标签:font gis sse inf loss rod class size cal
Generalized linear models with nonlinear feature transformations are widely used for large-scale regression and classification problems with sparse inputs. Memorization of feature interactions through a wide set of cross-product feature transformations are effective and interpretable, while generalization requires more feature engineering effort.
With less feature engineering, deep neural networks can generalize better to unseen feature combinations through low-dimensional dense embeddings learned for the sparse features. However, deep neural networks with embeddings can over-generalize。
Wide & Deep learning—jointly trained wide linear models and deep neural networks—to combine the benefits of memorization and generalization for recommender systems.
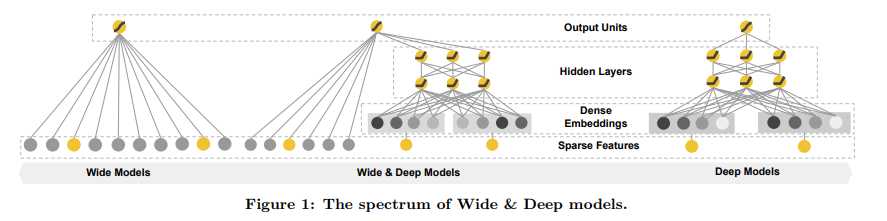
The Wide Component
The wide component is a generalized linear model of the form $y = w^T x + b$, as illustrated in Figure 1 (left). y is the prediction, $x = [x_1, x_2, ..., x_d] $ is a vector of d features, $w = [w_1, w_2, ..., w_d]$ are the model parameters and b is the bias. The feature set includes raw input features and transformed features(比如组合特征).
The Deep Component
The deep component is a feed-forward neural network, as shown in Figure 1 (right). For categorical features, the original inputs are feature strings (e.g., “language=en”). Each of these sparse, high-dimensional categorical features are first converted into a low-dimensional and dense real-valued vector, often referred to as an embedding vector. The dimensionality of the embeddings are usually on the order of O(10) to O(100). The embedding vectors are initialized randomly and then the values are trained to minimize the final loss function during model training. These low-dimensional dense embedding vectors are then fed into the hidden layers of a neural network in the forward pass. Specifically, each hidden layer performs the following computation:
$a ^{(l+1)} = f(W^{(l)} a ^{(l)} + b^ {(l)} )$
where l is the layer number and f is the activation function, often rectified linear units (ReLUs). $a^{(l)} , b^{(l)} , and W^{(l)} $ are the activations, bias, and model weights at l-th layer.
Joint Training of Wide & Deep Model
The wide component and deep component are combined using a weighted sum of their output log odds as the prediction, which is then fed to one common logistic loss function for joint training. Note that there is a distinction between joint training and ensemble. In an ensemble, individual models are trained separately without knowing each other, and their predictions are combined only at inference time but not at training time. In contrast, joint training optimizes all parameters simultaneously by taking both the wide and deep part as well as the weights of their sum into account at training time. for joint training the wide part only needs to complement the weaknesses of the deep part with a small number of cross-product feature transformations, rather than a full-size wide model.
Joint training of a Wide & Deep Model is done by backpropagating the gradients from the output to both the wide and deep part of the model simultaneously using mini-batch stochastic optimization. In the experiments, we used Followthe-regularized-leader (FTRL) algorithm [3] with L1 regularization as the optimizer for the wide part of the model, and AdaGrad [1] for the deep part.
The combined model is illustrated in Figure 1 (center). For a logistic regression problem, the model’s prediction is:
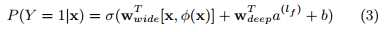
where Y is the binary class label, σ(·) is the sigmoid function, φ(x) are the cross product transformations of the original features x, and b is the bias term. $w_{wide}$ is the vector of all wide model weights, and $w_{deep}$ are the weights applied on the final activations $a^{(lf)}$ .
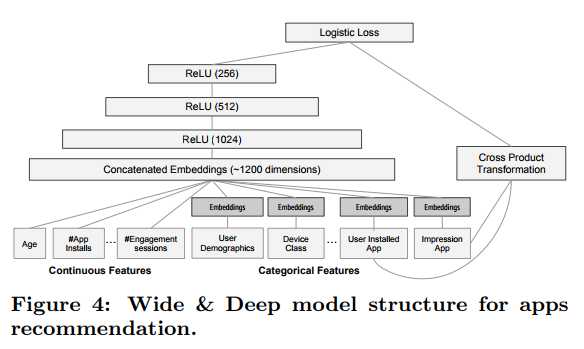
http://www.datakit.cn/blog/2016/08/21/wdnn.html
标签:font gis sse inf loss rod class size cal
原文地址:http://www.cnblogs.com/ljygoodgoodstudydaydayup/p/7306510.html