标签:开发 float cluster 分布 好的 调度 blog 基于 streaming
Spark是加州大学伯克利分校AMP实验室,开发的通用内存并行计算框架。
支持用scala、java和Python等语言编写应用程序。相较于Hdoop,往往有更好的运行效率。
Spark包括了Spark Core, Spark SQL, SparkStreaming,MLlib和Graphx等组件。
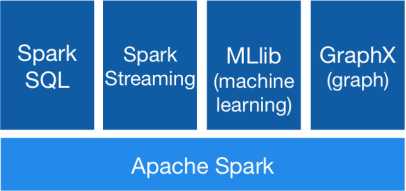
Spark运行模式:
|
Local |
本地模式 |
用于本地开发测试,本地还分为local单线程和local-cluster多线程。 |
|
On yarn |
集群模式 |
运行在yarn框架之上,由yarn负责资源管理,Spark负责任务调度和计算。 |
|
Standalone |
集群模式 |
典型的Mater-slave模式,Spark自带的模式。 |
On yarn模式需要配置hadoop环境。
众所周知,Spark的核心是RDD。RDD(Resilent Distributed Dataset)弹性分布式数据集,是一个容错的,并行的数据结构。可以让用户显式地将数据存储到磁盘和内存中,并能控制数据的分区。同时,RDD还提供了一组丰富的操作来操作这些数据。
RDD实现了基于Lineage的容错机制。RDD的转换关系,构成了compute chain,可以把这个compute chain认为是RDD之间演化的Lineage。
当一个RDD的数据丢失之后,可以从其父RDD重新计算得到。如果父RDD也不可用,则再从上一级开始计算。
简单的介绍下RDD的依赖关系:
当一个RDD需要依据一个lineage进行重算时,由于窄依赖的关系更为简单,因而回复该RDD的效率更高。相反,对于宽依赖的RDD而言需要更多的时间用于恢复。
虽然lineage可用于错误后RDD的恢复,但对于很长的lineage的RDD来说,这样的恢复耗时较长。因此,将某些RDD进行检查点操作(Checkpoint)保存到稳定存储上,是有帮助的。
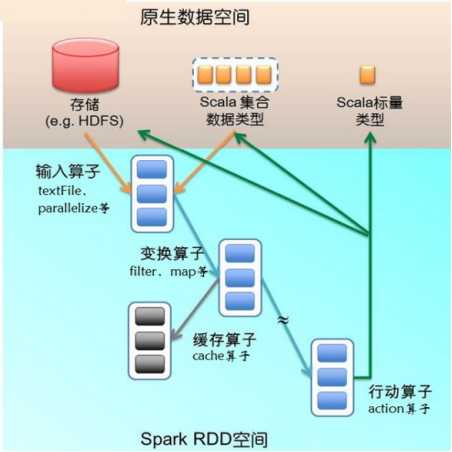
算子是RDD中定义的函数,可以对RDD中的数据进行转换和操作。
RDD有两种操作算子:
Transformation:结果是得到一个新的RDD。比如从数据源生成一个RDD,或是由一个RDD生成另一个RDD。
Action:得到一个值或者是一个计算结果(结果也可以是一个RDD,例如使用col lec算子)。
所有的Transfomation采用的均为懒策略。即当一个Transfomation被提交时,不会立即进行计算。计算只有在action被提交时才触发。
下图描述了Spark在运行转换中通过算子对RDD进行转换:
标签:开发 float cluster 分布 好的 调度 blog 基于 streaming
原文地址:http://www.cnblogs.com/insaneXs/p/7367428.html