标签:复杂 -- 拆分 地方 数论 foreach 编译原理 span 逻辑
控制流是指代码执行时指令的执行顺序。在各种控制逻辑的作用下,程序会沿着特定的逻辑顺序执行。一般控制逻辑包括有无条件分支、循环、函数调用等。
一、扁平化的定义
本篇讲代码混淆的一个重要手段,控制流扁平化。
所谓控制流是指代码执行时指令的执行顺序。在各种控制逻辑的作用下,程序会沿着特定的逻辑顺序执行。一般控制逻辑包括有\无条件分支、循环、函数调用等。在正常情况下程序的逻辑非常好理解(代码逻辑不好的程序员都死了。。。),开发过程中有各种人为的行为使代码逻辑清晰,便于维护和扩展。但同时,对于逆向行为来说,清晰的代码逻辑会导致很容易抓住程序重点,加快破解速度。而控制流扁平则是反其道而行将源代码结构改变,使得程序的逻辑复杂不易被静态分析,增加逆向难度。
下面通过一个例子来说明
这是《软件加密与解密》中的示例代码
int modexp(int y, int x[], int w, int n)
{
int R, L;
int k = 0;
int s = 1;
while(k < w) {
if (x[k] == 1) {
R = (s * y) % n;
}
else {
R = s;
}
s = R * R % n;
L = R;
k++;
}
return L;
}
根据上段代码,我们可以画出它的控制流图。
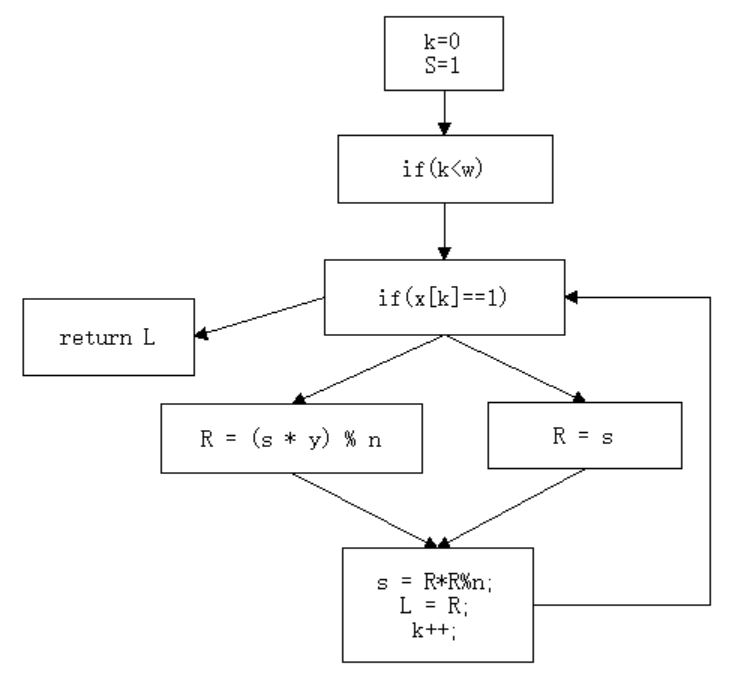
这里我们用if来代替while,这样可以使得逻辑更加清晰。这幅图就是扁平前的效果,可以看到程序基本是从上往下执行的,逻辑线路非常明确。
而当我们对它进行了扁平化处理之后,就变成这样:
int modexp(int y, int x[], int w, int n)
{
int R, L, s, k;
int next = 0;
for(;;) {
switch(next) {
case 0: k = 0; s = 1; next = 1; break;
case 1: if(k<w) next = 2; else next = 6; break;
case 2: if(x[k]==1) next = 3; else next = 4; break;
case 3: R=(s * y) % n; next = 5; break;
case 4: R = s; next = 5; break;
case 5: s=R * R % n; L = R; k++; next = 1; break;
case 6: return L;
}
}
}
控制流图变成了这样
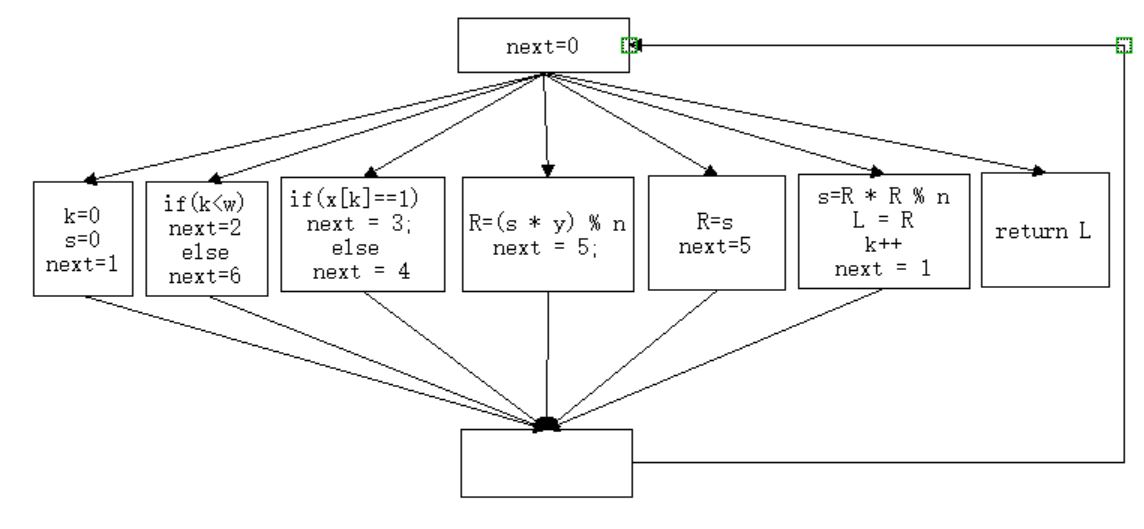
直观的感觉就是代码变“扁”了,所有的代码都挤到了一层当中,这样做的好处在于在反汇编、反编译静态分析的时候,无法判断哪些代码先执行哪些后执行,必须要通过动态运行才能记录执行顺序,从而加重了分析的负担。
二、实现平台
扁平化的实现是不能平地而起的,必须要基于一定的平台。就是说,不是你随便给我一段代码,让我混淆我就能混。之前的例子很简单,遇到复杂一点的比如while循环里有声明局部变量,while内部的if和else分支都用到这个变量;当混淆后,while循环已经被我们用if改写了,那这个局部变量的声明放到哪里?如果放到替代while的if分支里,由于这个if分支和原来while内部的if-else分支是平级的,那么这个局部变量就不能在if-else分支中使用了。这就是一个bug。所以在混淆前必须对源代码进行分析。
那用什么东西进行分析呢?答案是编译器,更准确说是编译(解释)器的前端。
这里要重温一下很有趣的编译原理。以编译语言来讲,从源代码到可执行程序要经历这么几步:预编译——>编译——>汇编——>链接。以GCC来说,预编译对应-E参数,将源代码所有的宏处理展开,包括include头文件。编译则是将预处理完的文件通过词法分析、语法分析等前端处理,生成抽象语法书并转化为中间语言,然后进入编译器后端执行优化策略,输出为汇编语言,对应的GCC参数为-S。汇编是将汇编语言(低级程序语言)转化成对应的可执行的机器码。链接则将生成的多个模块(也可能是一个)间互相引用的部分处理好,让不同的模块可以相互调用。
//预编译 gcc -E test.c -o test.i //编译 gcc -S test.i -o test.s //汇编 gcc -c test.s -o test.o //链接 ld -static test1.o test2.o tes3.o -start-group -lgcc -lgcc_eh -lc -end-group crtend.o crtn.o
我们平常所说的编译器GCC其实是一套编译体系,包括了编译器、汇编器、链接器,狭义上的编译器只处理从源代码到汇编语言的过程。下文所述的编译器均是狭义上的编译器,不指编译体系。
对于编译器以中间语言为界限分为前端和后端。前端进行词法分析、语法分析、中间语言生成,后端负责优化。我们所需要的就是词法和语法分析。
词法分析就是将源代码切割成一个一个的单词。语法分析就是研究源代码的逻辑了。由于篇幅限制(已经很啰嗦了,不过似乎并不能讲清楚),这里就不详细描述了,总之就是经过语法分析,编译器前段会得到抽象语法树,并且获得控制流图,也就是我们之前画的那种。有了控制流图才能在其基础上进行修改,所以一般需要都是采用魔改编译器的方式来完成代码混淆。
要魔改,编译器最好是开源的,扩展性要好,所以一般都采用clang作为基础。clang是一个由C++编写、基于LLVM编译体系的C/C++/OC编译器。文档链接http://clang.llvm.org/docs/index.html。
三、算法抽象
在知晓了平台之后我们就可以开始研究如何进行控制流扁平。一般扁平算法基本步骤如下:
1、将函数体拆分为多个基本块,构建控制流图。将这些原本属于不同层级的基本块放到同一层级;
2、将所有基本块封装到一个switch选择分支当中;
3、用一个状态变量来表示当前状态,进行逻辑顺序控制(上述代码中的next变量)。
改变原有结构往往会带来一些副作用,比如之前所说的局部变量的声明要提前,否则不同分支无法使用同一个变量。除此之外的副作用还有:
1、由于声明提前,声明和赋值过程分离,而引用类型需要声明的同时定义,代码如下
while(k<m) {
int& a = k; //引用需同时声明和定义
if(...) {
a += ...
}
else {
a -= ...
}
...
}
//混淆后变以下
int &a; //错误
switch(next) {
case ...: if (k<m) a = k;
...
case ...: if(...) a+=...;else a-=...;next=...;
...
}
2、构造函数和析构函数会因为声明位置而产生副作用。
3、带来同名变量的问题,即原本不同作用域名称相同的变量变成同作用域名称相同的变量。
4、try-catch语句可能会遇到的执行顺序问题。
除了要处理这些副作用之外,源代码中本来的while、do-while、for循环包括原本的switch-case分支统统需要改为if-goto的形式。然后再进行switch-case的封装。
最终的算法执行顺序为
标识符重命名(解决变量名冲突)——>控制语句展开(全变成if)——>变量声明提前——>控制流压扁
3.1标识符重命名
这个目的很明显就是为了解决变量名冲突,所以按照一定顺序改就行了。
3.2控制语句展开
目的是将逻辑控制全变成if-goto逻辑,类似于下图

3.3变量声明提前
针对基本类型和指针类型按以下步骤执行:
将声明提前——>如果原来有初始化行为,则在原来的位置增加赋值语句,用初始化值赋值——>如果没有初始化行为则赋值为0——>over
引用变量需要变为指针变量按上述步骤执行。
针对对象的构造和析构按照以下步骤执行:
在起始处用auto_ptr分配一段对象大小的内存——>在原来初始化的位置用placement new语句对auto_ptr的内存进行初始化——>原始代码中引用对象的位置改为auto_ptr解引用——>在隐式析构的位置显示调用析构函数——>over
3.4控制流压扁
最后是控制流压扁的伪代码
对函数有控制流图cfg 入口节点为entry 出口节点为exit count = 0 构造一个switch,和控制值nextVar foreach node in cfg: if node != exit: 新建一个case,并包含node的全部内容 若node有一个后继节点: nextVar = x x为后继节点的case 若node有两个后继节点a1,a2: if condition: nextVar = x else nextVar = y x为a1的case,y为a2的case 增加一个break; 将上述switch结构封装到一个死循环中
四、不透明谓词
上述的过程我们会发现一个问题,所有的next都是直接赋值出来的,看你next等于几就知道下一个执行什么了。。。。那还有什么用。。。。
所以这里就介绍另一件利器,来解决这个问题。
所谓不透明,就是对方难以推断的。不透明谓词就是代码的编写者知道是真是假是什么,但是攻击者难以从字面获悉。
比如
if ((x * x + x) % 2 == 0) {
...
}
else {
...
}
对于公式x平方加x,等价于(x+1)*x,偶数乘奇数等于偶数,所以该判断必然成立。好吧这个式子简单了点,我们换个难点的
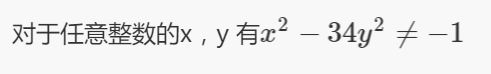
总之翻开一本数论,找一个结论,作为if的判断条件,知道为真或者为假。而攻击者如果不知道的情况下就会难以琢磨。
应用到上述的扁平化,比如
int a[] = {1, 2, 4, 12, 16...}
int i = 0;
int next = a[0] - 1;
switch(next) {
case 0: ...; next = a[i + 1] - a[i]; i++; break;
case 1: ...; next = a[i + 2] / a[i + 1]; i+=2; break;
case 2: ...; return ;
case 3: ...; next = a[i + 1] - a[i]; i--; break;
case 4: ...; next = a[i - 2] * a[i - 1]; break;
}
定义一个数组,next第一次赋值为0,进入case0;
next为a[1]-a[0]进入case1;
next为a[3] / a[2]进入case3;
next为a[4] – a[3]进入case4;
next为a[0] * a[1]进入case2;
返回。
为了提高难度可以将数组定义为全局变量,在其他地方生成,甚至动态生成,只要保持一定的数学关系即可。
本文 完
PS:本文部分名词解释、图片来自一下资料:
《软件加密与解密》
张清泉的硕士论文《基于clang的C++代码混淆工具》
宋亚齐的硕士论文《基于代码混淆的软件保护技术研究》
PSS:基于clang的混淆工具个GitHub上有一个,但是是clang3.3的,太老了,我最近在重构,版本为最新的clang3.9.1
不过以我不定期更新的情况看。。。。在实战篇前重构完的难度较大,能不能重构完还两说。。。。。。
https://github.com/penguin-wwy/cppobfuscator
git地址放出来,有想一起重构的可以一起,看热闹的可以帮我点个star,给点动力。
PSSS
不透明谓词还有很多种算法,有时间再说。
标签:复杂 -- 拆分 地方 数论 foreach 编译原理 span 逻辑
原文地址:http://www.cnblogs.com/ichunqiu/p/7383045.html