标签:点距 重复 结果 near 阈值 通过 扩大 介绍 效果
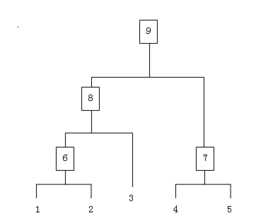
假设有N个待聚类的样本,对于层次聚类来说,步骤:
聚类:层次聚类
原文地址:http://www.cnblogs.com/bahcelor/p/7277357.html