标签:asn out img getc 解析 public except iterator style
XML解析器在解析XML文档时,把XML文件的各部分内容封装成对象,通过这些对象来操作XML文档,这种做法就DOM解析。以contact.xml为例

<?xml version="1.0" encoding="utf-8"?>
<contactList>
<contact id="001">
<name>张三</name>
<age>20</age>
<phone>134222223333</phone>
<email>zhangsan@qq.com</email>
<qq>432221111</qq>
</contact>
<contact id="003">
<name>lisi</name>
<age>20</age>
<phone>134222225555</phone>
<email>lisi@qq.com</email>
<qq>432222222</qq>
</contact>
</contactList>
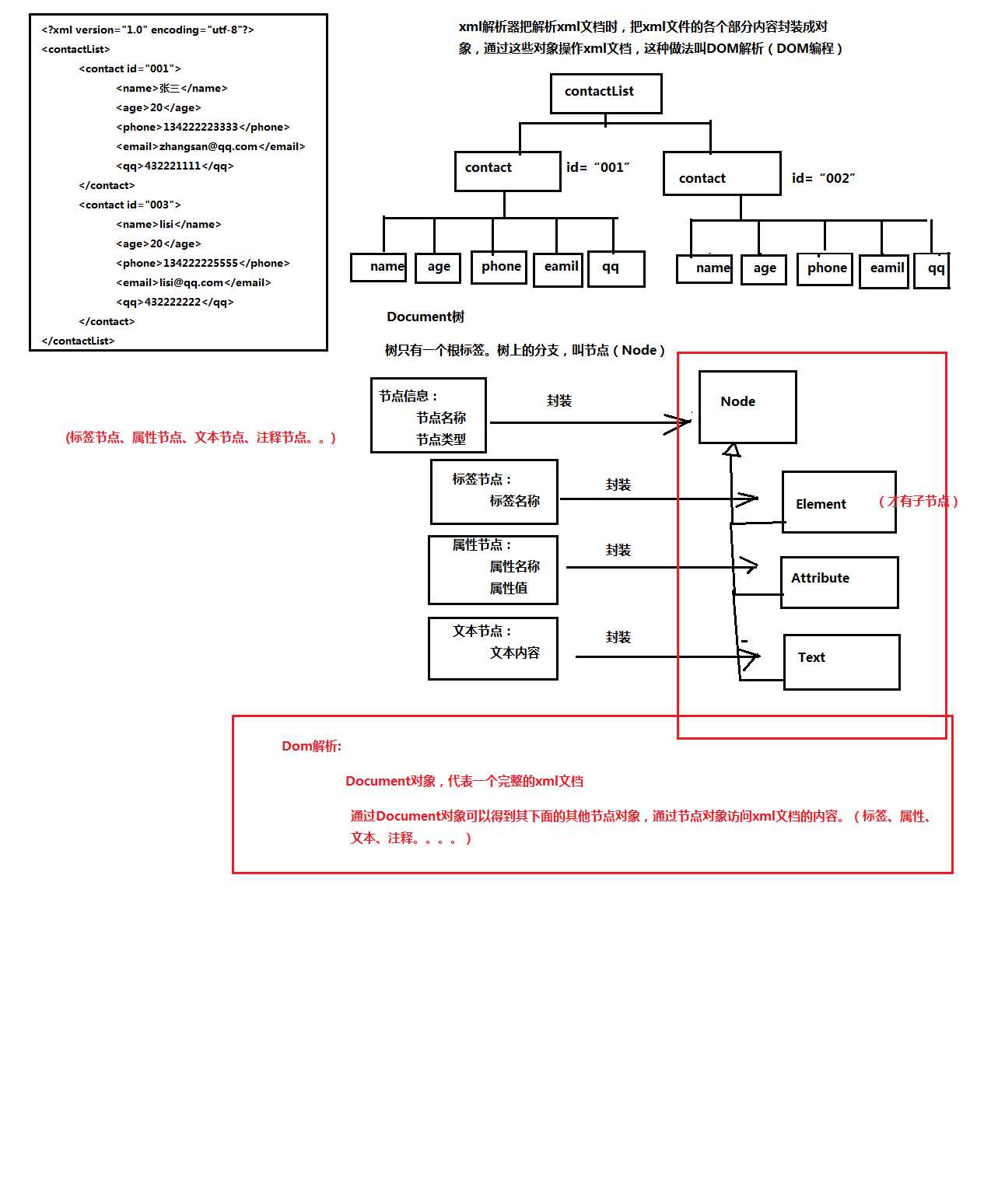 属性,文本都是没有子标签的,只有Element才有子标签。Demo.java利用递归取一个标签下的子节点(写的不是很好,欢迎指出问题 :) )
属性,文本都是没有子标签的,只有Element才有子标签。Demo.java利用递归取一个标签下的子节点(写的不是很好,欢迎指出问题 :) )
package zdc.dom4j.xml; import java.util.Iterator; import org.dom4j.Document; import org.dom4j.Element; import org.dom4j.Node; import org.dom4j.io.SAXReader; import org.junit.Test; public class Demo { @Test public void getNodes() throws Exception { SAXReader read = new SAXReader(); Document doc = read.read("./src/contact.xml"); Element rootElem = doc.getRootElement();//获取根节点 getChildNodes(rootElem); } public void getChildNodes(Element elem) { System.out.println(elem.getName()); //得到子节点 Iterator<Element> it = elem.nodeIterator(); while(it.hasNext()) { Node node = it.next(); //判断子节点node是否为ELement if(node instanceof Element) { //instanceof运算符用来在运行时指出对象是否是特定类的一个实例。 Element element = (Element)node; getChildNodes(element);//递归继续取 } } } }
列举一些修改的方法
List<Element> list = rootElem.elements(); /*得到当前标签下所有的子标签,另外一个是另外一个是rootElem. elementIterator("contact"),需要指定子标签名, 局限性很大,比如contactList下有个<zdc>子标签 。*/ //修改xml文档的API //增加: DucumentHelper.createDocument();//增加文档 addElement("名称");//增加标签 addAttribute("名称","值");//增加属性 //修改 Attribute.setValue("值");//修改属性值 Element.addAttribute("同名的属性名","值");//修改同名的属性值 Element.setText("内容");//修改文本内容 //删除 Element.detach();//删除标签 Attribute.detach();//删除属性
标签:asn out img getc 解析 public except iterator style
原文地址:http://www.cnblogs.com/zdc1996/p/7324896.html
