标签:org 判断 分析 调整 head wim code return 中心
算法优势:适用于绝大多数的数据类型,简洁和快速
算法劣势:需要知道准确的 k 值,并且不能处理异形簇,比如球形簇,不同尺寸及密度的簇,环形簇等。
一、分析目标
以数据集字段进行客户分群
二、流程
数据获取,毕业年份、性别、年龄、交友数量、关注的热点词(原本是一个list是否关注了这些运动或者热点词,已经以哑变量展开)
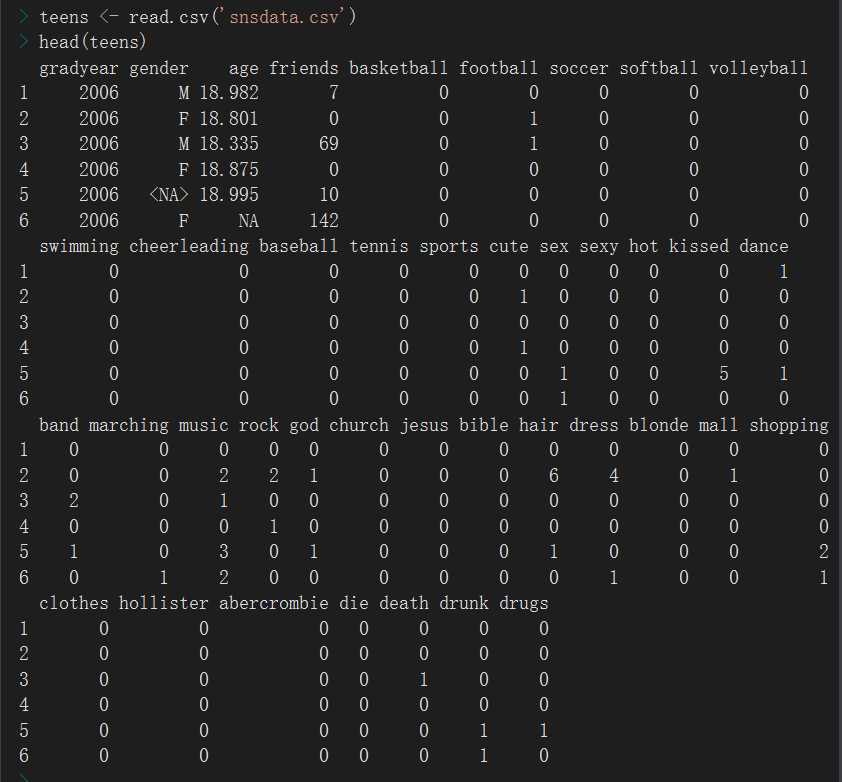
数据探索
确认数据结构:整体都是数值型的,
1、性别是分类变量,这样的话该变量不能被K聚类识别,需要对性别进行哑变量编码
2、数据里边存在缺失
> str(teens) ‘data.frame‘: 30000 obs. of 40 variables: $ gradyear : int 2006 2006 2006 2006 2006 2006 2006 2006 2006 2006 ... $ gender : Factor w/ 2 levels "F","M": 2 1 2 1 NA 1 1 2 1 1 ... $ age : num 19 18.8 18.3 18.9 19 ... $ friends : int 7 0 69 0 10 142 72 17 52 39 ... $ basketball : int 0 0 0 0 0 0 0 0 0 0 ... $ football : int 0 1 1 0 0 0 0 0 0 0 ... $ soccer : int 0 0 0 0 0 0 0 0 0 0 ... $ softball : int 0 0 0 0 0 0 0 1 0 0 ... $ volleyball : int 0 0 0 0 0 0 0 0 0 0 ... $ swimming : int 0 0 0 0 0 0 0 0 0 0 ... $ cheerleading: int 0 0 0 0 0 0 0 0 0 0 ... $ baseball : int 0 0 0 0 0 0 0 0 0 0 ... $ tennis : int 0 0 0 0 0 0 0 0 0 0 ... $ sports : int 0 0 0 0 0 0 0 0 0 0 ... $ cute : int 0 1 0 1 0 0 0 0 0 1 ... $ sex : int 0 0 0 0 1 1 0 2 0 0 ... $ sexy : int 0 0 0 0 0 0 0 1 0 0 ... $ hot : int 0 0 0 0 0 0 0 0 0 1 ... $ kissed : int 0 0 0 0 5 0 0 0 0 0 ... $ dance : int 1 0 0 0 1 0 0 0 0 0 ... $ band : int 0 0 2 0 1 0 1 0 0 0 ... $ marching : int 0 0 0 0 0 1 1 0 0 0 ... $ music : int 0 2 1 0 3 2 0 1 0 1 ... $ rock : int 0 2 0 1 0 0 0 1 0 1 ... $ god : int 0 1 0 0 1 0 0 0 0 6 ... $ church : int 0 0 0 0 0 0 0 0 0 0 ... $ jesus : int 0 0 0 0 0 0 0 0 0 2 ... $ bible : int 0 0 0 0 0 0 0 0 0 0 ... $ hair : int 0 6 0 0 1 0 0 0 0 1 ... $ dress : int 0 4 0 0 0 1 0 0 0 0 ... $ blonde : int 0 0 0 0 0 0 0 0 0 0 ... $ mall : int 0 1 0 0 0 0 2 0 0 0 ... $ shopping : int 0 0 0 0 2 1 0 0 0 1 ... $ clothes : int 0 0 0 0 0 0 0 0 0 0 ... $ hollister : int 0 0 0 0 0 0 2 0 0 0 ... $ abercrombie : int 0 0 0 0 0 0 0 0 0 0 ... $ die : int 0 0 0 0 0 0 0 0 0 0 ... $ death : int 0 0 1 0 0 0 0 0 0 0 ... $ drunk : int 0 0 0 0 1 1 0 0 0 0 ... $ drugs : int 0 0 0 0 1 0 0 0 0 0 ...
查看缺失情况
> summary(teens) gradyear gender age friends basketball Min. :2006 F :22054 Min. : 3.086 Min. : 0.00 Min. : 0.0000 1st Qu.:2007 M : 5222 1st Qu.: 16.312 1st Qu.: 3.00 1st Qu.: 0.0000 Median :2008 NA‘s: 2724 Median : 17.287 Median : 20.00 Median : 0.0000 Mean :2008 Mean : 17.994 Mean : 30.18 Mean : 0.2673 3rd Qu.:2008 3rd Qu.: 18.259 3rd Qu.: 44.00 3rd Qu.: 0.0000 Max. :2009 Max. :106.927 Max. :830.00 Max. :24.0000 NA‘s :5086 football soccer softball volleyball Min. : 0.0000 Min. : 0.0000 Min. : 0.0000 Min. : 0.0000 1st Qu.: 0.0000 1st Qu.: 0.0000 1st Qu.: 0.0000 1st Qu.: 0.0000 Median : 0.0000 Median : 0.0000 Median : 0.0000 Median : 0.0000 Mean : 0.2523 Mean : 0.2228 Mean : 0.1612 Mean : 0.1431 3rd Qu.: 0.0000 3rd Qu.: 0.0000 3rd Qu.: 0.0000 3rd Qu.: 0.0000 Max. :15.0000 Max. :27.0000 Max. :17.0000 Max. :14.0000 swimming cheerleading baseball tennis Min. : 0.0000 Min. :0.0000 Min. : 0.0000 Min. : 0.00000 1st Qu.: 0.0000 1st Qu.:0.0000 1st Qu.: 0.0000 1st Qu.: 0.00000 Median : 0.0000 Median :0.0000 Median : 0.0000 Median : 0.00000 Mean : 0.1344 Mean :0.1066 Mean : 0.1049 Mean : 0.08733 3rd Qu.: 0.0000 3rd Qu.:0.0000 3rd Qu.: 0.0000 3rd Qu.: 0.00000 Max. :31.0000 Max. :9.0000 Max. :16.0000 Max. :15.00000 sports cute sex sexy Min. : 0.00 Min. : 0.0000 Min. : 0.0000 Min. : 0.0000 1st Qu.: 0.00 1st Qu.: 0.0000 1st Qu.: 0.0000 1st Qu.: 0.0000 Median : 0.00 Median : 0.0000 Median : 0.0000 Median : 0.0000 Mean : 0.14 Mean : 0.3229 Mean : 0.2094 Mean : 0.1412 3rd Qu.: 0.00 3rd Qu.: 0.0000 3rd Qu.: 0.0000 3rd Qu.: 0.0000 Max. :12.00 Max. :18.0000 Max. :114.0000 Max. :18.0000 hot kissed dance band Min. : 0.0000 Min. : 0.0000 Min. : 0.0000 Min. : 0.0000 1st Qu.: 0.0000 1st Qu.: 0.0000 1st Qu.: 0.0000 1st Qu.: 0.0000 Median : 0.0000 Median : 0.0000 Median : 0.0000 Median : 0.0000 Mean : 0.1266 Mean : 0.1032 Mean : 0.4252 Mean : 0.2996 3rd Qu.: 0.0000 3rd Qu.: 0.0000 3rd Qu.: 0.0000 3rd Qu.: 0.0000 Max. :10.0000 Max. :26.0000 Max. :30.0000 Max. :66.0000 marching music rock god Min. : 0.0000 Min. : 0.0000 Min. : 0.0000 Min. : 0.0000 1st Qu.: 0.0000 1st Qu.: 0.0000 1st Qu.: 0.0000 1st Qu.: 0.0000 Median : 0.0000 Median : 0.0000 Median : 0.0000 Median : 0.0000 Mean : 0.0406 Mean : 0.7378 Mean : 0.2433 Mean : 0.4653 3rd Qu.: 0.0000 3rd Qu.: 1.0000 3rd Qu.: 0.0000 3rd Qu.: 1.0000 Max. :11.0000 Max. :64.0000 Max. :21.0000 Max. :79.0000 church jesus bible hair Min. : 0.0000 Min. : 0.0000 Min. : 0.00000 Min. : 0.0000 1st Qu.: 0.0000 1st Qu.: 0.0000 1st Qu.: 0.00000 1st Qu.: 0.0000 Median : 0.0000 Median : 0.0000 Median : 0.00000 Median : 0.0000 Mean : 0.2482 Mean : 0.1121 Mean : 0.02133 Mean : 0.4226 3rd Qu.: 0.0000 3rd Qu.: 0.0000 3rd Qu.: 0.00000 3rd Qu.: 0.0000 Max. :44.0000 Max. :30.0000 Max. :11.00000 Max. :37.0000 dress blonde mall shopping Min. :0.000 Min. : 0.0000 Min. : 0.0000 Min. : 0.000 1st Qu.:0.000 1st Qu.: 0.0000 1st Qu.: 0.0000 1st Qu.: 0.000 Median :0.000 Median : 0.0000 Median : 0.0000 Median : 0.000 Mean :0.111 Mean : 0.0989 Mean : 0.2574 Mean : 0.353 3rd Qu.:0.000 3rd Qu.: 0.0000 3rd Qu.: 0.0000 3rd Qu.: 1.000 Max. :9.000 Max. :327.0000 Max. :12.0000 Max. :11.000 clothes hollister abercrombie die Min. :0.0000 Min. :0.00000 Min. :0.00000 Min. : 0.0000 1st Qu.:0.0000 1st Qu.:0.00000 1st Qu.:0.00000 1st Qu.: 0.0000 Median :0.0000 Median :0.00000 Median :0.00000 Median : 0.0000 Mean :0.1485 Mean :0.06987 Mean :0.05117 Mean : 0.1841 3rd Qu.:0.0000 3rd Qu.:0.00000 3rd Qu.:0.00000 3rd Qu.: 0.0000 Max. :8.0000 Max. :9.00000 Max. :8.00000 Max. :22.0000 death drunk drugs Min. : 0.0000 Min. :0.00000 Min. : 0.00000 1st Qu.: 0.0000 1st Qu.:0.00000 1st Qu.: 0.00000 Median : 0.0000 Median :0.00000 Median : 0.00000 Mean : 0.1142 Mean :0.08797 Mean : 0.06043 3rd Qu.: 0.0000 3rd Qu.:0.00000 3rd Qu.: 0.00000 Max. :14.0000 Max. :8.00000 Max. :16.00000
缺失处理
> table(teens$gender,useNA = ‘ifany‘)#返回缺失个数 F M <NA> 22054 5222 2724
> teens$female<-ifelse(teens$gender==‘F‘&!is.na(teens$gender),1,0)#将性别进行哑变量处理,首先将非空的女性赋值为1,NA或者男赋值为0
> teens$no_gender<-ifelse(is.na(teens$gender),1,0)#性别缺失为1,否则为0,这样的话相当于把男女哑变量处理,同时缺失也纳入考量
> teens$gender<-NULL
年龄处理:高中生不可能106岁,也不可能有3岁,同时存在较多缺失
> summary(teens$age) Min. 1st Qu. Median Mean 3rd Qu. Max. NA‘s 3.086 16.310 17.290 17.990 18.260 106.900 5086
> teens$age <- ifelse(teens$age >= 16 & teens$age < 20,teens$age,NA)#将16-20岁视为高中生的正常年龄,其他数据视为异常值为空 > aggregate(data=teens,age~gradyear,mean,na.rm=TRUE)#求不同毕业年份的年龄均值,越最近毕业的人越年轻 gradyear age 1 2006 18.68560 2 2007 17.71878 3 2008 16.78118 4 2009 16.33252
# 按年份生成与原数据集合等长的向量
> ave_age <- ave(teens$age, teens$gradyear, FUN = function(x) { return(mean(x, na.rm = TRUE)) })
> teens$age <- ifelse(is.na(teens$age), ave_age, teens$age)#将NA的年龄赋值为均值,非空的保持原值 > summary(teens$age) Min. 1st Qu. Median Mean 3rd Qu. Max. 16.00 16.33 17.25 17.38 18.22 20.00
数据划分
> interests <- teens[, 4:39]
> interests_z <- data.frame(lapply(interests, scale))#标准化数据,减少量纲差异
k均值建模
set.seed(11)#设定随机种子 teen_clusters <- kmeans(interests_z, 5)
评估模型
> head(teen_clusters$cluster)#聚类标签 [1] 2 1 2 2 5 2 > teen_clusters$size#5个类别的数量 [1] 5233 22182 731 803 1051 > teen_clusters$centers#聚类中心 basketball football soccer softball volleyball swimming cheerleading baseball 1 0.4531058 0.43339400 -0.05953070 0.375996747 0.40342075 0.30482805 0.46479149 0.24682651 2 -0.1290187 -0.12977694 -0.14899365 -0.097191693 -0.10066663 -0.09079804 -0.11397570 -0.06918139 3 0.2457823 0.23577386 5.02937767 0.033589676 0.09057228 0.13165120 -0.02646162 0.03223472 4 -0.1109113 0.03602234 -0.14104152 -0.007481003 -0.07966170 0.04595234 -0.12500102 -0.11042346 5 0.3807668 0.38961431 0.05069711 0.161530303 0.11384059 0.27191272 0.20520869 0.29309699 tennis sports cute sex sexy hot kissed dance 1 0.13565618 0.2229282 0.65570947 0.005138338 0.230127643 0.50391601 -0.02252810 0.55362283 2 -0.04152949 -0.1020853 -0.17622878 -0.094412671 -0.077760392 -0.13325067 -0.13207336 -0.15193168 3 0.11156263 0.3998271 0.01361179 -0.056096990 -0.008332101 0.06411155 -0.06295344 -0.02447142 4 0.01655266 -0.1041384 -0.04851623 -0.046718513 -0.019765548 -0.06929059 -0.06814111 0.02098573 5 0.11082240 0.8460723 0.48219547 2.041764818 0.516256470 0.31165437 2.99550632 0.45107250 band marching music rock god church jesus 1 -0.04813421 -0.12344684 0.26060636 0.18108418 0.3304953087 0.51972951 0.24097725 2 -0.12756333 -0.13513757 -0.13216778 -0.10905451 -0.1001591088 -0.13566360 -0.06601809 3 -0.04525084 -0.09376867 0.04330389 0.09518405 -0.0001367759 0.10922246 0.01664811 4 3.37541403 4.63879117 0.39528646 0.16181449 0.0735799460 0.03691392 0.07066919 5 0.38450719 -0.01216509 1.15977396 1.21019696 0.4122385221 0.17132449 0.12793743 bible hair dress blonde mall shopping clothes 1 0.22258000 0.325589087 0.444453842 0.04528480 0.64138010 0.85834274 0.51465115 2 -0.05930602 -0.198168525 -0.132551874 -0.02830573 -0.17908734 -0.22075867 -0.18246937 3 0.03613298 -0.004854472 0.005732568 0.03146825 0.03512586 0.21142729 -0.04501739 4 0.04788738 -0.041196192 0.049581302 -0.01631323 -0.09605527 -0.06611646 0.01252734 5 0.08173007 2.596190010 0.542753982 0.36251061 0.63523179 0.28896231 1.31038466 hollister abercrombie die death drunk drugs 1 0.57661846 0.557958327 0.043023482 0.12784283 0.01420576 -0.05433707 2 -0.15090261 -0.146583539 -0.089778750 -0.07512888 -0.08530937 -0.11084192 3 0.06677613 0.002922202 -0.003454604 -0.01723961 -0.04902532 -0.04029186 4 -0.15478823 -0.147391253 -0.013624100 0.02928218 -0.08311224 -0.08479959 5 0.38568876 0.426202832 1.693430840 0.93872106 1.82737429 2.70274859
将聚类标签赋值回原记录,在本博文SPSS实例中SPSS聚类之后的结果也会生成新列,便于针对目标类别进行进一步特征提取
> names(teens) [1] "gradyear" "age" "friends" "basketball" "football" "soccer" [7] "softball" "volleyball" "swimming" "cheerleading" "baseball" "tennis" [13] "sports" "cute" "sex" "sexy" "hot" "kissed" [19] "dance" "band" "marching" "music" "rock" "god" [25] "church" "jesus" "bible" "hair" "dress" "blonde" [31] "mall" "shopping" "clothes" "hollister" "abercrombie" "die" [37] "death" "drunk" "drugs" "no_gender" "female" > teens$cluster <- teen_clusters$cluster > teens[1:5, c("cluster", "female", "no_gender", "age", "friends")] cluster female no_gender age friends 1 2 0 0 18.982 7 2 1 1 0 18.801 0 3 2 0 0 18.335 69 4 2 1 0 18.875 0 5 5 0 1 18.995 10
特征查看
cluster female no_gender age friends 1 2 0 0 18.982 7 2 1 1 0 18.801 0 3 2 0 0 18.335 69 4 2 1 0 18.875 0 5 5 0 1 18.995 10 > aggregate(data = teens, age ~ cluster, mean)#年龄区分度较小 cluster age 1 1 17.19971 2 2 17.43109 3 3 17.16270 4 4 17.47728 5 5 17.26249 > aggregate(data = teens, female ~ cluster, mean) cluster female 1 1 0.8696732 2 2 0.6995312 3 3 0.7633379 4 4 0.7272727 5 5 0.8030447 > aggregate(data = teens, friends ~ cluster, mean)# cluster friends 1 1 39.05828 2 2 27.78077 3 3 35.73735 4 4 32.95392 5 5 30.61180
优化模型,调整K
> set.seed(11) > teen_clusters <- kmeans(interests_z, 10) > teens$cluster <- teen_clusters$cluster
> table(teens$cluster) 1 2 3 4 5 6 7 8 9 10 424 540 1993 2478 680 519 856 1917 996 19597 > data.frame(aggregate(data = teens, football ~ cluster, mean), aggregate(data = teens, friends ~ cluster, mean), aggregate(data = teens, basketball ~ cluster, mean)) cluster football cluster.1 friends cluster.2 basketball 1 1 0.2900943 1 35.01179 1 0.3584906 2 2 0.2611111 2 35.24815 2 0.3425926 3 3 0.2483693 3 33.29704 3 0.2498746 4 4 0.4293785 4 39.57143 4 0.3950767 5 5 0.3941176 5 35.54265 5 0.4235294 6 6 1.2215800 6 32.96532 6 0.9441233 7 7 0.5537383 7 30.65070 7 0.5911215 8 8 0.2008346 8 32.38341 8 0.2034429 9 9 0.4608434 9 40.26506 9 1.0923695 10 10 0.1799255 10 27.42195 10 0.1757412 > names(teens) [1] "gradyear" "age" "friends" "basketball" "football" "soccer" [7] "softball" "volleyball" "swimming" "cheerleading" "baseball" "tennis" [13] "sports" "cute" "sex" "sexy" "hot" "kissed" [19] "dance" "band" "marching" "music" "rock" "god" [25] "church" "jesus" "bible" "hair" "dress" "blonde" [31] "mall" "shopping" "clothes" "hollister" "abercrombie" "die" [37] "death" "drunk" "drugs" "female" "no_gender" "cluster" > data.frame(aggregate(data = teens, soccer ~ cluster, mean), aggregate(data = teens, softball ~ cluster, mean), aggregate(data = teens, volleyball ~ cluster, mean)) cluster soccer cluster.1 softball cluster.2 volleyball 1 1 0.16273585 1 0.15094340 1 0.11556604 2 2 0.16851852 2 0.14629630 2 0.12407407 3 3 0.15805319 3 0.09081786 3 0.12995484 4 4 0.16384181 4 0.12227603 4 0.13841808 5 5 4.94264706 5 0.11764706 5 0.13823529 6 6 0.31791908 6 0.21965318 6 0.10789981 7 7 0.26752336 7 0.23481308 7 0.19742991 8 8 0.09911320 8 0.08242045 8 0.07563902 9 9 0.19076305 9 2.55522088 9 1.99899598 10 10 0.08506404 10 0.05669235 10 0.05720263
可以看到每个类中不同变量的均值情况,可以手动将相似的进行合并,例如1、2中交友数量这个角度1、2、5都很接近,而soccer角度1、2、4又很接近,可以将所有的变量的均值进行查看判断进行人工合并分类。
仅对聚类算法的使用做一个练习,有不妥之处望指教,学习体验是:学无止境......永远有不确定的地方,永远有不懂的东西......刺激又恐慌
标签:org 判断 分析 调整 head wim code return 中心
原文地址:http://www.cnblogs.com/keepgoingon/p/7282216.html