标签:恢复 产生 com name 还需要 logs fail pre 健康状况
在Hadoop1.x版本的时候,Namenode存在着单点失效的问题。如果namenode失效了,那么所有的基于HDFS的客户端——包括MapReduce作业均无法读,写或列文件,因为namenode是唯一存储元数据与文件到数据块映射的地方。而从一个失效的namenode中恢复的步骤繁多,系统恢复时间太长,也会影响到日常的维护。
Hadoop的2.x版本在HDFS中增加了对高可用性的支持来解决单点失效的问题。
这一实现中简单说就是配置了一对活动-备用namenode。当活动namenode失效的时候,备用namenode就会接管它的任务并开始服务于来自客户端的请求,不会有任何明显中断。
下面我们来看一下HDFS实现高可用性的架构图:
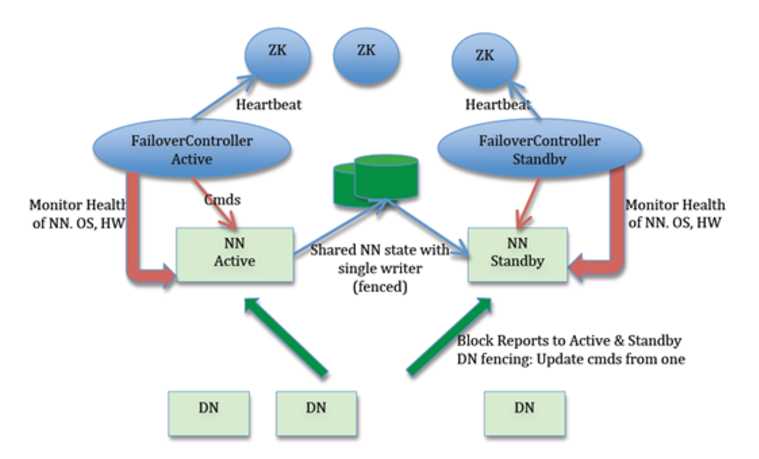
从架构图我们可以看到:
Active NameNode 和 Standby NameNode:两台 NameNode 形成互备,一台处于 Active 状态,为主 NameNode,另外一台处于 Standby 状态,为备 NameNode,只有主 NameNode 才能对外提供读写服务。
主备切换控制器又称故障转移控制器,ZKFailoverController:ZKFailoverController 作为独立的进程运行,对 NameNode 的主备切换进行总体控制。ZKFailoverController 能及时检测到NameNode 的健康状况,在主NameNode 故障时借助 Zookeeper 实现自动的主备选举和切换。
Zookeeper 集群:为主备切换控制器提供主备选举支持。
共享存储系统:共享存储系统是实现NameNode 的高可用最为关键的部分,共享存储系统保存了 NameNode 在运行过程中所产生的 HDFS 的元数据。主NameNode和备NameNode 通过共享存储系统实现元数据同步。在进行主备切换的时候,新的主 NameNode 在确认元数据完全同步之后才能继续对外提供服务。
DataNode 节点:除了通过共享存储系统共享 HDFS 的元数据信息之外,主 NameNode 和备 NameNode 还需要共享 HDFS 的数据块和 DataNode 之间的映射关系。DataNode 会同时向主 NameNode 和备 NameNode 上报数据块的位置信息。
标签:恢复 产生 com name 还需要 logs fail pre 健康状况
原文地址:http://www.cnblogs.com/caiyisen/p/7396907.html