标签:技术 转化 16px 优点 入栈 编译器 cal 趋势 版本
虚拟机调用方法可以有解析和分派两种方式,那么虚拟机是如何执行方法中的字节码指令的?
1.解释执行
谈是解释执行还是翻译执行没有意义了,只有确定了某种具体的java实现版本和执行引擎运行模式时,谈解释执行还是编译执行才比较贴切。
如今,基于物理机、java虚拟机,或者非Java的其他高级语言虚拟机的语言,大多都会遵循这种基于现代经典编译原理的思路,在执行前先对程序源码进行词法分析和语法分析处理,把源码转化为抽象语法树 。对于一门具体语言的实现来说,词法分析、语法分析以致后面的优化器和目标代码生成器都可以选择独立于执行引擎,形成一个完整意义的编译器趋势线,这类代表是C/C++语言。也可以选择把其中一部分步骤实现为一个半独立的编译期,这类代表是java语言。又或者把这些步骤和执行引擎全部集中封装在一个封闭的黑匣子之中,如大多数的JavaScript执行器。
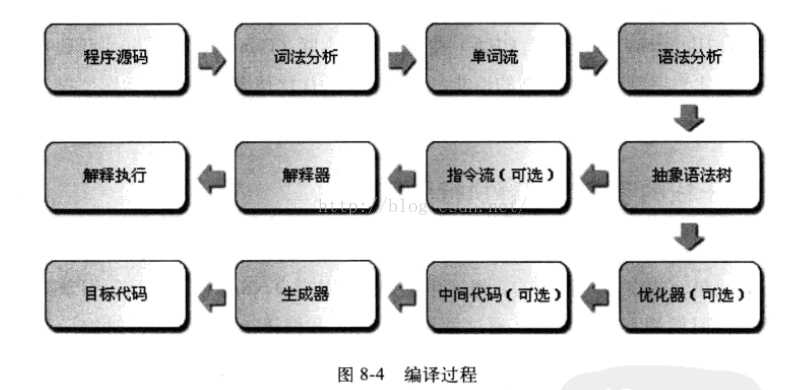
Java语言中,javac编译器完成了程序代码经过词法分析、语法分析到抽象语法树,再遍历语法树生成线性的字节码指令刘的过程。因为这一部分动作是在java虚拟机之外进行的,而解释器在虚拟机内部,所以java程序的编译就是半独立的实现。
2.基于栈的指令集与基于寄存器的指令集
java编译器输出的指令刘,基本上是一种基于栈的指令集架构,指令流之中大部分都会是零地址指令,他们依赖于操作数栈进行工作。与之相对的另外一套常用的指令集架构是基于寄存器的指令集,最典型的就是x86的二进制指令集,也是我们主流PC机中直接支持的指令集架构,这些指令依赖寄存器进行工作。这两种有什么不同?
举个例子:1+1
基于栈的指令集会是:
iconst_1
iconst_1
iadd
istore_0
如果基于寄存器,程序可能是:
mov eax,1
add eax,1
mov指令把EAX寄存器的值设为1,然后add指令再把这个值加1,结果就保存在EAX寄存器里面。
优缺点:
基于栈的指令集主要的优点就是可移植,寄存器由硬件直接提供,程序直接依赖这些硬件寄存器则不可避免地要受到硬件的约束。缺点是执行速度相对来说稍慢一点。
③基于栈的解释器执行过程
public int calc(){ int a=100; int b=200; int c=300; return(a+b)*c; }
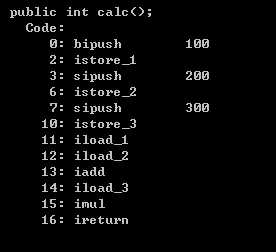
| 执行偏移地址 | 解释 | 程序计数器 | 局部变量表 | 栈顶 |
| 0 | 将100推送到栈顶 | 0 | this | 100 |
| 1 | 将100出栈放到第一个局部变量slot中 | 1 | this 100 | null |
| 11 | 第一个局部变量slot中的数值复制到栈顶 | 11 |
this 100 200 300 |
100 |
| 12 | 第二个局部变量slot中的数值复制到栈顶 | 12 |
this 100 200 300 |
200 |
| 13 | 将200和100出栈,加完之后入栈 | 13 |
this 100 200 300 |
300 |
| 14 | b把300复制到操作数栈中,imul和iadd完全类似,下面省略 | 14 |
this 100 200 300 |
300 |
| 16 | 结束方法并将操作舒展定的整型值返回给此方法的调用者 | 16 |
this 100 200 300 |
90000 |
标签:技术 转化 16px 优点 入栈 编译器 cal 趋势 版本
原文地址:http://www.cnblogs.com/wxw7blog/p/7278369.html