标签:不同 文章 容错 sig 动态 invisible 避免 visible 带来
ReLu使得网络可以自行引入稀疏性,在没做预训练情况下,以ReLu为激活的网络性能优于其它激活函数。
数学表达式: $y = max(0,x)$
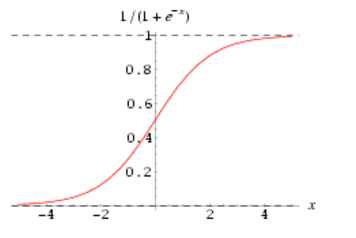
sigmoid 激活函数在神经网络学习方面,可以将重点特征推向中央区,将非重点特征推向两侧区。
数学表达式: $y = (1 + exp(-x))^{-1}$
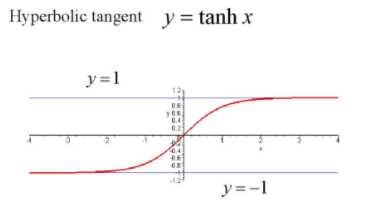
Tanh 激活函数使得输出与输入的关系能保持非线性单调上升和下降关系,比sigmoid 函数延迟了饱和期,对神经网路的容错性好。
数学表达式:
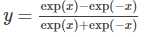
不同激活函数的神经网络的表达能力:
标签:不同 文章 容错 sig 动态 invisible 避免 visible 带来
原文地址:http://www.cnblogs.com/ljygoodgoodstudydaydayup/p/7353331.html