标签:选择 使用 height 线程 比较 list star plain 按钮
之前写过kafka_2.9.2-0.8.2.2版本的安装,kafka在新的0.9版本以上改动比较大,配置和api都有很大更新,并且broker对应的partition支持多线程生产和消费,所以性能比之前好得多,比如老版本的kafka单机每秒可以推送100条数据,但是新版的可以每秒推送达到上千条数据,多节点的性能提升非常大,下面是具体的安装过程
访问Apache Kafka官网下载安装包,地址:http://kafka.apache.org/
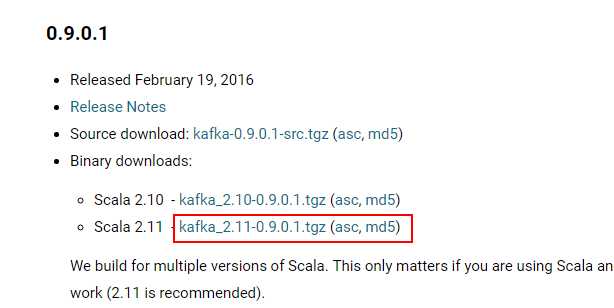
点击download按钮,进入版本选择,这里选择0.9.0.1版本的基于Scala 2.11的kafka_2.11-0.9.0.1.tgz安装包
注意不要安装0.9.0.0的版本,这个版本存在问题,并且已经在0.9.0.1中得到修复
安装kafka集群之前,确保zookeeper服务已经正常运行,这里3台zookeeper准备工作都已完成,三台主机分别为:linux1,linux2,linux3,接下来在linux1主节点上执行释放并做软链:
tar -xvzf kafka_2.11-0.9.0.1.tgz mv kafka_2.11-0.9.0.1 /bigdata/ cd /bigdata/ ln -s kafka_2.11-0.9.0.1 kafka cd kafka
接下来执行 vim config/server.properties 编辑配置文件
修改broker.id=1,默认是0

这个值是集群中唯一的一个整数,每台机器各不相同,这里linux1设置为1其他机器后来再更改
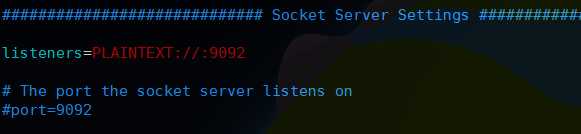
然后往下找到listeners这个配置项一般配置PLAINTEXT://ip:9092,如果配置0.0.0.0则绑定全部网卡,如果默认像下面这样,kafka会绑定默认的网卡和机器host配置的主机名,一般在机器中hosts,hostname都要正确配置,这里默认即可;然后下面的port默认不用配置,所以这块配置和老版本不同
然后配置kafka日志目录,注意目录要提前建好

然后下面num.partitions是默认单个broker上的partitions数量,默认是1个,如果想提高单机的并发性能,这里可以配置多个

然后是kafka日志的保留时间,单位小时,默认是168小时,也就是7天
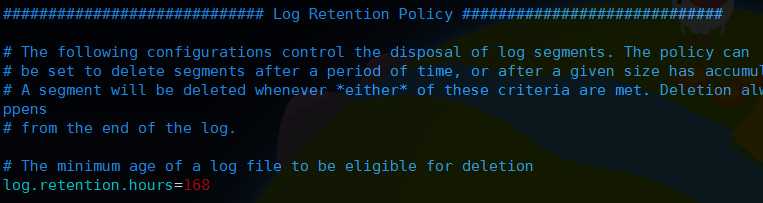
注意之前有个log.cleaner.enable表示是否清理日志,这个配置在新版本已经废弃了,也就是日志必须是定时清理的,仅仅通过上面的保留时间参数来控制
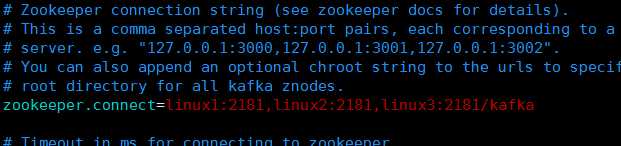
然后设置协调的zookeeper集群列表,然后指定了Kafka在zookeeper上创建的znode为/kafka,
最后一项配置,默认即可

这个表示连接zookeeper服务器的超时时间,以上设置都完毕,保存配置并退出,然后将kafka目录发送至其他主机
scp -r kafka_2.11-0.9.0.1 linux2:/bigdata/ scp -r kafka_2.11-0.9.0.1 linux3:/bigdata/
这样就发送到了linux2和linux3这两台主机,然后依次修改linux2和linux3中config/server.properties配置文件中broker.id分别为2和3并保存
最后对三个节点都要创建日志目录: mkdir /bigdata/kafka_logs 并且根据需要创建软链接,完成之后kafka集群就安装完毕了,
然后启动所有主机的kafka服务,分别进入kafka目录,执行下面命令启动服务:
bin/kafka-server-start.sh -daemon config/server.properties
新版本的kafka无需使用nohup挂起,直接使用-daemon参数就可以运行在后台,启动后通过jps查看有Kafka进程就启动成功,对于创建topic,生产,消费操作和之前基本都是一样的,停止同样执行bin/kafka-server-stop.sh即可
标签:选择 使用 height 线程 比较 list star plain 按钮
原文地址:http://www.cnblogs.com/freeweb/p/7380492.html