标签:字节 计划 nic 解决 width art should xxx where
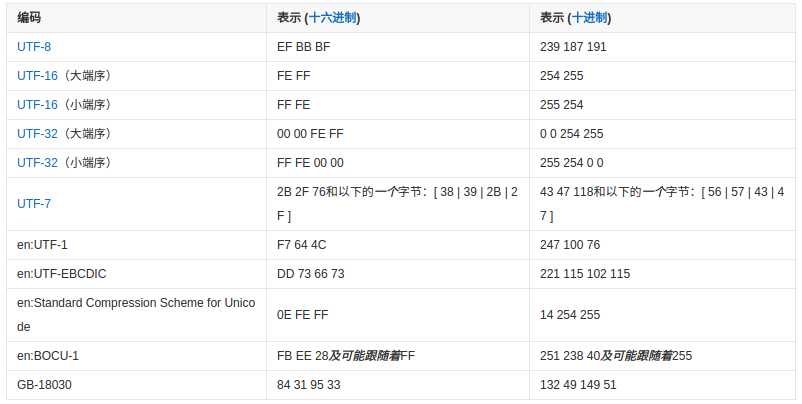
PHP并不会忽略UTF-8文件的BOM,所以在读取、包含或者引用这些文件时,会把BOM作为该文件开头正文的一部分。因此,PHP文件采用UTF-8编码时可保存无BOM格式。
如果U+FEFF出现在数据流中,该怎么办呢?下面这段来自Wikipedia,关于Word Joiner(WJ, U+2060):
The word joiner replaces the zero-width no-break space (ZWNBSP), a deprecated use of the Unicode character at code point U+FEFF. Character U+FEFF is intended for use as a Byte Order Mark at the start of a file. However, if encountered elsewhere it should, according to Unicode, be treated as a "zero-width non-breaking space." The deliberate use of U+FEFF for this purpose is deprecated as of Unicode 3.2, with the word joiner strongly preferred.
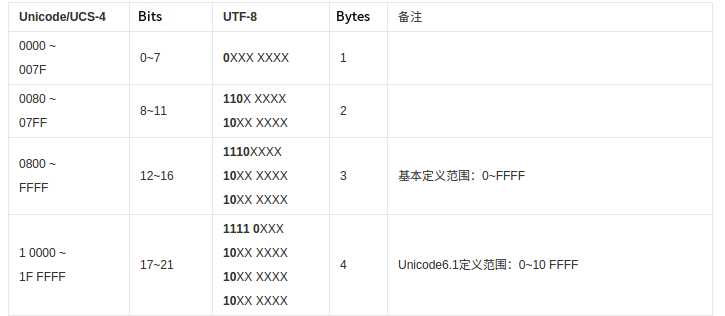
另外,以下部分非Unicode编码范围,属于UCS-4 编码早期的规范: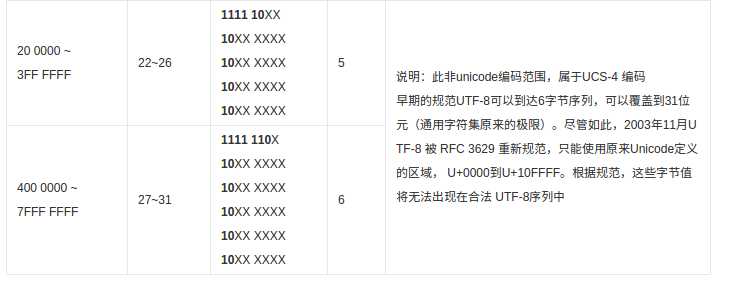
UTF-8用1个字节(U+0000~U+007F)来编码所有ASCII字符,并且与ASCII字符表示是一样的,故其与ASCII兼容,但那些ISO Latin-1扩展ASCII字符集的字符(128~255)是UNICODE的子集,但不是UTF-8的子集;其他的字符UTF-8编码将需要2~4个字节,首字节连续的1的个数表示字符编码所需的字节数。“编”的Unicode编码是U+7F16,因此UTF-8需要3个字节来表示,形如1110xxxx 10xxxxxx 10xxxxxx这种格式。
由于UTF-8采用的是变长字符编码,与UTF-16和UTF-32相比,无论是计算字符数,还是执行索引操作效率都不高,因此UTF-8适合在传输数据中使用,在数据接收完毕后将其转换为UTF-16或UTF-32进行处理,最后再转换回UTF-8(但这写转换本身也会有性能损耗);但UTF-8空间足够大,无字节序问题,且容错性高,局部的字节错误(丢失、增加、改变)不会导致连锁性的错误,因为 UTF-8 的字符边界很容易检测出来
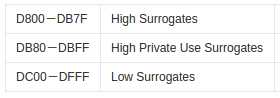
High Surrogates就是指这个范围的码位是Unicode字符4字节UTF-16编码的头两个字节;Low Surrogates就是指这个范围的码位是Unicode字符4字节UTF-16编码的后两个字节;High Private Use Surrogates是指这个范围的码位是Unicode字符4字节UTF-16编码的头两个字节,但该Unicode字符属于平面15和平面16这两个专用区
Unicode 与 Unicode Transformation Format(UTF-8 / UTF-16 / UTF-32)
标签:字节 计划 nic 解决 width art should xxx where
原文地址:http://www.cnblogs.com/XiongMaoMengNan/p/7294686.html