标签:搜索 alt div 比较 避免 换行 包含 height 开头
(\w+://)(\w+\.){1}.\w+\.\w{2,4}
匹配结果如下
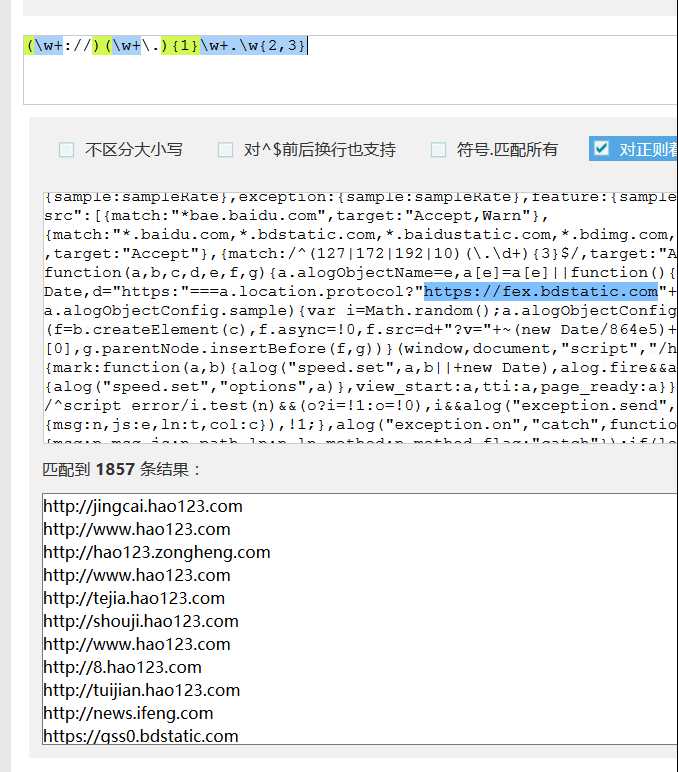
解释:
(\w+://) -> \w是指任意字符 + 匹配多个 跟上符号“//”
(\w+\.){1} -> \w任意字符,\. 就是一个 . 出现次数1次不能再多
.\w+\.\w{2,4} -> . . 是非空字符(默认出现一次) \w任意字符出现多次,后面跟上符号“.” 再跟上非空字符\w 出现次数为 2-4次
总结 一些非主流网站估计没指望了,普通如 http://www.xxx.xxx 这一类的才行
(\w+://)(\w+\.){1}.\w+\.\w{2,4}|(\w+\.){1}.\w+\.\w{2,4} 上面网址加强版
解释:
多了一个字符 "|" 把两个区分开来了,并且这个是多选择模式匹配,
意思是 前面是一个表达式,后面又是一个表达式,用或连接的 ,只要满足一个条件即为有效
匹配结果如下:
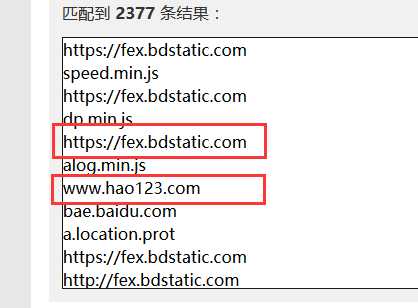
当然 请忽略那些什么.js的 手动清除下即可。
<span>.*?</span>
这个就好理解多了 搜索所有<span>标签及包含的内容
解释:
<span>和</span>这个不用说
.*? -> . 这个是除了换行符以外的字符(理论上是所有) * 出现0次以上,0次也算,? 限定为出现了就算,但是不能太多次,避免出现大堆无用字符
<div.*>.*\n*(<a.*)</div>
解释:
这个很明显了, 就是一个查找页面上所有div下面还有<a>标签的正则(注意,返回的是div不是a)
13\d{9}|15\d{9}|18\d{9}
解释:
这个最简单:
就是查询已 13,15,18开头的电话号码
13\d{9} -> 我们来解释一下,首先这个13不用管,它是普通字符,\d这里查找的是所有数字,{9}限定模式,指前面的"\d"至少要出现9次 类似于:
\d\d\d\d\d\d\d\d\d => \d{9}
他们最喜欢用email来作为例子解答,这里我也来试着写一个看看
(\w*)@\w+\.\w+
这个比较全面,基本上只要格式正确都能解析出来
(start) .*[\W\w]*?.* (end)
这个就比较牛逼了,是跨行匹配
\\[\w]([\w]|[\d]){0,4} 匹配 \u003
标签:搜索 alt div 比较 避免 换行 包含 height 开头
原文地址:http://www.cnblogs.com/suchi/p/7359596.html