标签:完全 阶段 extends 创建 hba 拓扑 相等 java 语义
对于容错机制,Storm通过一个系统级别的组件acker,结合xor校验机制判断一个msg是否发送成功,进而spout可以重发该msg,保证一个msg在出错的情况下至少被重发一次。但是在一些事务性要求比较高的场景中,需要保障一次只有一次的语义,比如需要精确统计tuple的数量等等,torm0.7.0实现了一个新特性---事务性拓扑,这一特性使消息在语义上确保你可以安全的方式重发消息,并保证它们只会被处理一次。在不支持事务性拓扑的情况下,你无法在准确性,可扩展性,以空错性上得到保证的前提下完成计算。
在事务性拓扑中,Storm以并行和顺序处理混合的方式处理元组。spout并行分批创建供bolt处理的元组。其中一些bolt作为提交者以严格有序的方式提交处理过的批次。这意味着如果你有每批五个元组的两个批次,将有两个元组被bolt并行处理,但是直到提交者成功提交了第一个元组之后,才会提交第二个元组。使用事务性拓扑时,数据源要能够重发批次,有时候甚至要重复多次。因此确认你的数据源——你连接到的那个spout——具备这个能力。 这个过程可以被描述为两个阶段: 处理阶段--纯并行阶段,许多批次同时处理。 提交阶段--严格有序阶段,直到批次一成功提交之后,才会提交批次二。 这两个阶段合起来称为一个Storm事务。Storm使用zookeeper储存事务元数据,默认情况下就是拓扑使用的那个zookeeper。你可以修改以下两个配置参数键指定其它的zookeeper——transactional.zookeeper.servers和transactional.zookeeper.port。
(1) 对于一次只有一次的语义,从原理上来讲,需要在发送tuple的时候带上事务id,在需要事务处理的时候,根据该tid是否以前已经处理成功来决定是否进行处理,当然需要把tid和处理结果一起做保存,并且需要保障顺序性,在当前请求tid提交前,确保所有比自己低tid请求都已经提交。
在事务处理时单个处理tuple效率比较低,因此storm中引入batch处理,一批tuple赋予一个tid,为了提高batch之间处理的并行度,storm采用了pipeline 处理的模型。参见下图pipeline模型,多个事务可以并行执行,但是commit的是严格按照顺序的。
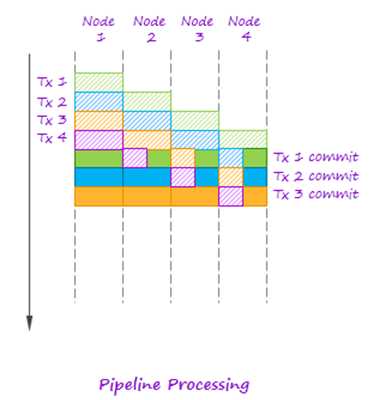
对应到storm中的具体实现中,把一个batch的计算分成了两个阶段processing和commit阶段:
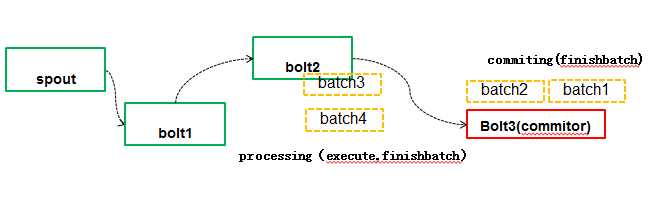
Processing阶段:多个batch可以并行计算,上面例子中bolt2是普通的batchbolt(实现BaseBatchBolt),那么多个batch在bolt2的task之间可以并行执行,比如对batch3和batch4并行执行execute或finishbatch(什么时候调用该操作,后面会介绍)方法。
Commiting阶段:batch之间强制按照顺序进行提交,上图中Bolt3实现BaseBatchBolt并且标记需要事务处理的(实现了ICommitter接口或者通过TransactionalTopologyBuilder的setCommitterBolt方法把BatchBolt添加到topology里面),那么在Storm认为可以提交batch的时候调用finishbatch,在finishBatch做tid的比较以及状态保存工作,例子中batch2必须等待batch1提交后,才可以进行提交。
当使用Transactional Topologies的时候, storm为你做下面这些事情:
事务性topology从实现上来讲,包括事务性的spout,以及事务性的bolt。
(2) 事务性的spout需要实现ITransactionalSpout,这个接口包含两个内部类Coordinator和Emitter,在topology运行的时候,事务性的spout内部包含一个子的topology,类似下面这个结构:
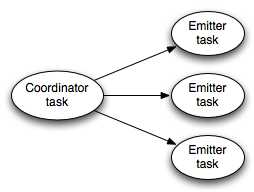
其中coordinator是spout,emitter是bolt。这里面有两种类型的tuple,一种是事务性的tuple,一种是真实batch中的tuple;coordinator为事务性batch发射tuple,Emitter负责为每个batch实际发射tuple。
具体如下:
*****说明******
TransactionalTopology里发送的tuple都必须以TransactionAttempt作为第一个field,storm根据这个field来判断tuple属于哪一个batch。
TransactionAttempt包含两个值:一个transaction id,一个attempt id。transaction id的作用就是我们上面介绍的对于每个batch中的tuple是唯一的,而且不管这个batch replay多少次都是一样的。attempt id是对于每个batch唯一的一个id, 但是对于同一个batch,它replay之后的attempt id跟replay之前就不一样了,我们可以把attempt id理解成replay-times, storm利用这个id来区别一个batch发射的tuple的不同版本
metadata(元数据)中包含当前事务可以从哪个point进行重放数据,存放在zookeeper中的,spout可以通过Kryo从zookeeper中序列化和反序列化该元数据。
**************
(3) 事务性的Bolt继承BaseTransactionalBolt,处理batch在一起的tuples,对于每一个tuple调用调用execute方法,而在整个batch处理(processing)完成的时候调用finishBatch方法。如果BatchBolt被标记成Committer,则只能在commit阶段调用finishBolt方法。一个batch的commit阶段由storm保证只在前一个batch成功提交之后才会执行。并且它会重试直到topology里面的所有bolt在commit完成提交。那么如何知道batch的processing完成了,也就是bolt是否接收处理了batch里面所有的tuple;在bolt内部,有一个CoordinatedBolt的模型。CoordinateBolt具体原理如下:
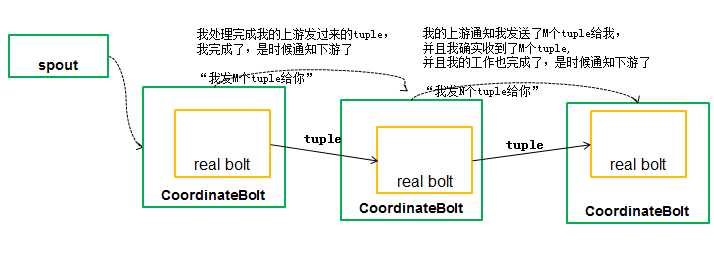
CoordinateBolt具体原理如下:
事务性的拓扑在storm中的一个应用是Trident,它是在storm的原语和事务性的基础上做更高层次的抽象,做到一致性和恰好一次的语义,后续章节会对trident做分析。
根据storm的事务原理,统计网站每天的访问量,仅为了说明概念,数据采用自制。
(1)TransSpout

1 package com.dxss.storm.transaction; 2 3 import java.util.HashMap; 4 import java.util.Map; 5 import com.dsxx.storm.sql.utils.CreateData; 6 import backtype.storm.task.TopologyContext; 7 import backtype.storm.topology.OutputFieldsDeclarer; 8 import backtype.storm.transactional.ITransactionalSpout; 9 import backtype.storm.tuple.Fields; 10 11 /** 12 * 13 * @ClassName: TransSpout 14 * @Description: Storm的事务性操作,ITransactionalSpout 获取数据并向拓扑分发批次, 15 * 泛型MyMata(元数据: 包含当前事务可以从哪个point进行重发数据,放在zookeeper中的,spout可以通过kryo从 16 * zookeeper中序列化和反序列化该元数据 17 * )是事务元数据集合,用户从数据源分发批次 18 * @author: hadoop 19 * @date: 2017年8月4日 下午7:46:11 20 * 21 */ 22 public class TransSpout implements ITransactionalSpout<MyMata>{ 23 private Map<Long,String> map = new HashMap<Long,String>(); 24 @Override 25 public void declareOutputFields(OutputFieldsDeclarer arg0) { 26 arg0.declare(new Fields("atemptId","message")); 27 } 28 29 @Override 30 public Map<String, Object> getComponentConfiguration() { 31 return null; 32 } 33 34 /** 35 * 告诉storm用来协调生成批次的类, 36 */ 37 @Override 38 public backtype.storm.transactional.ITransactionalSpout.Coordinator<MyMata> getCoordinator(Map arg0, 39 TopologyContext arg1) { 40 // TODO Auto-generated method stub 41 return new MyCoordinator(); 42 } 43 44 /** 45 * 负责读取批次并把它们分发到拓扑中的数据流组 46 */ 47 @SuppressWarnings("unchecked") 48 @Override 49 public backtype.storm.transactional.ITransactionalSpout.Emitter<MyMata> getEmitter(Map arg0, TopologyContext arg1) { 50 return new MyEmitter(CreateData.getMapData(100L)); 51 } 52 53 }
Storm的事务性操作,TransactionalSpout 获取数据并向拓扑分发批次,泛型MyMata(元数据: 包含当前事务可以从哪个point进行重发数据,放在zookeeper中的,spout可以通过kryo从zookeeper中序列化和反序列化该元数据)是事务元数据集合,用户从数据源分发批次
(2)MyCoordinator
package com.dxss.storm.transaction; import java.math.BigInteger; import backtype.storm.transactional.ITransactionalSpout.Coordinator; import backtype.storm.utils.Utils; public class MyCoordinator implements Coordinator<MyMata>{ private static final Integer BATCH_NUM = 10; @Override public void close() { } /** * 启动事务,生成元数据。接收 * txid:storm生成的事务ID,作为批次的唯一性标识 * arg1: 协调器生成的前一个事务元数据对象 * 元组一经返回,storm把myMata和txid一起保存在zookeeper,确保一旦发生故障,storm可以利用分发器重新发送批次 */ @Override public MyMata initializeTransaction(BigInteger txid, MyMata arg1) { // arg0 : 事务ID ,启动事务ID,默认从0开始 // arg1 : 上一个元数据的位置 long beginPoint = 0L; if (arg1 == null){ beginPoint = 0; }else{ beginPoint = arg1.getBeginPoint() + arg1.getNum(); } MyMata myMata = new MyMata(); myMata.setBeginPoint(beginPoint); myMata.setNum(BATCH_NUM); System.err.println("启动一个事务:"+ myMata.toString()); return myMata ; } /** * 使用它来确认数据源已经就绪并可读取 */ @Override public boolean isReady() { Utils.sleep(2000); return true; } }
负责启动事务,生成元数据。接收
txid:storm生成的事务ID,作为批次的唯一性标识
arg1: 协调器生成的前一个事务元数据对象
元组一经返回,storm把myMata和txid一起保存在zookeeper,确保一旦发生故障,storm可以利用分发器重新发送批次
(3)Emitter
package com.dxss.storm.transaction; import java.math.BigInteger; import java.util.HashMap; import java.util.Map; import backtype.storm.coordination.BatchOutputCollector; import backtype.storm.transactional.ITransactionalSpout.Emitter; import backtype.storm.transactional.TransactionAttempt; import backtype.storm.tuple.Values; /** * * @ClassName: MyEmitter 分发器,从数据源读取数据,并从数据流组发送数据,分发器可以为相同的事务id和事务元数据发送相同的批次,如果出现故障,storm 发送相同的事务id和事务元数据,并确保批次已经重复过了,storm会在TransactionAttempt对象里为 这样就知道批次已经重复过了 p * @date: 2017年8月5日 下午2:19:30 * */ public class MyEmitter implements Emitter<MyMata>{ private Map<Long,String> map = null; public MyEmitter(Map<Long, String> map2) { this.map = map2; } @Override public void cleanupBefore(BigInteger arg0) { // TODO Auto-generated method stub } @Override public void close() { // TODO Auto-generated method stub } /** * 从传入的元数据对象中获取原始消息进行发送,利用传入的MyMata元数据对象从map(消息源)中获取数据进行发送,同时增加map * 维持的已读消息数 */ @Override public void emitBatch(TransactionAttempt arg0, MyMata arg1, BatchOutputCollector arg2) { // 从某一位置获取原始消息进行发送 long beginPoint = arg1.getBeginPoint(); int num = arg1.getNum(); for (long i=beginPoint;i<(num+beginPoint);i++){ if (this.map.get(i)==null){ break; } arg2.emit(new Values(arg0,this.map.get(i))); } } }
分发器,从数据源读取数据,并从数据流组发送数据,分发器可以为相同的事务id和事务元数据发送相同的批次,如果出现故障,storm发送相同的事务id和事务元数据,并确保批次已经重复过了,storm会在TransactionAttempt对象里为这样就知道批次已经重复过了
(4)Bolt
package com.dxss.storm.transaction; import java.util.Map; import backtype.storm.coordination.BatchOutputCollector; import backtype.storm.task.TopologyContext; import backtype.storm.topology.OutputFieldsDeclarer; import backtype.storm.topology.base.BaseTransactionalBolt; import backtype.storm.transactional.TransactionAttempt; import backtype.storm.tuple.Fields; import backtype.storm.tuple.Tuple; import backtype.storm.tuple.Values; @SuppressWarnings("serial") public class TransBolt extends BaseTransactionalBolt{ private BatchOutputCollector collector; private TransactionAttempt arg3 = null; private Integer count = 0; /** * execute 操作接收到的元组,但是不会分发新的元组,批次执行完成后,storm会调用finishBatch方法 */ @Override public void execute(Tuple arg0) { arg3 = (TransactionAttempt) arg0.getValue(0); System.out.println("MyTransactionBolt类中execute方法的事务ID是:"+ arg3.getTransactionId() + " attemptid"+arg3.getAttemptId() ); String message = arg0.getString(1); if (message != null){ count ++; } } /** * 批次执行完成后,storm会调用finishBatch方法,可以多线程并发处理,有几条线程,每条线程的批次处理完成后,就会调用该方法 */ @Override public void finishBatch() { System.err.println("FinishBatch的执行次数为:" + count); this.collector.emit(new Values(this.arg3,count)); } @Override public void prepare(Map arg0, TopologyContext arg1, BatchOutputCollector arg2, TransactionAttempt arg3) { System.err.println("MyTransactionBolt类中prepare方法的事务ID是:"+ arg3.getAttemptId()); this.arg3 = arg3; this.collector = arg2; } @Override public void declareOutputFields(OutputFieldsDeclarer arg0) { arg0.declare(new Fields("tx","count")); } }
execute 操作接收到的元组,但是不会分发新的元组,批次执行完成后,storm会调用finishBatch方法
(5)Commit
package com.dxss.storm.transaction; import java.math.BigInteger; import java.util.HashMap; import java.util.Map; import backtype.storm.coordination.BatchOutputCollector; import backtype.storm.task.TopologyContext; import backtype.storm.topology.OutputFieldsDeclarer; import backtype.storm.topology.base.BaseTransactionalBolt; import backtype.storm.transactional.ICommitter; import backtype.storm.transactional.TransactionAttempt; import backtype.storm.tuple.Tuple; @SuppressWarnings("serial") public class MyCommit extends BaseTransactionalBolt implements ICommitter{ private static Map<String,DbValue> map = new HashMap<String,DbValue>(); private Integer num = 0; private static final String GLOBAL_KEY = "GLOBAL_KEY"; private TransactionAttempt arg3 ; class DbValue{ private BigInteger txid ; int count = 0; public BigInteger getTxid() { return txid; } public void setTxid(BigInteger txid) { this.txid = txid; } public int getCount() { return count; } public void setCount(int count) { this.count = count; } } @Override public void execute(Tuple arg0) { this.num += arg0.getInteger(1); } /** * finishBatch 在提交就绪时执行,这一点发生在所有事务都已经成功提交之后,另外,finishBatch是顺序执行的,如果 * 同时有事务ID1和事务ID2两个事务同时执行,只有在ID1没有差错的执行了finishBatch方法之后,ID2才会执行该方法 */ @SuppressWarnings("static-access") @Override public void finishBatch() { DbValue dbValue = this.map.get(GLOBAL_KEY); DbValue newDbValue = null; if (dbValue == null || !dbValue.txid.equals(this.arg3.getAttemptId())){ //更新数据库 newDbValue = new DbValue(); newDbValue.txid = this.arg3.getTransactionId(); if (dbValue == null){ newDbValue.count = num; }else{ newDbValue.count = dbValue.count + num; } this.map.put(GLOBAL_KEY, newDbValue); }else{ newDbValue = dbValue; } System.err.println("total===================:"+this.map.get(GLOBAL_KEY).getCount()); } @Override public void prepare(Map arg0, TopologyContext arg1, BatchOutputCollector arg2, TransactionAttempt arg3) { this.arg3 = arg3; } @Override public void declareOutputFields(OutputFieldsDeclarer arg0) { } }
finishBatch 在提交就绪时执行,这一点发生在所有事务都已经成功提交之后,另外,finishBatch是顺序执行的,如果同时有事务ID1和事务ID2两个事务同时执行,只有在ID1没有差错的执行了finishBatch方法之后,ID2才会执行该方法
以上storm原理部分转自:http://blog.csdn.net/yangbutao/article/details/17844799 真心感谢楼主总结,总结的很好!
标签:完全 阶段 extends 创建 hba 拓扑 相等 java 语义
原文地址:http://www.cnblogs.com/sunfie/p/7300966.html
