标签:img 开头 不同 pre dal 表达 需求 ssi 一个
正则表达式中有前瞻(Lookahead)和后顾(Lookbehind)的概念,这两个术语非常形象的描述了正则引擎的匹配行为。需要注意一点,正则表达式中的前和后和我们一般理解的前后有点不同。一段文本,我们一般习惯把文本开头的方向称作“前面”,文本末尾方向称为“后面”。但是对于正则表达式引擎来说,因为它是从文本头部向尾部开始解析的(可以通过正则选项控制解析方向),因此对于文本尾部方向,称为“前”,因为这个时候,正则引擎还没走到那块,而对文本头部方向,则称为“后”,因为正则引擎已经走过了那一块地方。如下图所示: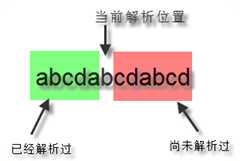
所谓的前瞻就是在正则表达式匹配到某个字符的时候,往“尚未解析过的文本”预先看一下,看是不是符合/不符合匹配模式,而后顾,就是在正则引擎已经匹配过的文本看看是不是符合/不符合匹配模式。符合和不符合特定匹配模式我们又称为肯定式匹配和否定式匹配。
现代高级正则表达式引擎一般都支持都支持前瞻,对于后顾支持并不是很广泛,因此我们这里采用否定式前瞻来实现我们的需求。
>>> re.findall(r‘^.*(?:ing)$‘,‘processing‘) # 1.匹配ing不保存, 但是.*匹配到了ing, 所以最后结果保存了 [‘processing‘] >>> re.findall(r‘^(.*)(?:ing)$‘,‘processing‘) # 2.匹配到了ing, 此处.*没有匹配到ing, 所以结果没有保存 [‘process‘] >>> re.findall(r‘^p.*(?:ing)$‘,‘processing‘) # 这里就明显的看出1的效果了,p和?:一样保存 [‘processing‘] >>> re.findall(r‘^p(.*)(?:ing)$‘,‘processing‘) # 这里的p和?:都没有被保存下来, 因为分组里没有 [‘rocess‘] >>> re.findall(r‘^.*(?:ing)$‘,‘processinging‘) [‘processinging‘] >>> re.findall(r‘^.*(?:ing)‘,‘processings‘) [‘processing‘] >>> re.findall(r‘^(.*)(?:ing)‘,‘processing‘) [‘process‘]
(pattern)
匹配 pattern 并捕获该匹配的子表达式。可以使用 $0...$9 属性从结果“匹配”集合中检索捕获的匹配。若要匹配括号字符 ( ),请使用“\(”或者“\)”。
(?:pattern)
匹配 pattern 但不捕获该匹配的子表达式,即它是一个非捕获匹配,不存储供以后使用的匹配。这对于用“或”字符 (|) 组合模式部件的情况很有用。例如,与“industry|industries”相比,“industr(?:y| ies)”是一个更加经济的表达式。
(?=pattern)
执行正向预测先行搜索的子表达式,该表达式匹配处于匹配 pattern 的字符串的起始点的字符串。它是一个非捕获匹配,即不能捕获供以后使用的匹配。例如,“Windows (?=95| 98| NT| 2000)”与“Windows 2000”中的“Windows”匹配,但不与“Windows 3.1”中的“Windows”匹配。预测先行不占用字符,即发生匹配后,下一匹配的搜索紧随上一匹配之后,而不是在组成预测先行的字符后。
(?!pattern)
执行反向预测先行搜索的子表达式,该表达式匹配不处于匹配 pattern 的字符串的起始点的搜索字符串。它是一个非捕获匹配,即不能捕获供以后使用的匹配。例如,“Windows (?!95| 98| NT| 2000)”与“Windows 3.1”中的“Windows”匹配,但不与“Windows 2000”中的“Windows”匹配。预测先行不占用字符,即发生匹配后,下一匹配的搜索紧随上一匹配之后,而不是在组成预测先行的字符后。
标签:img 开头 不同 pre dal 表达 需求 ssi 一个
原文地址:http://www.cnblogs.com/sigai/p/7351428.html