudera Manager;
b) 手工搭建。
4. Spark源码编译方式:
a) SBT编译;
b) Maven编译。
1. 环境:
|
Role |
Host name |
|
Master |
centos1 |
|
Slave |
centos2 |
|
centos3 |
2. Standalone模式需在Master和Slave节点部署,YARN模式仅需在命令提交机器部署。
3. 假设已成功安装JDK、Hadoop集群。
1. [Master(Standalone模式)或命令提交机器(YARN模式)]安装Scala到/opt/app目录下。
tar zxvf scala-2.10.6.tgz -C /opt/app
2. [Master(Standalone模式)或命令提交机器(YARN模式)]配置环境变量。
vi /etc/profile
export SCALA_HOME=/opt/app/scala-2.10.6
export PATH=$SCALA_HOME/bin:$PATH
source /etc/profile # 生效 env | grep SCALA_HOME # 验证
3. [Master(Standalone模式)或命令提交机器(YARN模式)]
tar zxvf spark-1.6.3-bin-hadoop2.6.tgz -C /opt/app cd /opt/app/spark-1.6.3-bin-hadoop2.6/conf cp spark-env.sh.template spark-env.sh vi spark-env.sh
export JAVA_HOME=/opt/app/jdk1.8.0_121 export SCALA_HOME=/opt/app/scala-2.10.6 export HADOOP_HOME=/opt/app/hadoop-2.6.5 export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop export YARN_CONF_DIR=${HADOOP_HOME}/etc/hadoop # For standalone mode export SPARK_WORKER_CORES=1 export SPARK_DAEMON_MEMORY=512m
cp spark-defaults.conf.template spark-defaults.conf hadoop fs -mkdir /spark.eventLog.dir vi spark-defaults.conf
spark.driver.extraClassPath /opt/app/apache-hive-1.2.2-bin/lib/mysql-connector-java-5.1.22-bin.jar spark.eventLog.enabled true spark.eventLog.dir hdfs://centos1:9000/spark.eventLog.dir
cp slaves.template slaves vi slaves
centos2
centos3
ln -s /opt/app/apache-hive-1.2.2-bin/conf/hive-site.xml .
4. [Master(Standalone模式)]从Master复制Spark目录到各Slave。注意:仅Standalone集群需要执行本步骤。
scp -r /opt/app/spark-1.6.3-bin-hadoop2.6 hadoop@centos2:/opt/app scp -r /opt/app/spark-1.6.3-bin-hadoop2.6 hadoop@centos3:/opt/app
5. [Master(Standalone模式)或命令提交机器(YARN模式)]配置Spark环境变量。
export SPARK_HOME=/opt/app/spark-1.6.3-bin-hadoop2.6 export PATH=$PATH:$SPARK_HOME/bin
6. [Master(Standalone模式)]启动Spark,测试。
sbin/start-all.sh jps
Master # Master机器进程
Worker # Slave机器进程
7. [Master(Standalone模式)或命令提交机器(YARN模式)]测试。
bin/spark-submit --master spark://centos1:7077 --deploy-mode client --class org.apache.spark.examples.SparkPi --driver-memory 512m --executor-memory 512m --num-executors 1 --executor-cores 1 lib/spark-examples-1.6.3-hadoop2.6.0.jar # Standalone Client模式运行 bin/spark-submit --master spark://centos1:7077 --deploy-mode cluster --class org.apache.spark.examples.SparkPi --driver-memory 512m --executor-memory 512m --num-executors 1 --executor-cores 1 lib/spark-examples-1.6.3-hadoop2.6.0.jar # Standalone Cluster模式运行 bin/spark-submit --master yarn-client --class org.apache.spark.examples.SparkPi --driver-memory 512m --executor-memory 512m --num-executors 1 --executor-cores 1 lib/spark-examples-1.6.3-hadoop2.6.0.jar # Yarn Client模式运行 bin/spark-submit --master yarn-cluster --class org.apache.spark.examples.SparkPi --driver-memory 512m --executor-memory 512m --num-executors 1 --executor-cores 1 lib/spark-examples-1.6.3-hadoop2.6.0.jar # Yarn Custer模式运行
bin/yarn application -list # 查看YARN运行的应用 bin/yarn application -kill ApplicationID # 杀死YARN运行的应用
bin/spark-shell --master spark://centos1:7077 --deploy-mode client --driver-memory 512m --executor-memory 512m --num-executors 1 --executor-cores 1 # Standalone Client模式运行 bin/spark-shell --master yarn --deploy-mode client --driver-memory 512m --executor-memory 512m --num-executors 1 --executor-cores 1 # Yarn Client模式运行
8. 监控页面。
|
http://centos1:8080 |
Spark监控 |
|
http://centos1:8088 |
YARN监控 |
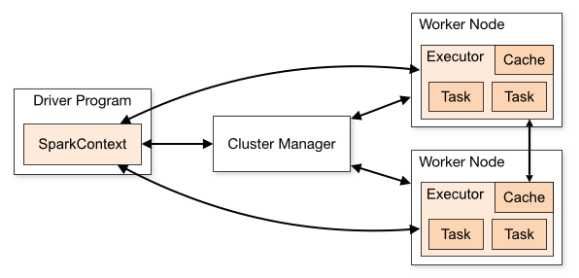
1. Application:Spark应用程序,包括一个Driver Program和集群中多个WorkNode中的Executor,其中每个WorkNode为每个Application仅提供一个Executor。
2. Driver Program:运行Application的main函数。通常也用SparkContext表示。负责DAG构建、Stage划分、Task管理及调度、生成SchedulerBackend用于Akka通信,主要组件有DAGScheduler、TaskScheduler、SchedulerBackend。
3. Cluster Manager:集群管理器,可封装如Spark Standalone、YARN等不同集群管理器。Driver Program通过Cluster Manager分配资源,并将任务发送到多个Work Node执行。
4. WorkNode:集群节点。应用程序在运行时的Task在WorkNode的Executor中执行。
5. Executor:WorkNode为Application启动的一个进程,负责执行Task。
6. Stage:一个Applicatoin一般包含一到多个Stage。
7. Task:被Driver Program发送到Executor的计算单元,通常一个Task处理一个split(即一个分区),每个split一般是一个Block大小。一个Stage包含一到多个Task,通过多个Task实现并行计算。
8. DAGScheduler:将Application分解成一到多个Stage,每个Stage根据RDD分区数决定Task个数,然后生成相应TaskSet放到TaskScheduler中。
9. DeployMode:Driver进程部署模式,有cluster和client两种。
10. 注意:
a) Driver Program必须与Spark集群处于同一网络环境。因为SparkContext要发送任务给不同WorkNode的Executor并接受Executor的执行结果。
b) 生产环境中,Driver Program所在机器性能配置,尤其CPU较好。
1. 分类:
a) spark-shell:交互式,用于开发调试。已创建好“val sc: SparkContext”和“val sqlContext: SQLContext”实例。
b) spark-submit:应用提交式,用于生产部署。
2. spark-shell参数:
bin/spark-shell --help
Usage: ./bin/spark-shell [options] Options: --master MASTER_URL spark://host:port, mesos://host:port, yarn, or local. --deploy-mode DEPLOY_MODE Whether to launch the driver program locally ("client") or on one of the worker machines inside the cluster ("cluster") (Default: client). --class CLASS_NAME Your application‘s main class (for Java / Scala apps). --name NAME A name of your application. --jars JARS Comma-separated list of local jars to include on the driver and executor classpaths. --packages Comma-separated list of maven coordinates of jars to include on the driver and executor classpaths. Will search the local maven repo, then maven central and any additional remote repositories given by --repositories. The format for the coordinates should be groupId:artifactId:version. --exclude-packages Comma-separated list of groupId:artifactId, to exclude while resolving the dependencies provided in --packages to avoid dependency conflicts. --repositories Comma-separated list of additional remote repositories to search for the maven coordinates given with --packages. --py-files PY_FILES Comma-separated list of .zip, .egg, or .py files to place on the PYTHONPATH for Python apps. --files FILES Comma-separated list of files to be placed in the working directory of each executor. --conf PROP=VALUE Arbitrary Spark configuration property. --properties-file FILE Path to a file from which to load extra properties. If not specified, this will look for conf/spark-defaults.conf. --driver-memory MEM Memory for driver (e.g. 1000M, 2G) (Default: 1024M). --driver-java-options Extra Java options to pass to the driver. --driver-library-path Extra library path entries to pass to the driver. --driver-class-path Extra class path entries to pass to the driver. Note that jars added with --jars are automatically included in the classpath. --executor-memory MEM Memory per executor (e.g. 1000M, 2G) (Default: 1G). --proxy-user NAME User to impersonate when submitting the application. --help, -h Show this help message and exit --verbose, -v Print additional debug output --version, Print the version of current Spark Spark standalone with cluster deploy mode only: --driver-cores NUM Cores for driver (Default: 1). Spark standalone or Mesos with cluster deploy mode only: --supervise If given, restarts the driver on failure. --kill SUBMISSION_ID If given, kills the driver specified. --status SUBMISSION_ID If given, requests the status of the driver specified. Spark standalone and Mesos only: --total-executor-cores NUM Total cores for all executors. Spark standalone and YARN only: --executor-cores NUM Number of cores per executor. (Default: 1 in YARN mode, or all available cores on the worker in standalone mode) YARN-only: --driver-cores NUM Number of cores used by the driver, only in cluster mode (Default: 1). --queue QUEUE_NAME The YARN queue to submit to (Default: "default"). --num-executors NUM Number of executors to launch (Default: 2). --archives ARCHIVES Comma separated list of archives to be extracted into the working directory of each executor. --principal PRINCIPAL Principal to be used to login to KDC, while running on secure HDFS. --keytab KEYTAB The full path to the file that contains the keytab for the principal specified above. This keytab will be copied to the node running the Application Master via the Secure Distributed Cache, for renewing the login tickets and the delegation tokens periodically.
3. spark-submit参数(除Usage外,其他参数与spark-shell一样):
bin/spark-submit --help
Usage: spark-submit [options] <app jar | python file> [app arguments] Usage: spark-submit --kill [submission ID] --master [spark://...] Usage: spark-submit --status [submission ID] --master [spark://...] Options: --master MASTER_URL spark://host:port, mesos://host:port, yarn, or local. --deploy-mode DEPLOY_MODE Whether to launch the driver program locally ("client") or on one of the worker machines inside the cluster ("cluster") (Default: client). --class CLASS_NAME Your application‘s main class (for Java / Scala apps). --name NAME A name of your application. --jars JARS Comma-separated list of local jars to include on the driver and executor classpaths. --packages Comma-separated list of maven coordinates of jars to include on the driver and executor classpaths. Will search the local maven repo, then maven central and any additional remote repositories given by --repositories. The format for the coordinates should be groupId:artifactId:version. --exclude-packages Comma-separated list of groupId:artifactId, to exclude while resolving the dependencies provided in --packages to avoid dependency conflicts. --repositories Comma-separated list of additional remote repositories to search for the maven coordinates given with --packages. --py-files PY_FILES Comma-separated list of .zip, .egg, or .py files to place on the PYTHONPATH for Python apps. --files FILES Comma-separated list of files to be placed in the working directory of each executor. --conf PROP=VALUE Arbitrary Spark configuration property. --properties-file FILE Path to a file from which to load extra properties. If not specified, this will look for conf/spark-defaults.conf. --driver-memory MEM Memory for driver (e.g. 1000M, 2G) (Default: 1024M). --driver-java-options Extra Java options to pass to the driver. --driver-library-path Extra library path entries to pass to the driver. --driver-class-path Extra class path entries to pass to the driver. Note that jars added with --jars are automatically included in the classpath. --executor-memory MEM Memory per executor (e.g. 1000M, 2G) (Default: 1G). --proxy-user NAME User to impersonate when submitting the application. --help, -h Show this help message and exit --verbose, -v Print additional debug output --version, Print the version of current Spark Spark standalone with cluster deploy mode only: --driver-cores NUM Cores for driver (Default: 1). Spark standalone or Mesos with cluster deploy mode only: --supervise If given, restarts the driver on failure. --kill SUBMISSION_ID If given, kills the driver specified. --status SUBMISSION_ID If given, requests the status of the driver specified. Spark standalone and Mesos only: --total-executor-cores NUM Total cores for all executors. Spark standalone and YARN only: --executor-cores NUM Number of cores per executor. (Default: 1 in YARN mode, or all available cores on the worker in standalone mode) YARN-only: --driver-cores NUM Number of cores used by the driver, only in cluster mode (Default: 1). --queue QUEUE_NAME The YARN queue to submit to (Default: "default"). --num-executors NUM Number of executors to launch (Default: 2). --archives ARCHIVES Comma separated list of archives to be extracted into the working directory of each executor. --principal PRINCIPAL Principal to be used to login to KDC, while running on secure HDFS. --keytab KEYTAB The full path to the file that contains the keytab for the principal specified above. This keytab will be copied to the node running the Application Master via the Secure Distributed Cache, for renewing the login tickets and the delegation tokens periodically.
4. 默认参数:
a) 默认应用程序参数配置文件:conf/spark-defaults.conf
b) 默认JVM参数配置文件:conf/spark-env.sh
c) 常用的jar文件可通过“--jar”参数配置。
5. 参数优先级(由高到低):
a) SparkConf显示配置参数;
b) spark-submit指定参数;
c) conf/spark-defaults.conf配置文件参数。
6. MASTER_URL格式
|
MASTER_URL |
说明 |
|
local |
以单线程在本地运行(完全无并行) |
|
local[K] |
在本地以K个Worker线程运行,K设置为CPU核数较理想 |
|
local[*] |
K=CPU核数 |
|
spark://HOST:PORT |
连接Standalone集群的Master,即Spark监控页面的URL,端口默认为7077(不支持省略) |
|
yarn-client |
以client模式连接到YARN集群,通过HADOOP_CONF_DIR环境变量查找集群 |
|
yarn-cluster |
以cluster模式连接到YARN集群,通过HADOOP_CONF_DIR环境变量查找集群 |
7. 注意:
a) spark-shell默认使用4040端口,当4040端口被占用时,程序打印日志警告WARN并尝试递增端口(4041、4042……)直到找到可用端口为止。
b) Executor节点上每个Driver Program的jar包和文件会被复制到工作目录下,可能占用大量空间。YARN集群会自动清除,Standalone集群需配置“spark.worker.cleanup.appDataTtl”开启自动清除。
8. 应用程序模板
import org.apache.spark.SparkConf import org.apache.spark.SparkContext import org.apache.spark.sql.SQLContext import org.apache.spark.sql.hive.HiveContext object Test { def main(args: Array[String]): Unit = { val conf = new SparkConf().setAppName("Test") val sc = new SparkContext(conf) // ... } }
9. 提交示例:
bin/spark-submit --master spark://ubuntu1:7077 --class org.apache.spark.examples.SparkPi lib/spark-examples-1.6.3-hadoop2.6.0.jar
1. RDD:Resilient Distributed Dataset,弹性分布式数据集。
2. 意义:Spark最核心的抽象概念;具有容错性基于内存的集群计算方法。
1. 5个核心方法。
a) getPartitions:分区列表(数据块列表)
b) compute:计算各分区数据的函数。
c) getDependencies:对父RDD的依赖列表。
d) partitioner:key-value RDD的分区器。
e) getPreferredLocations:每个分区的预定义地址列表(如HDFS上的数据块地址)。
2. 按用途分类以上5个方法:
a) 前3个:描述RDD间的血统关系(Lineage),必须有的方法;
b) 后2个:用于优化执行。
3. RDD的实例:RDD[T],T为泛型,即实例。
4. 分区:
a) 分区概念:将大数据量T实例集合split成多个小数据量的T实例子集合。
b) 分区源码:实际上是Iterator[T]。
c) 分区存储:例如以Block方式存在HDFS。
5. 依赖:
a) 依赖列表:一个RDD可有多个父依赖,所以是父RDD依赖列表。
b) 与分区关系:依赖是通过RDD分区间的依赖体现的,通过依赖列表和getPartitions方法可知RDD各分区是如何依赖一组父RDD分区的。
6. compute方法:
a) 延时(lazy)特性,当触发Action时才真正执行compute方法;
b) 计算粒度是分区,而不是T元素。
7. partitioner方法:T实例为key-value对类型的RDD。
8. RDD抽象类源码(节选自v1.6.3):
1 package org.apache.spark.rdd 2 3 // … 4 5 /** 6 * A Resilient Distributed Dataset (RDD), the basic abstraction in Spark. Represents an immutable, 7 * partitioned collection of elements that can be operated on in parallel. This class contains the 8 * basic operations available on all RDDs, such as `map`, `filter`, and `persist`. In addition, 9 * [[org.apache.spark.rdd.PairRDDFunctions]] contains operations available only on RDDs of key-value 10 * pairs, such as `groupByKey` and `join`; 11 * [[org.apache.spark.rdd.DoubleRDDFunctions]] contains operations available only on RDDs of 12 * Doubles; and 13 * [[org.apache.spark.rdd.SequenceFileRDDFunctions]] contains operations available on RDDs that 14 * can be saved as SequenceFiles. 15 * All operations are automatically available on any RDD of the right type (e.g. RDD[(Int, Int)] 16 * through implicit. 17 * 18 * Internally, each RDD is characterized by five main properties: 19 * 20 * - A list of partitions 21 * - A function for computing each split 22 * - A list of dependencies on other RDDs 23 * - Optionally, a Partitioner for key-value RDDs (e.g. to say that the RDD is hash-partitioned) 24 * - Optionally, a list of preferred locations to compute each split on (e.g. block locations for 25 * an HDFS file) 26 * 27 * All of the scheduling and execution in Spark is done based on these methods, allowing each RDD 28 * to implement its own way of computing itself. Indeed, users can implement custom RDDs (e.g. for 29 * reading data from a new storage system) by overriding these functions. Please refer to the 30 * [[http://www.cs.berkeley.edu/~matei/papers/2012/nsdi_spark.pdf Spark paper]] for more details 31 * on RDD internals. 32 */ 33 abstract class RDD[T: ClassTag]( 34 @transient private var _sc: SparkContext, 35 @transient private var deps: Seq[Dependency[_]] 36 ) extends Serializable with Logging { 37 // ... 38 39 // ======================================================================= 40 // Methods that should be implemented by subclasses of RDD 41 // ======================================================================= 42 43 /** 44 * :: DeveloperApi :: 45 * Implemented by subclasses to compute a given partition. 46 */ 47 @DeveloperApi 48 def compute(split: Partition, context: TaskContext): Iterator[T] 49 50 /** 51 * Implemented by subclasses to return the set of partitions in this RDD. This method will only 52 * be called once, so it is safe to implement a time-consuming computation in it. 53 */ 54 protected def getPartitions: Array[Partition] 55 56 /** 57 * Implemented by subclasses to return how this RDD depends on parent RDDs. This method will only 58 * be called once, so it is safe to implement a time-consuming computation in it. 59 */ 60 protected def getDependencies: Seq[Dependency[_]] = deps 61 62 /** 63 * Optionally overridden by subclasses to specify placement preferences. 64 */ 65 protected def getPreferredLocations(split: Partition): Seq[String] = Nil 66 67 /** Optionally overridden by subclasses to specify how they are partitioned. */ 68 @transient val partitioner: Option[Partitioner] = None 69 70 // ... 71 }
1. 窄依赖与宽依赖(外框表示RDD,内框表示分区):
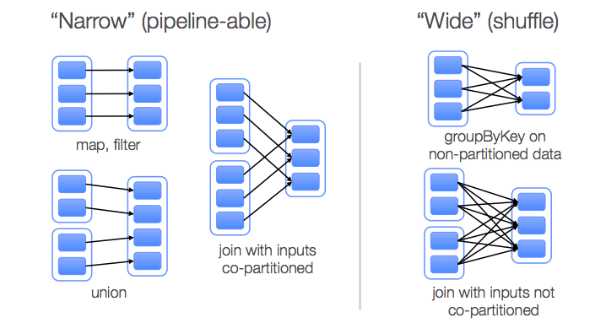
2. 窄依赖:父RDD每个分区最多被一个子RDD分区所用。
3. 宽依赖:子RDD每个分区都依赖所有分区或多个分区。
4. 特性:
a) pipeline操作:窄依赖可pipeline操作,即允许在单个集群节点上流水线式执行,该节点可计算所有父分区。
b) RDD故障恢复:窄依赖只需在故障集群节点上重新计算丢失的父分区,并且可在不同节点上并行重新计算;对于宽依赖,失败节点可能导致一个RDD所有父RDD分区丢失,都需重新计算。
5. WordCount依赖图:
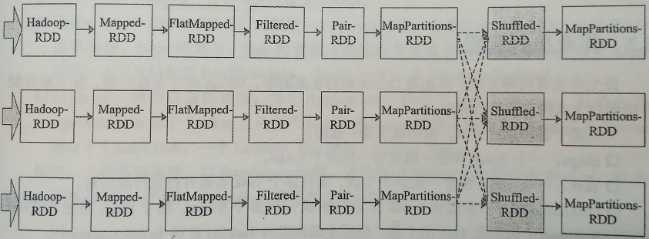
a) ShuffledRDD为宽依赖,将DAG划分成两个Stage:第1个Stage从HadoopRDD到MapPartitionsRDD,生成ShuffleMapTask;第2个Stage从ShuffledRDD到MapPartitionsRDD,生成ResultTask。
b) 第一个Stage由3个ShuffleMapTask通过pipeline方式并行执行,直至3个Task均执行结束至MapPartitionsRDD处。
1. DAG:在图论中,如果一个有向图无法从任一顶点出发经过若干条边回到该点,则这个图是一个有向无环图(Directed Acyclic Graph)。
2. Spark DAG:Spark将数据在分布式环境下分区,再将作业(Job)转化为DAG,并分阶段进行DAG调度和任务分布式并行处理。
3. Stage:DAG调度时,会根据Shuffle将Job划分Stage。如图,RDD A到RDD B间、RDD F到RDD G间都需要Shuffle,所以有3个Stage:RDD A、RDD C到RDD F、RDD B和RDD F到RDD G。
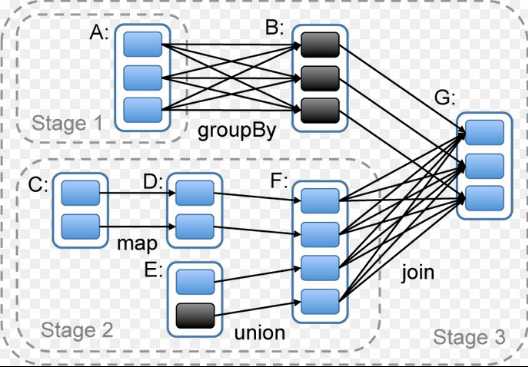
4. 流水线(pipeline):
a) Spark采用贪心算法划分Stage,即如果RDD的分区到父RDD分区是窄依赖,则实施经典的Fusion(融合)优化,把对应的Operation划分到一个Stage。
b) 如果连续RDD序列都是窄依赖,则把多个Operation并到一个Stage,直到遇到宽依赖。
c) pipeline好处:减少大量的全局屏障(barrier),并无须物化很多中间结果RDD,极大地提升性能。
1. 假设一个RDD故障,根据依赖关系和分区,仅需要再执行一遍父RDD的相应分区。
2. 跨宽依赖的再执行涉及多个父RDD,为避免故障RDD的大量父RDD再执行,Spark保持Map阶段中间数据输出的持久,再执行可获取相应分区的中间数据。
3. Spark提供数据checkpoint和记录日志持久化中间RDD。checkpoint直接将RDD持久化到磁盘或HDFS等存储,与cache/persist方法不同,checkpoint的RDD不会因作业结束而被消除,一直存在并被后续作业直接读取加载。
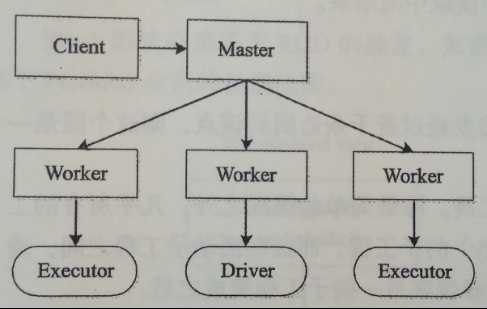
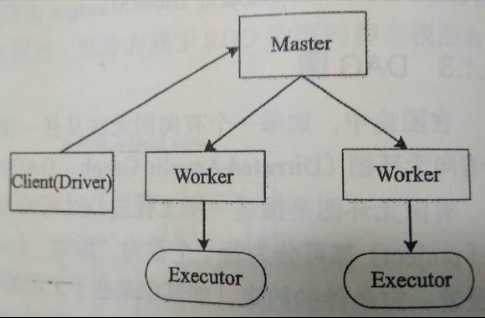
1. Standalone模式两种运行方式(--deploy-mode参数控制)
a) cluster方式:Driver运行在Worker节点。
b) client方式:Driver运行在客户端。
2. 作业执行流程(cluster方式):
a) 客户端提交Application给Master,Master让一个Worker启动Driver,即SchedulerBackend(Worker创建一个DriverRunner线程,DriverRunner启动SchedulerBackend进程)。
b) Master会让其余Worker启动Executor,即ExecutorBackend(Worker创建一个ExecutorRunner线程,ExecutorRunner会启动ExecutorBackend进程)。
c) ExecutorBackend启动后向Driver的SchedulerBackend注册。
d) SchedulerBackend进程中包含DAGScheduler,它根据用户程序生成执行计划,并调度执行。对于每个Stage的Task,都被存放到TaskScheduler中,ExecutorBackend向SchedulerBackend汇报时把TaskScheduler中的Task调度到ExecutorBackend执行。
e) 所有Stage都完成后Application结束。
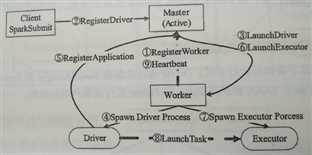
3. 故障恢复
a) 如果Worker发生故障:Worker退出前,将该Worker上的Executor杀掉;Worker通过定时心跳让Master感知Worker故障,而后汇报给Driver,并将该Worker移除;Driver可知该Worker上的Executor已被杀死。
b) 如果Executor发生故障:ExecutorRunner汇报给Master,由于Executor所在Worker正常,Master则发送LaunchExecutor指令给该Worker,让其再次启动一个Executor。
c) 如果Master发生故障:通过ZooKeeper搭建的Master HA(一个Active,其他Standby)切换Master。
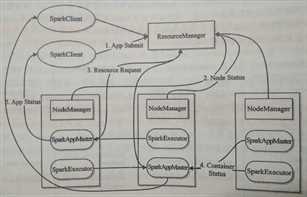
1. YARN模式两种运行方式(--deploy-mode参数控制)
a) cluster方式:Driver运行在NodeManager节点。
b) client方式:Driver运行在客户端。
i. SparkAppMaster:相当于Standalone模式的SchedulerBackend。SparkAppMaster包括DAGScheduler和YARNClusterScheduler。
ii. Executor:相当于Standalone模式的ExecutorBackend。
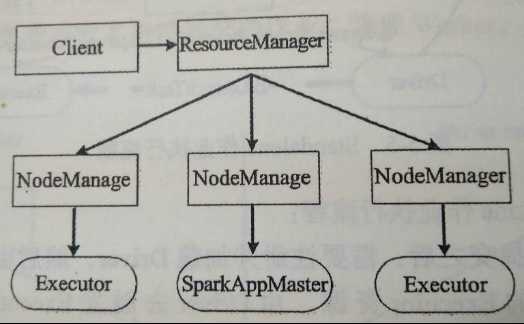
2. 作业执行流程(cluster方式):
a) 客户端提交Application给ResourceManager,ResourceManager在某一NodeManager汇报时把SparkAppMaster分配给NodeManager,NodeManager启动SparkAppMaster。
b) SparkAppMaster启动后初始化Application,然后向ResourceManager申请资源,申请后通过RPC让相应SparkAppMaster:相当于Standalone模式的SchedulerBackend。SparkAppMaster包括DAGScheduler和YARNClusterScheduler。
c) Executor:相当于Standalone模式的ExecutorBackend。的NodeManager启动SparkExecutor。
d) SparkExecutor向SparkAppMaster汇报并完成Task。
e) 此外,SparkClient通过SparkAppMaster获取Application运行状态。
1. 两种资源构建方式
a) 粗粒度:应用程序提交后,运行前,根据应用程序资源需求一次性凑齐资源,整个运行时不再申请资源。
b) 细粒度:应用程序提交后,动态向Cluster Manager申请资源,只要等到资源满足一个Task的运行,便开始运行该Task,而不必等到所有资源全部到位。
2. Spark on YARN仅支持粗粒度构建方式。
1. 准备数据。
hadoop fs -mkdir -p /test/wordcount hadoop fs -put README.md /test/wordcount
2. 执行程序。
spark-shell --master spark://centos1:7077
1 import org.apache.log4j.{Logger,Level} 2 Logger.getLogger("org.apache.spark").setLevel(Level.WARN) 3 Logger.getLogger("org.apache.spark.sql").setLevel(Level.WARN) 4 val textFile = sc.textFile("/test/wordcount/README.md") 5 val wordCounts = textFile.flatMap(line => line.split(" ")).map(word => (word, 1)).reduceByKey((count1, count2) => count1 + count2) 6 wordCounts.saveAsTextFile("/test/wordcount/result") 7 wordCounts.collect
a) “flatMap(line => line.split(" "))”:将文本每一行按空格拆分成单词RDD。
b) “map(word => (word, 1))”:将每个单词转换为单词+单词数的二元组RDD。
c) “reduceByKey((count1, count2) => count1 + count2)”:按key分组(即按单词分组)后,每组内单词数求和。
d) “collect”:Action操作,将RDD全部元素转换为Scala Array返回给Driver Program。如果数据量过大,会导致Driver Program内存不足。
3. 查看结果。
hadoop fs -cat /test/wordcount/WordCounts
1. 加载外部存储系统的文件构建RDD
a) 方法定义
def textFile(path: String, minPartitions: Int = defaultMinPartitions): RDD[String]
b) “sc.textFile("/test/directory")”:加载指定目录下所有文件。
c) “sc.textFile("/test/directory/*.txt")”:加载指定目录下所有txt格式的文件。
d) “sc.textFile("/test/directory/*.gz")”:加载指定目录下所有gz格式的文件,Hadoop内置支持.gz格式,但不支持split。其他压缩格式参考文档。
e) “sc.textFile("/test/directory/**/*")”:加载指定目录下所有文件(包含子目录)。
f) “sc.sequenceFile("/test/directory")”:以序列文件方式加载指定目录下所有文件。
g) textFile方法和sequenceFile方法:底层均调用hadoopFile方法,只是参数不同;均使用HadoopInputFormat的子类,TextInputFormat和SequenceFileInputFormat。
2. 从Scala数据集构建RDD
a) 方法定义
def parallelize[T: ClassTag](seq: Seq[T], numSlices: Int = defaultParallelism): RDD[T]
b) 示例
1 val testRdd = sc.parallelize(List("A", "B", "C", "D"), 2) 2 testRdd.partitions.size // 分区数2 3 testRdd.toDebugString // 查看Lineage
1. 主动持久化的目的:RDD重用,将计算结果RDD存储以供后续Operation使用。
2. persist方法:将任意RDD缓存到内存、磁盘和Tachyon文件系统。
def persist(newLevel: StorageLevel): this.type
3. cache方法:persist方法使用MEMORY_ONLY存储级别的快捷方式。
def cache()
4. 存储级别。
|
存储级别(Storage Level) |
含义 |
|
MEMORY_ONLY |
将RDD以反序列化(deserialized)Java对象存储到JVM。如果RDD不能被内存装下,一些分区将不会被缓存,并且在需要的时候被重新计算。这是默认级别。 |
|
MEMORY_AND_DISK |
将RDD以反序列化Java对象存储到JVM。如果RDD不能被内存装下,超出的分区被保存到硬盘上,并且在需要是被读取。 |
|
MEMORY_ONLY_SER |
将RDD以序列化(serialized)Java对象存储(每一分区占用一个字节数组)。通常比对象反序列化的空间利用率更高,尤其当使用快速序列化器(fast serializer),但在读取时比较消耗CPU。 |
|
MEMORY_AND_DISK_SER |
类似于MEMORY_ONLY_SER,但把超出内存的分区存储在硬盘上而不是在每次需要时重新计算。 |
|
DISK_ONLY |
只将RDD分区存储在硬盘上。 |
|
MEMORY_ONLY_2 MEMORY_AND_DISK_2 |
与上述存储级别一样,但将每个分区都复制到两个集群节点上。 |
|
OFF_HEAP (experimental) |
以序列化的格式将RDD存储到Tachyon…… |
5. 数据移除
a) 自动:集群内存不足时,Spark根据LRU(Least Recently Uesed,最近最少使用算法)删除数据分区。
b) 手动:unpersit方法,立即生效。
6. 演示效果。
a) 可在Spark监控页面Storage查看缓存生效情况;
b) 内存不足时,打印警告日志“Not enough space to cache rdd_ ... in memory ...”。
1 val file = sc.textFile("/test/wordcount/README.md") // 可分别尝试小文件和超大文件(视内存) 2 file.cache // 缓存到内存,lazy操作 3 file.count // Action操作触发lazy 4 file.unpersit // 释放缓存,eager操作
1. 加载文件创建RDD的分区数
a) “sc.defaultParallelism”默认并行数,是加载文件创建RDD的分区数最小值参考,实际的分区数由加载文件时的split数决定,即文件的HDFS block数,也可以由加载时的API参数制定分区数。
b) “sc.defaultParallelism”取配置项“spark.default.parallelism”的值,集群模式缺省为8、本地模式缺省为总内核数。
c) 示例。
1 val textFile = sc.textFile("/test/README.md") 2 textFile.toDebugString // 查看Lineage 3 textFile.partitions.size // 分区数4 4 sc.defaultParallelism // 默认并行数4
2. key-value RDD的分区数
a) partitioner方法是针对key-value RDD的分区器,默认使用HashPartitioner。
b) 通过源码可知,没有设置分区数时,会使用“spark.default.parallelism”配置项的值作为默认分区数。
1 // … 2 package org.apache.spark 3 // … 4 object Partitioner { 5 /** 6 * Choose a partitioner to use for a cogroup-like operation between a number of RDDs. 7 * 8 * If any of the RDDs already has a partitioner, choose that one. 9 * 10 * Otherwise, we use a default HashPartitioner. For the number of partitions, if 11 * spark.default.parallelism is set, then we‘ll use the value from SparkContext 12 * defaultParallelism, otherwise we‘ll use the max number of upstream partitions. 13 * 14 * Unless spark.default.parallelism is set, the number of partitions will be the 15 * same as the number of partitions in the largest upstream RDD, as this should 16 * be least likely to cause out-of-memory errors. 17 * 18 * We use two method parameters (rdd, others) to enforce callers passing at least 1 RDD. 19 */ 20 def defaultPartitioner(rdd: RDD[_], others: RDD[_]*): Partitioner = { 21 val bySize = (Seq(rdd) ++ others).sortBy(_.partitions.size).reverse 22 for (r <- bySize if r.partitioner.isDefined && r.partitioner.get.numPartitions > 0) { 23 return r.partitioner.get 24 } 25 if (rdd.context.conf.contains("spark.default.parallelism")) { 26 new HashPartitioner(rdd.context.defaultParallelism) 27 } else { 28 new HashPartitioner(bySize.head.partitions.size) 29 } 30 } 31 } 32 // …
1. 普通变量的问题:远程机器上对变量的修改无法传回Driver程序。当Spark以多个Task在不同Worker上并执行一个函数时,它传递每一个变量的副本并缓存在Worker上。
2. 分类:广播变量、累加器。
3. 广播变量:将只读变量缓存在每台Worker节点的cache,而不是每个Task发送一份副本。
1 val broadcastVar = sc.broadcast(Array(1, 2, 3)) // 初始化 2 broadcastVar.value // 获取
4. 累加器:能够进行“加”操作的变量,Spark原生支持Int和Double类型,可自定义新类型支持。
1 val accumulator = sc.accumulator(0) // 初始化 2 accumulator += 100 // 累加 3 accumulator.value // 获取
1. RDD Operation分为Transformation和Action:
a) Transformation:从已存在的RDD上创建一个新的RDD,是RDD的逻辑操作,并无真正计算(lazy),而是形成DAG。
b) Action:提交一个与前一个Action之间的所有Transformation组成的Job进行计算。
2. 常用Operation罗列(后面会详细展开各Operation的用法)
a) 通用RDD Transformation
|
名称 |
说明 |
|
map(func) |
数据集中的每条元素经过func函数转换后形成一个新的分布式数据集 |
|
filter(func) |
过滤作用,选取数据集中让函数func返回值为true的元素,形成一个新的数据集 |
|
flatMap(func) |
类似map,但每个输入项可以被映射到0个或更多的输出项(所以func应该返回一个Seq,而不是一个单独项) |
|
mapPartitions(func) |
类似map,但单独运行在RDD每个分区(块),因此运行类型为Type TRDD上时,func类型必须是Iterator<T> => Iterator<U> |
|
mapPartitionsWithIndex(func) |
与mapPartitions相似,但也要提供func与一个代表分区的的索引整数项,因此所运行的RDD为Type T时,func类型必须是(Int, Iterator<T>) => Iterator<U> |
|
sample(withReplacement, fraction) |
根据给定的随机种子seed,随机抽样出数量为fraction的数据(可以选择有无替代replacement) |
|
union(otherDataset) |
返回一个由原数据集和参数联合而成的新的数据集 |
|
intersection(otherDataset) |
返回一个包含数据集交集元素的新的RDD和参数 |
|
distinct([numTasks]) |
返回一个数据集去重过后的新的数据集 |
|
cartesian(otherDataset) |
当在数据类型为T和U的数据集上调用时,返回由(T, U)对组成的一个数据集 |
|
pipe(command, [envVars]) |
通过一个shell命令,如Perl或bash脚本,流水化各个分区的RDD。RDD元素被写入到进程的stdin,输出到stdout的行将会以一个RDD字符串的形式返回 |
|
coalesce(numPartitions) |
将RDD分区的数目合并为numPartitions |
|
repartition(numPartitions) |
在RDD上随机重洗数据,从而创造出更多或更少的分区以及它们之间的平衡。这个操作将重洗网络上所有的数据 |
b) key-value RDD Transformation
|
名称 |
说明 |
|
groupByKey([numTasks]) |
当在一个由键值对(K, V)组成的数据集上调用时,按照key进行分组,返回一个(K, Iterable<V>)对的数据集。 注意: 1) 如果是为了按照key聚合数据(如求和、平均值)而进行分组,使用reduceByKey或combineByKey方法性能更好 2) 默认情况下,输出的并行程度取决于父RDD的分区数。可以通过传递一个可选的的numTasks参数设置不同的并行任务数 |
|
reduceByKey(func, [numTasks]) |
当在一个键值对(K, V)组成的数据集上调用时,按照key进行分组,使用给定func聚合values值,返回一个键值对(K, V)数据集,其中func函数的类型必须是(V, V) => V。类似于groupByKey,并行任务数可通过可选的第二个参数配置 |
|
sortByKey([ascending], [numTasks]) |
返回一个以key排序(升序或降序)的(K, V)键值对组成的数据集,其中布尔型参数ascending决定升序还是降序,而numTasks为并行任务数 |
|
join(otherDataset, [numTasks]) |
根据key连接两个数据集,将类型为(K, V)和(K, W)的数据集合并成一个(K, (V, W))类型的数据集。外连接通过leftouterjoin和rightouterjoin,其中numTasks为并行任务数 |
|
cogroup(otherDataset, [numTasks]) |
当在两个形如(K, V)和(K, W)的键值对数据集上调用时,返回一个(K, Iterable<V>, Iterable<W>)形式的数据集 |
c) 通用RDD Action
|
名称 |
说明 |
|
reduce(func) |
通过函数func聚集数据集中的所有元素,func函数接收两个参数,返回一个值,这个函数必须满足交换律和结合律,以确保可以被正确地并发执行 |
|
collect() |
在Driver程序中,以数组形式返回数据集的所有元素到Driver程序,为防止Driver程序内存溢出,一般要控制返回的数据集大小 |
|
count() |
返回数据集的元素个数 |
|
first() |
返回数据集的第一个元素 |
|
take(n) |
以数组形式,返回数据集上前n个元素 |
|
takeSample(withReplacement, num, seed) |
返回一个数组,由数据集中随机采样的num个元素组成,可以选择是否用随机数替换不足的部分,seed用于指定的随机数生成器种子 |
|
takeOrdered(n, [ordering]) |
使用自然顺序或自定义比较器,返回前n个RDD元素 |
|
foreach(func) |
在数据集的每个元素上运行func。具有副作用,如会更新累加器变量或与外部存储系统相互作用 |
d) key-value RDD Action
|
名称 |
说明 |
|
countByKey |
返回形如(K, int)的hashmap,对每个key的个数计数 |
1. 隐式转换函数为装载不同类型的RDD提供了相应的额外方法。
2. 隐式转换后的类包括以下几种:
a) PairRDDFunctions:输入的数据单元是2元元组,分别为key和value。
b) DoubleRDDFunctions:输入的数据单元可隐式转换为Scala的Double类型。
c) OrderedRDDFunctions:输入的数据单元是2元元组,并且key可排序。
d) SequenceFileRDDFunctions:输入的数据单元是2元元组。
1. coalesce
a) 定义
def coalesce(numPartitions: Int, shuffle: Boolean = false)(implicit ord: Ordering[T] = null): RDD[T]
参数:
|
numPartitions |
新分区数 |
|
shuffle |
重新分区时是否shuffle |
b) 功能
返回分区数为numPartitions的新RDD。如果增加分区数,shuffle必须为true,否则重新分区无效。
c) 示例
1 val rdd = sc.parallelize(List("A", "B", "C", "D", "E"), 2) 2 rdd.partitions.size // 分区数2 3 rdd.coalesce(1).partitions.size // 分区数2→1 4 rdd.coalesce(4).partitions.size // 分区数2→4无效,仍然是2 5 rdd.coalesce(4, true).partitions.size // 分区数2→4
d) 应用场景
i. 大数据RDD过滤后,各分区数据量非常小,可重新分区减小分区数,把小数据量分区合并成一个分区。
ii. 小数据量RDD保存到HDFS前,可重新分区减小分区数(比如1),保存成1个文件,从而减少小文件个数,也方便查看。
iii. 分区数过少,导致CPU使用率过低时,可重新分区增加分区数,从而提高CPU使用率,提升性能。
2. repartition
a) 定义
def repartition(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T]
参数:
|
numPartitions |
新分区数 |
b) 功能
从源码可看出,repartition是coalesce shuffle为true的版本,故不在赘述。
1 /** 2 * Return a new RDD that has exactly numPartitions partitions. 3 * 4 * Can increase or decrease the level of parallelism in this RDD. Internally, this uses 5 * a shuffle to redistribute data. 6 * 7 * If you are decreasing the number of partitions in this RDD, consider using `coalesce`, 8 * which can avoid performing a shuffle. 9 */ 10 def repartition(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T] = withScope { 11 coalesce(numPartitions, shuffle = true) 12 }
c) 示例
1 val rdd = sc.parallelize(List("A", "B", "C", "D", "E"), 2) 2 rdd.partitions.size // 分区数2 3 rdd.repartition(1).partitions.size // 分区数2→1 4 rdd.repartition(4).partitions.size // 分区数2→4
d) 应用场景
与coalesce一致。
1. aggregate
a) 定义
def aggregate[U: ClassTag](zeroValue: U)(seqOp: (U, T) => U, combOp: (U, U) => U): U
参数:
|
zeroValue |
执行seqOp和combOp的初始值。源码注释:the initial value for the accumulated result of each partition for the `seqOp` operator, and also the initial value for the combine results from different partitions for the `combOp` operator - this will typically be the neutral element (e.g. `Nil` for list concatenation or `0` for summation) |
|
seqOp |
聚合分区的函数。源码注释:an operator used to accumulate results within a partition |
|
combOp |
聚合seqOp结果的函数。源码注释:an associative operator used to combine results from different partitions |
b) 功能
先使用seqOp将RDD中每个分区中的T类型元素聚合成U类型,再使用combOp将之前每个分区聚合后的U类型聚合成U类型,注意seqOp和combOp都会使用zeroValue作为初始值,zeroValue的类型为U。
c) 示例
1 var rdd = sc.makeRDD(1 to 10, 2) 2 rdd.aggregate(2)({(x: Int, y: Int) => x + y}, {(a: Int, b: Int) => a * b}) 3 // 分区1:2 + 1 + 2 + 3 + 4 + 5 = 17, 4 // 分区2:2 + 6 + 7 + 8 + 9 + 10 = 42 5 // 最后:2 * 17 * 42 = 1428
2. reduce
a) 定义
def reduce(f: (T, T) => T): T
参数:
|
f |
合并函数,二变一 |
b) 功能
将RDD中元素两两传递给输入f函数,同时产生一个新的值,新产生的值与RDD中下一个元素再被传递给输入函数直到最后只有一个值为止。
c) 示例
1 var rdd = sc.makeRDD(1 to 10, 2) 2 rdd.reduce((x, y) => if (x > y) x else y) // 求最大值,10 3 import java.lang.Math 4 rdd.reduce((x, y) => Math.max(x, y)) // 求最大值,与上面逻辑一致 5 rdd.reduce((x, y) => x + y) // 求和,55
3. fold
a) 定义
def fold(zeroValue: T)(op: (T, T) => T): T
参数:
|
zeroValue |
op函数的初始值 |
|
op |
合并函数,二变一 |
b) 功能
以zeroValue为初始值,将RDD中元素两两传递给输入f函数,同时产生一个新的值,新产生的值与RDD中下一个元素再被传递给输入函数直到最后只有一个值为止。
c) 示例
1 var rdd = sc.makeRDD(1 to 10, 2) 2 rdd.fold(100)((x, y) => if (x > y) x else y) // 求最大值,100 3 import java.lang.Math 4 rdd.reduce((x, y) => Math.max(x, y)) // 求最大值,与上面逻辑一致 5 rdd.reduce((x, y) => x + y) // 求和,155
4. 三者关系
fold比reduce多一个初始值;fold是aggregate seqOp和combOp函数相同时的简化版。
1. cartesian
a) 定义
def cartesian[U: ClassTag](other: RDD[U]): RDD[(T, U)]
参数:
|
other |
另一个RDD |
b) 功能
笛卡尔积。
c) 示例
1 val rdd1 = sc.parallelize(List[String]("A", "B", "C", "D", "E"), 2) 2 val rdd2 = sc.parallelize(List[Int](1, 2, 3, 4, 5, 6), 2) 3 val rdd3 = rdd1 cartesian rdd2 4 rdd3.collect 5 val rdd4 = rdd2 cartesian rdd1 6 rdd4.collect
2. unioin
a) 定义
def union(other: RDD[T]): RDD[T]
参数:
|
other |
另一个RDD |
b) 功能
联合两个RDD,注意不会去重。
union实际是将父依赖RDD所有分区合并成各自分区,最终的分区与父依赖RDD分区一一对应。
c) 示例
1 val rdd1 = sc.parallelize(List[String]("A", "B", "C"), 2) 2 val rdd2 = sc.parallelize(List[String]("D", "E"), 1) 3 rdd1.partitions.size // 分区数2 4 rdd2.partitions.size // 分区数1 5 val rdd3 = rdd1 union rdd2 6 rdd3.partitions.size // 分区数3 7 rdd3.collect // Array(A, B, C, C, D)
3. zip
a) 定义
def zip[U: ClassTag](other: RDD[U]): RDD[(T, U)]
参数:
|
other |
另一个RDD |
b) 功能
拉链操作,将两个RDD中第i个元素组成一个元祖,形成key-value的二元组PairRDD。
注意:两个RDD分区数必须一致,否则报错“Can’t zip RDDs with unequal numbers of partitions”;两个RDD元素个数必须一致,否则报错“Can only zip RDDs with same number of elements”。
c) 示例
1 val rdd1 = sc.parallelize(1 to 4, 2) 2 val rdd2 = sc.parallelize("a b c d".split(" "), 2) 3 val rdd3 = rdd1 zip rdd2 4 rdd3.collect // Array((1, a), (2, b), (3, c), (4, d))
4. zipPartitions
a) 定义
def zipPartitions[B: ClassTag, V: ClassTag](rdd2: RDD[B], preservesPartitioning: Boolean)(f: (Iterator[T], Iterator[B]) => Iterator[V]): RDD[V] def zipPartitions[B: ClassTag, V: ClassTag](rdd2: RDD[B])(f: (Iterator[T], Iterator[B]) => Iterator[V]): RDD[V] def zipPartitions[B: ClassTag, C: ClassTag, V: ClassTag](rdd2: RDD[B], rdd3: RDD[C], preservesPartitioning: Boolean)(f: (Iterator[T], Iterator[B], Iterator[C]) => Iterator[V]): RDD[V] def zipPartitions[B: ClassTag, C: ClassTag, V: ClassTag](rdd2: RDD[B], rdd3: RDD[C])(f: (Iterator[T], Iterator[B], Iterator[C]) => Iterator[V]): RDD[V] def zipPartitions[B: ClassTag, C: ClassTag, D: ClassTag, V: ClassTag](rdd2: RDD[B], rdd3: RDD[C], rdd4: RDD[D], preservesPartitioning: Boolean)(f: (Iterator[T], Iterator[B], Iterator[C], Iterator[D]) => Iterator[V]): RDD[V] def zipPartitions[B: ClassTag, C: ClassTag, D: ClassTag, V: ClassTag](rdd2: RDD[B], rdd3: RDD[C], rdd4: RDD[D])(f: (Iterator[T], Iterator[B], Iterator[C], Iterator[D]) => Iterator[V]): RDD[V]
参数:
|
f |
拉链操作函数 |
b) 功能
N(N=2, 3, 4)个RDD的拉链操作,具体操作由f函数指定。
c) 示例
val rdd1 = sc.parallelize(1 to 4, 2) val rdd2 = sc.parallelize("a b c d".split(" "), 2) def zipFunc(aIter: Iterator[Int], bIter: Iterator[String]): Iterator[String] = { var list = List[String]() while (aIter.hasNext && bIter.hasNext) { val str = aIter.next + "+" + bIter.next list ::= str } list.iterator } val rdd3 = rdd1.zipPartitions(rdd1, rdd2)(zipFunc) rdd3.collect // Array(1+a, 2+b, 3+c, 4+d)
5. zipWithUniqueId
a) 定义
def zipWithUniqueId(): RDD[(T, Long)]
b) 功能
将当前RDD元素与索引i进行拉链操作。
c) 示例
1 val rdd = sc.parallelize("a b c d".split(" "), 2) 2 rdd.zipWithUniqueId.collect // Array((a, 0), (b, 1), (c, 2), (d, 3))
1. histogram
a) 定义
def histogram(buckets: Array[Double], evenBuckets: Boolean = false): Array[Long] def histogram(bucketCount: Int): Pair[Array[Double], Array[Long]]
参数:
|
buckets |
分桶区间,左闭右开区间“[)” |
|
evenBuckets |
是否采用常亮时间内快速分桶方法 |
|
bucketCount |
平均分桶,每桶区间 |
b) 功能
生成柱状图的分桶。
c) 示例
1 val rdd = sc.parallelize(List(1.1, 1.2, 2.1, 2.2, 2, 3, 4.1, 4.3, 7.1, 8.3, 9.3), 2) 2 rdd.histogram(Array(0.0, 4.1, 9.0)) 3 rdd.histogram(Array(0.0, 4.1, 9.0), true) 4 rdd.histogram(3)
2. mean/meanApprox
a) 定义
def mean(): Double
def meanApprox(timeout: Long, confidence: Double = 0.95): PartialResult[BoundedDouble]
b) 功能
Mean计算平均值,meanApprox计算近似平均值。
c) 示例
1 val rdd = sc.parallelize(List(1.1, 1.2, 2.1, 2.2, 2, 3, 4.1, 4.3, 7.1, 8.3, 9.3), 2) 2 rdd.mean
3. sampleStdev
a) 定义
def sampleStdev(): Double
b) 功能
计算样本标准偏差(sample standard deviation)。
c) 示例
1 val rdd = sc.parallelize(List(1.1, 1.2, 2.1, 2.2, 2, 3, 4.1, 4.3, 7.1, 8.3, 9.3), 2) 2 rdd.sampleStdev
4. sampleVariance
a) 定义
def sampleVariance(): Double
b) 功能
计算样本偏差(sample variance)。
c) 示例
val rdd = sc.parallelize(List(1.1, 1.2, 2.1, 2.2, 2, 3, 4.1, 4.3, 7.1, 8.3, 9.3), 2)
rdd.sampleVariance
5. stats
a) 定义
def stats(): StatCounter
b) 功能
返回org.apache.spark.util.StatCounter对象,包括平均值、标准偏差、最大值、最小值等。
c) 示例
val rdd = sc.parallelize(List(1.1, 1.2, 2.1, 2.2, 2, 3, 4.1, 4.3, 7.1, 8.3, 9.3), 2)
rdd.stats
6. stdev
a) 定义
def stdev(): Double
b) 功能
计算标准偏差(standard deviation)。
c) 示例
1 val rdd = sc.parallelize(List(1.1, 1.2, 2.1, 2.2, 2, 3, 4.1, 4.3, 7.1, 8.3, 9.3), 2) 2 rdd.stdev
7. sum/sumApprox
a) 定义
def sum(): Double
def sumApprox(timeout: Long, confidence: Double = 0.95): PartialResult[BoundedDouble]
b) 功能
sum计算总和,sumApprox计算近似总和。
c) 示例
1 val rdd = sc.parallelize(List(1.1, 1.2, 2.1, 2.2, 2, 3, 4.1, 4.3, 7.1, 8.3, 9.3), 2) 2 rdd.sum 3 rdd.sumApprox
8. variance
a) 定义
def variance(): Double
b) 功能
计算方差(variance)。
c) 示例
1 val rdd = sc.parallelize(List(1.1, 1.2, 2.1, 2.2, 2, 3, 4.1, 4.3, 7.1, 8.3, 9.3), 2) 2 rdd.variance
1. aggregateByKey
a) 定义
def aggregateByKey[U: ClassTag](zeroValue: U)(seqOp: (U, V) => U, combOp: (U, U) => U): RDD[(K, U)] def aggregateByKey[U: ClassTag](zeroValue: U, numPartitions: Int)(seqOp: (U, V) => U, combOp: (U, U) => U): RDD[(K, U)] def aggregateByKey[U: ClassTag](zeroValue: U, partitioner: Partitioner)(seqOp: (U, V) => U, combOp: (U, U) => U): RDD[(K, U)]
参数:
|
zeroValue |
参考aggregate |
|
seqOp |
参考aggregate |
|
combOp |
参考aggregate |
|
numPartitions |
分区数,使用new HashPartitioner(numPartitions)分区器 |
|
partitioner |
指定自定义分区器 |
b) 功能
aggregateByKey与aggregate功能类似,区别在于前者仅对key相同的聚合。
c) 示例
1 val rdd = sc.parallelize(List((1, 3), (1, 2), (1, 4), (2, 3))) // Array((1,9), (2,3)) 2 import java.lang.Math 3 rdd.aggregateByKey(1)({(x: Int, y: Int) => Math.max(x, y)}, {(a: Int, b: Int) => a + b}).collect
2. combineByKey
a) 定义
def combineByKey[C](createCombiner: V => C, mergeValue: (C, V) => C, mergeCombiners: (C, C) => C): RDD[(K, C)] def combineByKey[C](createCombiner: V => C, mergeValue: (C, V) => C, mergeCombiners: (C, C) => C, numPartitions: Int): RDD[(K, C)] def combineByKey[C](createCombiner: V => C, mergeValue: (C, V) => C, mergeCombiners: (C, C) => C, partitioner: Partitioner, mapSideCombine: Boolean = true, serializer: Serializer = null): RDD[(K, C)]
参数:
|
createCombiner |
组合器函数,用于将V类型转换成C类型,输入参数为RDD[K,V]中的V,输出为C |
|
mergeValue |
合并值函数,将一个C类型和一个V类型值合并成一个C类型,输入参数为(C,V),输出为C |
|
mergeCombiners |
合并组合器函数,用于将两个C类型值合并成一个C类型,输入参数为(C,C),输出为C |
|
mapSideCombine |
是否需要在Map端进行combine操作,类似于MapReduce中的combine,默认为true |
b) 功能
将RDD[(K,V)]combine为RDD[(K,C)]。非常重要,aggregateByKey、foldByKey、reduceByKey等函数都基于它实现。
c) 示例
1 val rdd = sc.parallelize(List((1, "www"), (1, "iteblog"), (1, "com"), (2, "bbs"), (2, "iteblog"), (2, "com"), (3, "good"))) 2 rdd.combineByKey(List(_), (x: List[String], y: String) => y :: x, (x: List[String], y: List[String]) => x ::: y).collect // Array((1, List(www, iteblog, com)), (2, List(bbs, iteblog, com)), (3, List(good)))
1 val rdd = sc.parallelize(List(("iteblog", 1), ("bbs", 1), ("iteblog", 3))) 2 rdd.combineByKey(x => x, (x: Int, y: Int) => x + y, (x: Int, y: Int) => x + y).collect // Array((iteblog, 4), (bbs, 1))
d) 应用场景
combineByKey将大数据的处理转为对小数据量的分区级别处理,然后合并各分区处理后再次进 行聚合,提升了对大数据量的处理性能。
3. foldByKey
a) 定义
def foldByKey(zeroValue: V)(func: (V, V) => V): RDD[(K, V)] def foldByKey(zeroValue: V, numPartitions: Int)(func: (V, V) => V): RDD[(K, V)] def foldByKey(zeroValue: V, partitioner: Partitioner)(func: (V, V) => V): RDD[(K, V)]
参数:
|
zeroValue |
func函数的初始值 |
|
func |
合并函数,二变一 |
b) 功能
foldByKey与fold功能类似,区别在于前者仅对key相同的聚合。
c) 示例
1 var rdd = sc.makeRDD(Array(("A",0),("A",2),("B",1),("B",2),("C",1))) 2 rdd.foldByKey(0)(_+_).collect // Array((A,2), (B,3), (C,1)) 3 rdd.foldByKey(2)(_+_).collect // Array((A,6), (B,7), (C,3))
4. reduceByKey
a) 定义
def reduceByKey(func: (V, V) => V): RDD[(K, V)] def reduceByKey(func: (V, V) => V, numPartitions: Int): RDD[(K, V)] def reduceByKey(partitioner: Partitioner, func: (V, V) => V): RDD[(K, V)]
参数:
|
func |
合并函数,二变一 |
b) 功能
reduceByKey与reduce功能类似,区别在于前者仅对key相同的聚合。
c) 示例
1 var rdd = sc.makeRDD(Array(("A",0),("A",2),("B",1),("B",2),("C",1))) 2 rdd.reduceByKey(_+_).collect // Array((A,2), (B,3), (C,1))
1. join族
a) 定义
def join[W](other: RDD[(K, W)]): RDD[(K, (V, W))]
def join[W](other: RDD[(K, W)], numPartitions: Int): RDD[(K, (V, W))]
def join[W](other: RDD[(K, W)], partitioner: Partitioner): RDD[(K, (V, W))]
def leftOuterJoin[W](other: RDD[(K, W)]): RDD[(K, (V, Option[W]))]
def leftOuterJoin[W](other: RDD[(K, W)], numPartitions: Int): RDD[(K, (V, Option[W]))]
def leftOuterJoin[W](other: RDD[(K, W)], partitioner: Partitioner): RDD[(K, (V, Option[W]))]
def rightOuterJoin[W](other: RDD[(K, W)]): RDD[(K, (Option[V], W))]
def rightOuterJoin[W](other: RDD[(K, W)], numPartitions: Int): RDD[(K, (Option[V], W))]
def rightOuterJoin[W](other: RDD[(K, W)], partitioner: Partitioner): RDD[(K, (Option[V], W))]
def fullOuterJoin[W](other: RDD[(K, W)]): RDD[(K, (Option[V], Option[W]))]
def fullOuterJoin[W](other: RDD[(K, W)], numPartitions: Int): RDD[(K, (Option[V], Option[W]))]
def fullOuterJoin[W](other: RDD[(K, W)], partitioner: Partitioner): RDD[(K, (Option[V], Option[W]))]
参数:
|
other |
另一个RDD |
b) 功能
两个RDD连接操作。
c) 示例
1 val rdd1 = sc.parallelize(List(("Tom", 21), ("Jerry", 31), ("Mary", 23))) 2 val rdd2 = sc.parallelize(List(("Tom", ‘m‘), ("Mary", ‘f‘), ("Henry", ‘m‘))) 3 val rdd3 = rdd1 join rdd2 4 rdd3.collect // Array((Mary, (23, f)), (Tom, (21, m)))
1. sortByKey
a) 定义
def sortByKey(ascending: Boolean = true, numPartitions: Int = self.partitions.length): RDD[(K, V)]
参数:
|
ascending |
是否正序 |
|
numPartitions |
新分区数,默认为原分区数 |
b) 功能
返回按key排序的新RDD。
c) 示例
1 val rdd1 = sc.parallelize(List((3, "a"), (7, "b"), (5, "c"), (3, "b"), (6, "c"), (9, "d")), 3) 2 val rdd2 = rdd1.sortByKey 3 rdd2.collect // Array((3, a), (3, b), (5, c), (6, c), (7, b), (9, d)) 4 rdd2.partitions.size // 分区数3 5 val rdd3 = rdd1.sortByKey(true, 2) 6 rdd3.collect 7 rdd3.partitions.size // 分区数2
2. repartitionAndSortWithinPartitions
a) 定义
def repartitionAndSortWithinPartitions(partitioner: Partitioner): RDD[(K, V)]
参数:
|
partitioner |
分区器 |
b) 功能
返回使用分区器partitioner重新分区并且对各分区按key排序的新RDD。
c) 示例
1 val rdd1 = sc.parallelize(List((3, "a"), (7, "b"), (5, "c"), (3, "b"), (6, "c"), (9, "d")), 3) 2 import org.apache.spark.HashPartitioner 3 val rdd2 = rdd1.repartitionAndSortWithinPartitions(new HashPartitioner(2)) // HashPartitioner(2)以key对分区数取模分区,所以奇数、偶数分到两个分区。 4 rdd2.collect // Array((6, c), (3, a), (3, b), (5, c), (7, b), (9, d)) 5 rdd1.partitions.size // 分区数3 6 rdd2.partitions.size // 分区数2
1. 数据结构:移动终端上网访问记录
|
字段 |
说明 |
|
nodeid |
基站ID |
|
ci |
小区标识(cell identity) |
|
imei |
国际移动设备标识码(IMEI) |
|
app |
应用名称 |
|
time |
访问时间 |
|
uplinkbytes |
上行字节数 |
|
downlinkbytes |
下行字节数 |
2. 测试数据
1,1,460028714280218,360,2015-05-01,7,1116 1,2,460028714280219,qq,2015-05-02,8,121 1,3,460028714280220,yy,2015-05-03,9,122 1,4,460028714280221,360,2015-05-04,10,119 2,1,460028714280222,yy,2015-05-05,5,1119 2,2,460028714280223,360,2015-05-01,12,121 2,3,460028714280224,qq,2015-05-02,13,122 3,1,460028714280225,qq,2015-05-03,1,1117 3,2,460028714280226,qq,2015-05-04,9,1118 3,3,460028714280227,qq,2015-05-05,10,120 1,1,460028714280218,360,2015-06-01,7,1118 1,2,460028714280219,qq,2015-06-02,8,1119 1,3,460028714280220,yy,2015-06-03,9,1120 1,4,460028714280221,360,2015-06-04,10,119 2,1,460028714280222,yy,2015-06-05,11,1118 2,2,460028714280223,360,2015-06-02,4,121 2,3,460028714280224,qq,2015-06-03,17,1119 3,1,460028714280225,qq,2015-06-04,18,119 3,2,460028714280226,qq,2015-06-05,19,1119 3,3,460028714280227,qq,2015-06-10,120,121
3. 上传数据文件至HDFS
hadoop fs -put mobile.csv /test/
预处理,如无效数据过滤等。
1 val fields = sc.broadcast(List("nodeid", "ci", "imei", "app", "time", "uplinkbytes", "downlinkbytes")) 2 val mobile = sc.textFile("/test/mobile.csv").map(_.split(",")).filter(line => line.length != fields.value.length)
1 mobile.map(line => (line(fields.value.indexOf("app")), 1)).reduceByKey(_+_).map(appCount => (appCount._2, appCount._1)).sortByKey(false).map(appCount => (appCount._1, appCount._2)).repartition(1).saveAsTextFile("/text/result.csv") // Array((qq, 10), (360, 6), (yy, 4))
1 mobile.map(line => line(fields.value.indexOf("imei")) + ":" + line(fields.value.indexOf("time"))).distinct().map(imeiTime => (imeiTime.split(":")(1), 1)).reduceByKey(_+_).sortByKey().collect // Array((2015-05-01, 2), (2015-05-02, 2), (2015-05-03, 2), (2015-05-04, 2), (2015-05-05, 2), (2015-06-01, 2), (2015-06-03, 2), (2015-06-04, 2), (2015-06-05, 2), (2015-06-10, 1))
1 mobile.map { line => 2 val time = line(fields.value.indexOf("time")) 3 val month = time.substring(0, time.lastIndexOf("-")) 4 line(fields.value.indexOf("imei")) + ":" + month 5 }.distinct.map { imeiMonth => (imeiMonth.split(":")(1), 1) }.reduceByKey(_+_).sortByKey().collect // Array((2015-05, 10), (2015-06, 10))
1 mobile.map { line => 2 val uplinkbytes = line(fields.value.indexOf("uplinkbytes")) 3 val downlinkbytes = line(fields.value.indexOf("downlinkbytes")) 4 (line(fields.value.indexOf("app")), (uplinkbytes, downlinkbytes)) 5 }.reduceByKey((updownlinkbytes1, updownlinkbytes2) => (updownlinkbytes1._1 + updownlinkbytes2._1, updownlinkbytes1._2 + updownlinkbytes2._2)).collect // Array((yy, (34.0, 3479.0)), (qq, (117.0, 6195.0)), (360, (54.0, 2714.0)))
标签:art daemon rbac 字段 对象存储 mmu contain nec property
原文地址:http://www.cnblogs.com/netoxi/p/7223412.html