标签:sdn load origin 学习 分享 toe learn 解码器 width
聚类
K均值
PCA主成分分析
等

类似于一个自学习式PCA,如果编码/解码器只是单层线性的话
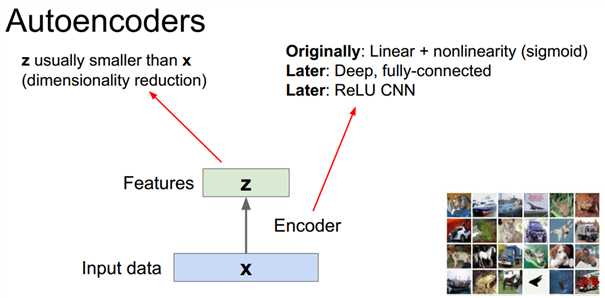
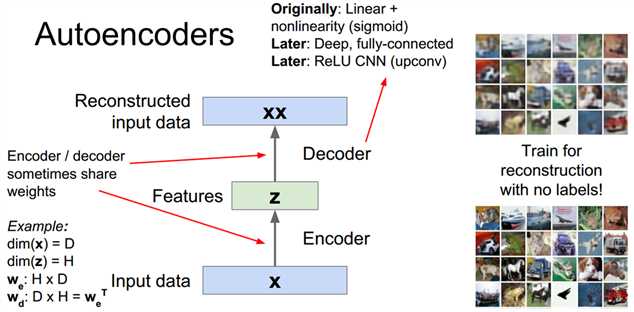
自编码器编码解码示意图:
特征提取过程中甚至用到了卷积网络+relu的结构(我的认知停留在Originally级别)
编码&解码器可以共享权值(在我接触的代码中一般都没共享权值)
损失函数推荐L2
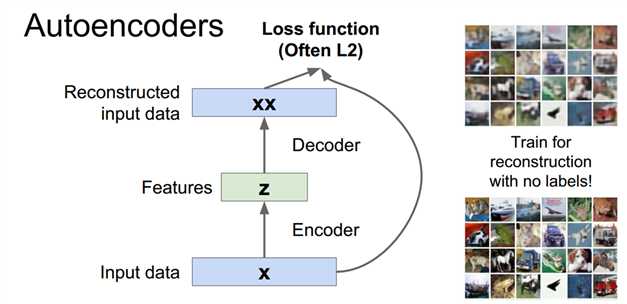
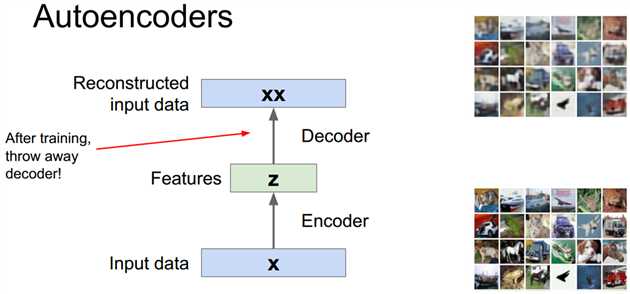
由于重建已知数据是个没什么用的过程,所以自编码器一般在训练后会丢掉解码过程作为一个特征提取工具,
这里的思路是当我们有少量含标签数据以及大量无标签数据时,可以采用使用无标签数据训练自编码器,然后使用训练好的编码器加上分类器去提取有标签数据并训练分类器,不过现实可能不太好,这是老师的评价:


下图表示的是有标签数据经过训练好的网络训练过程,
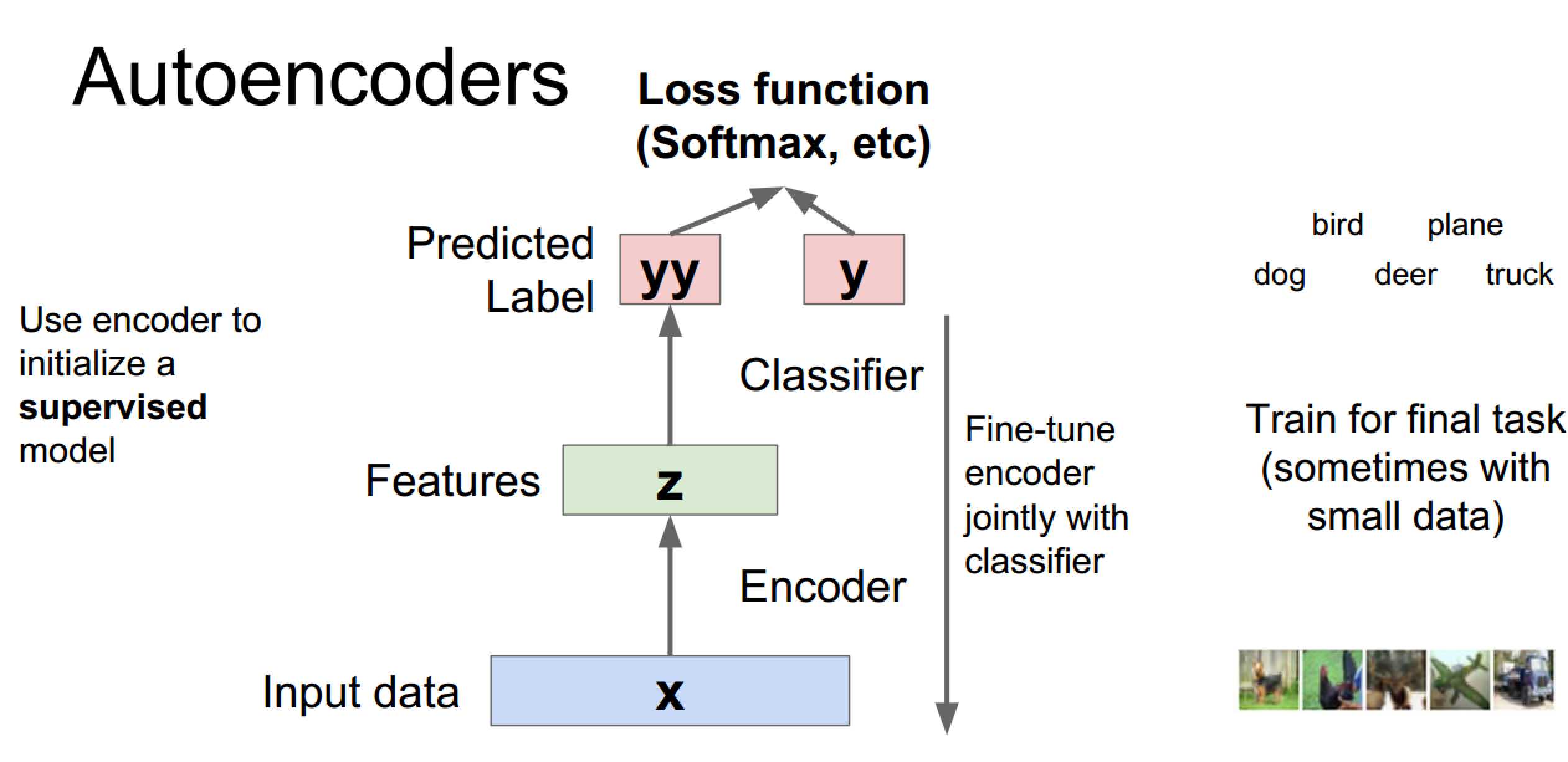
通过监督学习进行微调,也分两种,一个是只调整分类器(黑色部分):

另一种:通过有标签样本,微调整个系统:(如果有足够多的数据,这个是最好的。end-to-end learning端对端学习)

一旦监督训练完成,这个网络就可以用来分类了。
在相关文献中有提到Greedy Training的,这是一种逐层训练的方式,是由于当时数据数量和计算能力决定的,现在已经不再使用了,老师说他特意提出来也只是为了防止大家看到这个词蒙圈。
可以生成数据的自编码器变种
标签:sdn load origin 学习 分享 toe learn 解码器 width
原文地址:http://www.cnblogs.com/hellcat/p/7350662.html