标签:public 生成 实例 赋值 静态 自定义 when 弱引用 ognl
// 获取 SqlSessionFactoryBuilder 用以新建 SqlSession 工厂实例类
SqlSessionFactoryBuilder factoryBuilder = new SqlSessionFactoryBuilder();
SqlSessionFactory build = null;
try {
// 通过配置文件建立 SqlSessionFactory,尽管可以配置多个环境,每个 SqlSessionFactory 实例只能选择其一。
build = factoryBuilder.build(Resources.getResourceAsReader("mybatis-config.xml"));
} catch (IOException e) {
e.printStackTrace();
}例中使用的 mybatis-config.xml:
动态获取外部配置,典型使用场景:加载外部的 JDBC 配置文件:
<properties resource="jdbc-mysql.properties"></properties>有关 MyBatis 运行时的各种核心设置。
设置类型别名。注意它只和 XML 配置有关,仅仅为了减少类完全限定名的冗余,一般不用。
类型处理器。用 PreparedStatement 时的参数设置、从结果集中取出值等,都需要用到类型处理器将值以 合适的方式 转换成 Java 类型。typeHandlers 架起了 Java 程序与数据库关于类型处理的桥梁。typeHandlers 支持自定义(实现 org.apache.ibatis.type.TypeHandler 接口, 或继承 org.apache.ibatis.type.BaseTypeHandler)
在已映射语句执行过程中的某一点进行拦截调用。应用举例:
分页插件 PageHelper(注意,调用语句要紧跟分页的静态方法):
@Test
public void testGetAllEmployees() {
SqlSessionFactory sessionFactory = getSessionFactory();
SqlSession session = sessionFactory.openSession();
EmployeeMapper mapper = session.getMapper(EmployeeMapper.class);
Page<Object> startPage = PageHelper.startPage(1, 2);
List<Employee> allEmployees = mapper.getAllEmployees();
PageInfo<Employee> info = new PageInfo<>(allEmployees, 4);
for (Employee employee : allEmployees) {
System.out.println(employee);
}
System.out.println("当前页码:" + info.getPageNum());
System.out.println("总记录数:" + info.getTotal());
System.out.println("每页的记录数:" + info.getPageSize());
System.out.println("总页数:" + info.getPages());
System.out.println("是否是第一页:" + info.isIsFirstPage());
System.out.println("是否是最后一页:" + info.isIsLastPage());
System.out.println("连续显示的页码:");
int[] nums = info.getNavigatepageNums();
for (int i : nums) {
System.out.print(i + " ");
}
session.close();
}
配置环境。
根据不同的数据库厂商执行不同的语句。
定义 SQL 映射语句。有多种方式声明映射语句的配置信息源,注意把 mapper 配置文件和接口放在同一个包下且名字一致(编译后路径):
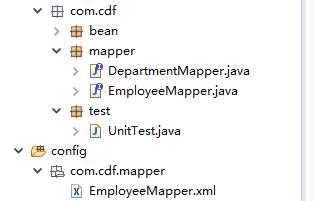 。
。
传统的使用 DAO 接口实现类的具体方法来执行 SQL 的方式存在以下问题:代码不够清晰、类型不安全、字符串字面值易错、强制类型转换,我们使用 mapper 接口的方式,抽取出 SQL 语句以动态的进行配置。具体的 DAO 实现类为 代理类,由 MyBatis 动态创建:
EmployeeMapper mapper = session.getMapper(EmployeeMapper.class);
System.out.println(mapper.getClass().getName());输出:
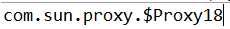
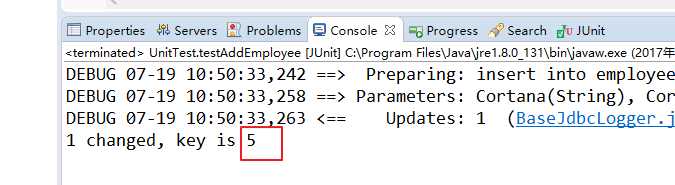
指定了 keyProperty 为 true 后,employee 的 id 属性就是插入的那条数据的自增主键值了(不再是 null),效果类似执行 add 后将 Statement 中的 getGeneratedKeys() 方法返回值中的自增主键赋值给传入的 employee 参数引用:
public void testAddEmployee() {
SqlSessionFactory sessionFactory = getSessionFactory();
SqlSession session = sessionFactory.openSession();
EmployeeMapper mapper = session.getMapper(EmployeeMapper.class);
Employee employee = new Employee(null, "Cortana", "Cortana@my.com", "0", new Department(3, null));
int influence = mapper.addEmployee(employee);
System.out.println(influence + " changed,the key auto increased is " + employee.getId());
session.commit();
session.close();
}
单个参数的属性会被解析,从而可以直接使用,而其本身的获取也可以通过隐藏对象“_parameter”(关于这个内置参数,后面会介绍),但是多个对象就不一样了:
// 根据 id 和 lastName 查询单个 Employee
@Test
public void testGetEmployeeByIdAndName() {
SqlSessionFactory sessionFactory = getSessionFactory();
SqlSession session = sessionFactory.openSession();
EmployeeMapper mapper = session.getMapper(EmployeeMapper.class);
Employee employee = mapper.getEmployeeByIdAndName("allen", 2);
System.out.println(employee);
session.close();
}<select id="getEmployeeByIdAndName" resultType="com.cdf.bean.Employee">
select id,last_name,email,gender from employee where
last_name=#{lastName} and id=#{id}
</select>/**
* 根据 id 和 lastName 获取 Employee,注意使用 @Param 注释以指定参数名
*/
public Employee getEmployeeByIdAndName(@Param("lastName") String lastName, @Param("id") Integer id);
Mapper 配置文件中使用参数时按照顺序使用 #{param1}、#{param2} 或者 {0}、{1}。
select id,last_name,email,gender from employee where last_name=#{param1} and id=#{param2}/**
* 根据 id 和 lastName 获取 Employee,并使用 map 映射参数列表
*/
public Employee getEmployeeByIdAndNameUseMap(Map<String, Object> map);// 根据 id 和 lastName 查询单个 Employee,使用 Map 传参
@Test
public void testGetEmployeeByIdAndNameUseMap() {
SqlSessionFactory sessionFactory = getSessionFactory();
SqlSession session = sessionFactory.openSession();
EmployeeMapper mapper = session.getMapper(EmployeeMapper.class);
Map<String, Object> map = new HashMap<String, Object>();
map.put("table", "employee");
map.put("name", "Allen");
map.put("id", 2);
Employee employee = mapper.getEmployeeByIdAndNameUseMap(map);
System.out.println(employee);
session.close();
}<select id="getEmployeeByIdAndNameUseMap" resultType="com.cdf.bean.Employee">
select
id,last_name,email,gender from ${table} where
last_name=#{name} and
id=#{id}
</select>resultType 指定的是让 MyBatis 把数据表中的一条记录封装 Java 对象的类型,比如返回的是一个集合, resultType 写的是集合中元素的类型,而不是集合本身的类型!
MyBatis 允许在增删改操作 直接 在方法定义返回值类型(int、long、boolean):

参数处理方式:
第一种情况不需要做额外设置,直接指定返回值为 Map 即可。
第二种情况:
// 获取所有 Employee,封装到 Map 中, @MapKey 指定了 key
@MapKey(value = "id")
public Map<Integer, Employee> getAllEmployeesToMap();
<select id="getAllEmployeesToMap" resultType="com.cdf.bean.Employee">
select
id,last_name,email,gender from employee
</select>
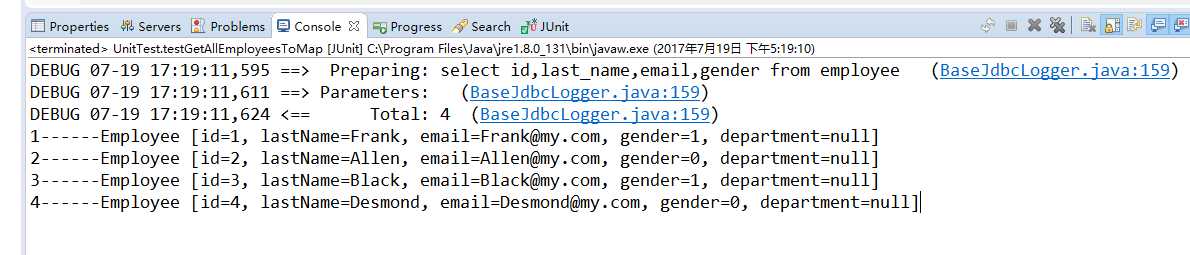
// 查询所有 Employee,返回 Map,该 Map 以 id 为 key,将每条记录封装到 Employee 对象作为 value
@Test
public void testGetAllEmployeesToMap() {
SqlSessionFactory sessionFactory = getSessionFactory();
SqlSession session = sessionFactory.openSession();
EmployeeMapper mapper = session.getMapper(EmployeeMapper.class);
Map<Integer, Employee> map = mapper.getAllEmployeesToMap();
Set<Entry<Integer, Employee>> entrySet = map.entrySet();
for (Entry<Integer, Employee> entry : entrySet) {
System.out.println(entry.getKey() + "------" + entry.getValue());
}
session.close();
}
即自定义结果集。举例:
<select id="getAllEmployees" resultMap="toEmployee">
select
id,last_name,email,gender from employee
</select>
<resultMap type="com.cdf.bean.Employee" id="toEmployee">
<id column="id" property="id"/>
<result column="last_name" property="lastName"/>
<result column="email" property="email"/>
<result column="gender" property="gender"/>
</resultMap>
当有自定义类型的成员变量时,使用级联属性(不推荐)、association 联合查询、association 分步查询:
<select id="getAllEmployeesFully" resultMap="toFullEmployee">
select e.id id,e.last_name lastName,e.email
email,e.gender gender,d.id dId,d.name dName
from employee e,department d
where e.d_id=d.id order by e.id
</select>
<resultMap type="com.cdf.bean.Employee" id="toFullEmployee">
<id column="id" property="id"/>
<result column="lastName" property="lastName"/>
<result column="email" property="email"/>
<result column="gender" property="gender"/>
<!-- 一、使用级联方式查询
<result column="dId" property="department.id"/>
<result column="dName" property="department.name"/>
-->
<!-- 二、使用 association 联合查询
<association property="department" javaType="com.cdf.bean.Department">
<id column="dId" property="id"/>
<result column="dName" property="name"/>
</association>
-->
<!-- 三、使用 association 分步查询 -->
<association property="department"
select="com.cdf.mapper.DepartmentMapper.getDepartmentById"
column="{id=dId}">
</association>
</resultMap>注意

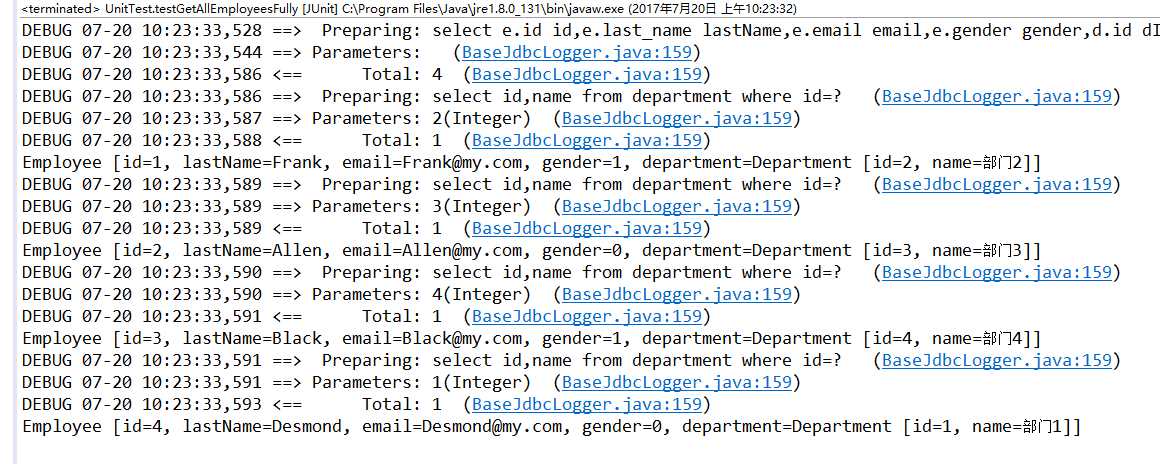
分步查询中,有些情况使用延迟加载就有了意义。
延迟加载默认是关闭的,需要在全局配置文件中手动声明开启。

@Test
public void testGetAllEmployeesFully() {
SqlSessionFactory sessionFactory = getSessionFactory();
SqlSession session = sessionFactory.openSession();
EmployeeMapper mapper = session.getMapper(EmployeeMapper.class);
List<Employee> allEmployeesFully = mapper.getAllEmployeesFully();
for (Employee employee : allEmployeesFully) {
System.out.println(employee.getEmail());// 改为“仅使用 email 字段”后,延迟加载生效,仅发送外层查询
}
// 这时,才会再发送查询 department 表的请求
Department department = allEmployeesFully.get(1).getDepartment();
System.out.println(department);
session.close();
}可以在 log 中看出延迟加载的效果:
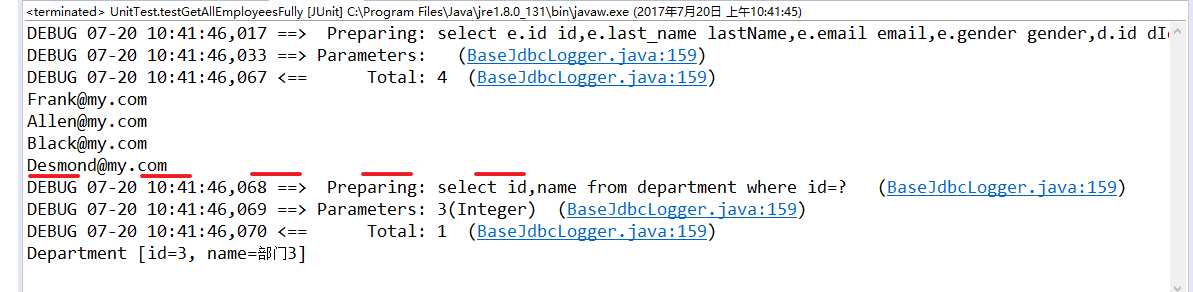
例:
Department 有个 List 类型的 employees 字段,表示该部门下所有的员工
<select id="getDepartmentFullyById" resultMap="toFullDepartment">
select e.id eid, e.last_name lastName, e.email email, e.gender gender, d.id
id, d.name name
from department d
left join employee e on e.d_id = d.id
where d.id=#{id}
</select>
<resultMap type="com.cdf.bean.Department" id="toFullDepartment">
<id column="id" property="id"/>
<result column="name" property="name"/>
<collection property="employees" ofType="com.cdf.bean.Employee">
<id column="eid" property="id"/>
<result column="lastName" property="lastName"/>
<result column="email" property="email"/>
<result column="gender" property="gender"/>
</collection>
</resultMap>collection 中的分步查询与延迟加载类似,不再赘述。
关于延迟加载,collection & association 中还有一个局部配置属性:

<resultMap type="com.cdf.bean.Employee" id="toFullEmployee">
……
<result column="gender" property="gender"/>
<discriminator javaType="string" column="gender">
<case value="0" resultType="com.cdf.bean.Employee">
<!-- 业务逻辑 -->
</case>
<case value="1" resultType="com.cdf.bean.Employee">
<!-- 业务逻辑 -->
</case>
</discriminator>
……注意 case 的 resultType 写的是最终的类型,也就是主 resultMap 中的。
场景举例:
多条件查询:传入 Employee 对象,以其所有不为 null 的属性来查询 Employee,条件封装在这个对象中,条件可能为空,可能碎片,也可能很完整。
<select id="getEmployeesConditional" resultType="com.cdf.bean.Employee">
select id,last_name,email,gender
from employee
<!-- <trim prefix="where" suffixOverrides="and">
<if test="id != null">
id=#{id} and
</if>
<if test="lastName != null">
last_name=#{lastName} and
</if>
<if test="email != null">
email=#{email} and
</if>
<if test="gender != null">
gender=#{gender} and
</if>
<if test="department != null && department.getId() != null">
d_id=#{department.id}
</if>
</trim> -->
<where>
<if test="id != null">
id=#{id}
</if>
<if test="lastName != null">
and last_name=#{lastName}
</if>
<if test="email != null">
and email=#{email}
</if>
<if test="gender != null">
and gender=#{gender}
</if>
<if test="department != null && department.getId() != null">
and d_id=#{department.id}
</if>
</where>
</select>prefix、suffix:在整个 if 组的前后加前后缀。
suffixOverrides、prefixOverrides:在整个 if 组的前后进行修剪。
上例如果 and 不写后面,老实用 where 标签就行,使用 where 会自动去掉第一个 and。
使用标签只要保证最终拼接的语句没问题就行。
OGNL 表达式类似于 EL 表达式,支持级联和调方法,如上例。
场景:
单条件查询:根据优先级来查 Employee,优先根据 id,其次使用 last_name 查询,若都不存在,则不查。
<select id="getEmployeesUseOrderConditions" resultType="com.cdf.bean.Employee">
select id,last_name,email,gender
from employee
<where>
<choose>
<when test="id != null">
id=#{id}
</when>
<when test="lastName != null">
last_name=#{lastName}
</when>
<otherwise>
1=2
</otherwise>
</choose>
</where>
</select>// 条件
// Employee employee = new Employee(3, "Frank", null, null, null);
// Employee employee = new Employee(null, "Frank", null, null, null);
Employee employee = new Employee();update + set 标签的使用参照 where,他们都可以用 trim 代替,原则还是只要拼接成功即可。
场景:批量插入
<insert id="batchAddEmployees">
insert into employee(last_name,email,gender,d_id) values
<foreach collection="employees" item="e" separator=",">
(#{e.lastName},#{e.email},#{e.gender},#{e.department.id})
</foreach>
</insert>@Test
public void testBatchAddEmployees() {
SqlSessionFactory sessionFactory = getSessionFactory();
SqlSession session = sessionFactory.openSession();
EmployeeMapper mapper = session.getMapper(EmployeeMapper.class);
List<Employee> employees = new ArrayList<Employee>();
employees.add(new Employee(null, "Franklin", "Franklin@my.com", "1", new Department(4, null, null)));
employees.add(new Employee(null, "James", "James@my.com", "1", new Department(1, null, null)));
boolean success = mapper.batchAddEmployees(employees);
System.out.println(success);
session.close();
}(建议像例中一样传参数使用 @Param 指定 key)
_parameter:
传单个参数的情形,可以使用内置参数 _parameter 来使用参数本身:

当然,图中例子只是个说明,事实上直接写 "id != null" 也是可以的,MyBatis 会自动解析。上文都是直接写的。
_databaseId:
当前环境使用的 databaseId。
在 sql 标签中定义即可,引用时使用 include 标签。
bind 元素可以从 OGNL 表达式中创建一个变量并将其绑定到上下文:
<select id="getEmployeesLikely" resultType="com.cdf.bean.Employee">
<bind name="fragment" value="‘%‘+_parameter+‘%‘"/>
select id,last_name,email,gender
from employee where last_name like #{fragment}
</select>// 查询所有 Employee
@Test
public void testFirstLevelCache() {
SqlSessionFactory sessionFactory = getSessionFactory();
SqlSession session = sessionFactory.openSession();
EmployeeMapper mapper = session.getMapper(EmployeeMapper.class);
List<Employee> allEmployees = mapper.getAllEmployees();
for (Employee employee : allEmployees) {
System.out.println(employee);
}
System.out.println();
List<Employee> allEmployees2 = mapper.getAllEmployees();
for (Employee employee : allEmployees2) {
System.out.println(employee);
}
session.close();
}注意到,第二次查询时没有发送 sql 查询给数据库:
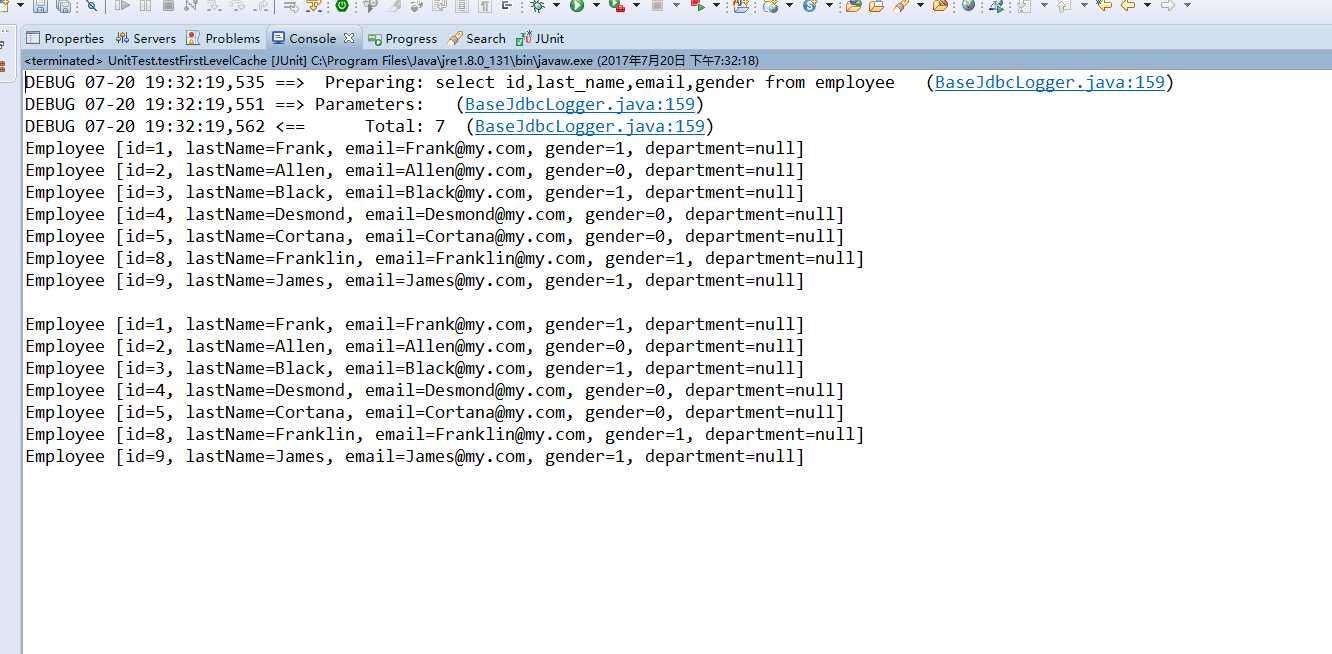
关于 cache 标签属性:
开启二级缓存后,进行测试:
// 测试二级缓存
@Test
public void testSecondLevelCache() {
SqlSessionFactory sessionFactory = getSessionFactory();
SqlSession session = sessionFactory.openSession();
SqlSession session2 = sessionFactory.openSession();
SqlSession session3 = sessionFactory.openSession();
EmployeeMapper mapper = session.getMapper(EmployeeMapper.class);
EmployeeMapper mapper2 = session2.getMapper(EmployeeMapper.class);
EmployeeMapper mapper3 = session3.getMapper(EmployeeMapper.class);
List<Employee> allEmployees = mapper.getAllEmployees();
System.out.println(allEmployees);
session.close();
List<Employee> allEmployees2 = mapper2.getAllEmployees();
System.out.println(allEmployees2);
session2.close();
List<Employee> allEmployees3 = mapper3.getAllEmployees();
System.out.println(allEmployees3);
session3.close();
}打印:
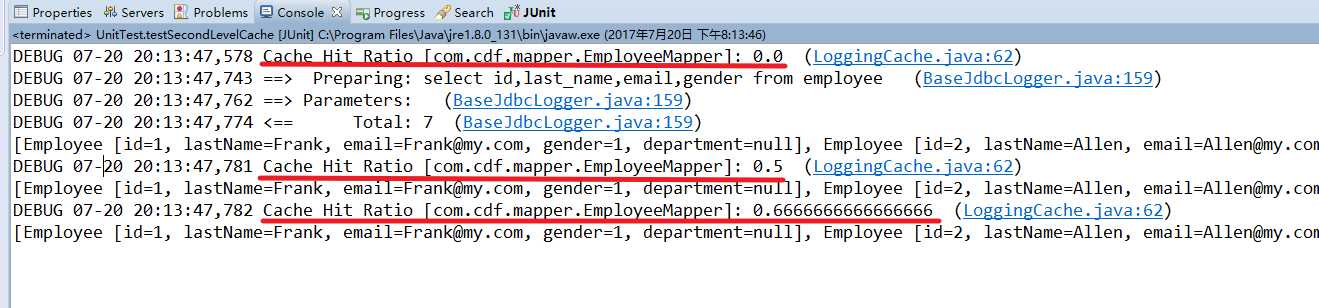
注意:如果完整地查询 Employee,那么成员变量 Department 也需要实现 Serializable 接口。
CRUD 操作的标签都有个 flushCache 属性用来设置是否在操作完成后进行刷新缓存(一、二级都刷新)的操作。
缓存查找顺序:先找二级缓存,再找一级缓存,都没命中则进数据库。
在 cache 标签中配置即可
根据表,自动生成 bean、mapper 以及 sql 映射配置文件。参考官方的 quick start 即可。
标签:public 生成 实例 赋值 静态 自定义 when 弱引用 ognl
原文地址:http://www.cnblogs.com/chendifan/p/7371886.html