摘要:
文章首先指出,现存的特征学习方法还不能足够的捕捉出显示网络中被观测到的联通模式的的多样性
作者同时认为在搜索相邻节点时增加灵活性时提升特征学习算法的关键
主要贡献:我们定义了节点网络的表述,并且提出了一种带偏置的随机游走策略,这种策略可以有效地检索分散的相邻节点。
正文1
任何的有监督的学习算法均需要一系列的信息性,差异性和独立的特征表示,一种典型的解决方法是基于专业知识手动设计特定领域的特征。这样的特征只能适应于特定的任务领域。另一种可选的方法是通过解决优化问题去学习一组特征表示。其中的挑战就是定义一个目标函数,这个目标函数需要兼顾计算有效性和预测的准确性
目前的技术还不能够满足定义和优化一个合理的目标,这个目标需要
作者提出一个实例,在实例中不同的节点同时表现结构性和社区差异
直观上,我们的方法在d维空间上返回了 一系列的特征表达,这些特征表达最大化了节点的邻接节点的似然估计。
总结:综合以上的知识,我们提出的node2vec对于网络中的特征学习是一种高效的可扩展算法。
正文3:
将特征学习公式化的表达为一个最大似然优化问题。在这里最大似然问题属于半监督学习类型
为了使得优化问题易于处理,给出了两个标准假设:
条件独立:
特征空间的对称性:
搜索策略是文章作者的主要创新点,在文章的3.2节,主要讲述了这个sample的过程,首先给定了一个随机游走的公式
后来的这一点主要讲的是skip-gram相关的一些计算,大体上都一样。
正文3.1
首先是两种经典的搜索策略,深度优先和广度优先,搜索的策略实际是一个构建语料库的过程。广度优先(BFS):作者举了一个例子,当k=3时,sample到的node就是s1,s2,s3。广度优先可以更多的保留同构的信息,深度优先(DFS):增加距离序列性的增加邻节点,可以看出深度优先sample到的是s4,s5,s6
作者定义这两种搜索策略是为了后文提出同质性和同构性的概念进行铺垫,很明显现实世界中存在这样的结构特点。在任务为导向的建立语料库的过程中可能同样会需要找到同质性(聚类)的点或同构性(分类)的点。这样的话我们貌似从这个定义中又看到了很多东西,不过这需要更进一步的探索和证明。
有意思的是本文的作者并没有给出数学的证明来演示同质性和同构性的概念,而是选择了一个实验说明这样的性质,就是在后文中的一个东西,它使用了悲惨世界中的每个人物作为一个节点,通过聚类来建构其中的关系,实验的具体的设定实际说的并不仔细,而且给出图画的效果很好。这样就给出了结果的证明(后推)
下面开始说公式,
本文给出的随机游走的公式实际很简单。就是一个概率的东西。类似于给了一个方向盘,给了一个刹车,随便走,走过的路我拿来做经验,来充当训练的材料,但是这个材料的好坏确实能够影响最终任务结果的好坏。
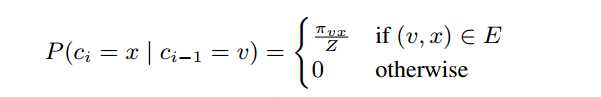
在这个公式里面,ci表示节点,实际表示的意思是一个条件概率,走的方向取决于前一个节点,而概率的计算则取决于权重与偏置,在这里偏置阿尔法为
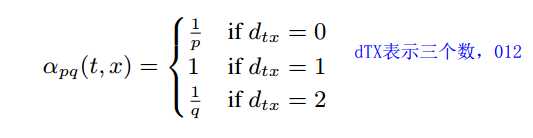
在这里p作为一个回归的参数(return)这个参数的作用并不大,最多就是控制游走在初始点的附近。而q则是控制走的深度(in or out),这样的情况下通过选不同的pq组合让游走的序列可以采集到更多的同质性的信息还是同构性的信息。
作者评价自己的随机游走的这个特点:我们的方法不像是广度优先和深度优先这样的方法过于强调要样本化同构性和同质性,这样的算法可以更加适应这些性质的描述,不是独有的和竞争性的关系,而是类似真实世界展示的两种结构的混合。
关于文章作者所说的sample这个词的含义:实际对于这一系列的方法没有必要故弄玄虚,全都是对于语料库建立方法的一个改进,无非是第一篇开创性的deepwalk的迁移工作(从自然语言到NE)具有开创性的,也确实取得了效果,由于LINE方法效果并不能确切的说提升很大,这样就导致,所有的方法没有了什么进步。

这个pipline也有很多的参考意义,作者基本没提优化的事情,直接就是自己主要的工作,很简洁。优化问题应该和deepwalk一样,所以在算法1里面是给出了一个梯度下降的公式,这个梯度下降的公式输入为walks,可以看出,本文的主要目的就是在于构建一个更能反映任务本质的语料库。这个伪代码和论文的叙述没有出入。最后生成的语料库是一个V*r*l维的集合。每一个节点序列就对应了nlp中语料库的一句话。代码里面应该更加详细选取窗口等等的参数。
实验效果与性能评价
作为斯坦福大学的论文,本文对这个方法给出了全面的测评,首先使用的悲惨世界的图例说明了同质性和同构性的概念是对的,然后比较了多分类标签的意义,比较了鲁棒性,比较了边分类的效果,参数敏感性。这样的实验结果足以把这篇论文做成一个经得起考验的成果。
下图是悲惨世界的聚类效果

效果很好上面的图更多的选取的同质性的,所以将q设置的小一点
下面的图需要的是同构性的信息所以q值很大。
下面是多标签的分类效果:
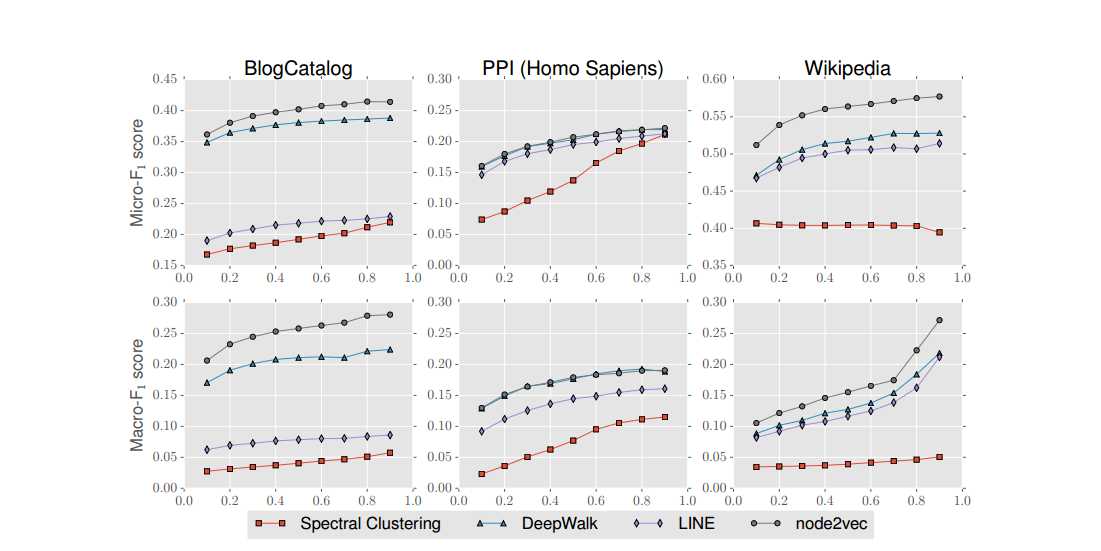
给的指标是,横坐标是数据量的大小,纵坐标是f1的分数平均,具体的f1分数概念可以看网上的一些解释,这个之前我也没接触过。看效果line效果并不好,而本文方法相比deepwalk略有提升。这个还是很厉害的。毕竟是顶会,而且工作如此扎实。
其他的作者给出的测试指标就不说了,下一篇准备精读一下deepwalk的方法,重要的是里面的优化方法和负采样的训练方法还没搞明白
原文地址:http://www.cnblogs.com/bybabo/p/7257867.html