标签:with 写锁 dep for output ice 单位 info stat
jdk:jdk-8u77-linux-x64.tar.gz
zookeeper:zookeeper-3.4.6.tar.gz
hadoop:hadoop-2.7.4.tar.gz
hbase:hbase-1.3.1-bin.tar.gz
3台vmware虚拟机(已配置无秘钥访问)
其中,/etc/hosts文件内容如下:

上传安装包,解压缩,然后配置环境变量即可。

正常配置之后,在服务器任意路径执行java -version可以显示java版本。如下所示。

这里也不在过多描述,简单罗列一下配置文件。
配置文件:zoo.cfg
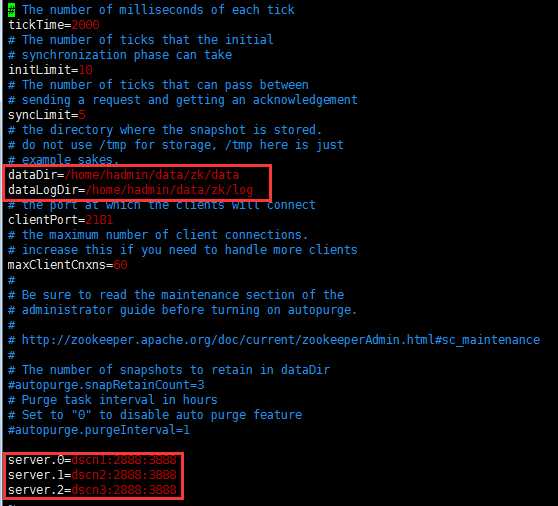
需要分别在3个节点的,dataDir路径下生成节点的myid。
启动并验证zookeeper是否正常
启动命令:/home/hadmin/zookeeper-3.4.6/bin/zkServer.sh start
查看状态:/home/hadmin/zookeeper-3.4.6/bin/zkServer.sh status
启动之后,3个节点的状态分别如下:



因为HBase的底层是基于Hadoop的hdfs的,所以在安装HBase之前,必须要安装Hadoop,并确保hdfs正常。
Hadoop的配置重点是各个配置文件,这里只罗列各个配置文件的基础信息(经验证,这些基本上是必须要配置的),
需要配置环境变量的同时,共需要修改如下文件:
配置文件路径:/home/hadmin/hadoop-2.7.4/etc/hadoop
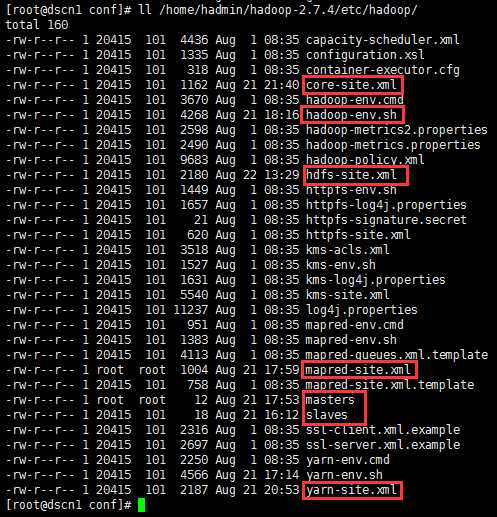
1、环境变量

2、hadoop-env.sh
修改JAVA_HOME即可。

3、core-site.xml
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://ns</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/home/hadmin/data/hadoop/tmp</value> </property> <property> <name>dfs.journalnode.edits.dir</name> <value>/home/hadmin/data/hadoop/journal</value> </property> <property> <name>ha.zookeeper.quorum</name> <value>dscn1:2181,dscn2:2181,dscn3:2181</value> </property> </configuration>
4、hdfs-site.xml
<configuration> <property> <name>dfs.replication</name> <value>2</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>/home/hadmin/data/hadoop/hdfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>/home/hadmin/data/hadoop/hdfs/data</value> </property> <property> <name>dfs.permissions</name> <value>false</value> </property> <property> <name>dfs.nameservices</name> <value>ns</value> </property> <property> <name>dfs.ha.namenodes.ns</name> <value>nn1,nn2</value> </property> <property> <name>dfs.namenode.rpc-address.ns.nn1</name> <value>dscn1:9000</value> </property> <property> <name>dfs.namenode.rpc-address.ns.nn2</name> <value>dscn2:9000</value> </property> <property> <name>dfs.namenode.http-address.ns.nn1</name> <value>dscn1:50070</value> </property> <property> <name>dfs.namenode.http-address.ns.nn2</name> <value>dscn2:50070</value> </property> <property> <name>dfs.namenode.shared.edits.dir</name> <value>qjournal://dscn1:8485;dscn2:8485;dscn3:8485/ns</value> </property> <property> <name>dfs.ha.automatic-failover.enabled.ns</name> <value>true</value> </property> <property> <name>dfs.client.failover.proxy.provider.ns</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> </property> <property> <name>dfs.ha.fencing.methods</name> <value>shell(/home/hadmin/dscs/bin/hdfs-fencing.sh)</value> </property> </configuration>
5、mapred-site.xml
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapreduce.reduce.memory.mb</name> <value>128</value> </property> <property> <name>mapreduce.map.memory.mb</name> <value>256</value> </property> </configuration>
6、yarn-site.xml
<configuration> <!-- Site specific YARN configuration properties --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.resourcemanager.ha.enabled</name> <value>true</value> </property> <property> <name>yarn.nodemanager.vmem-check-enabled</name> <value>false</value> </property> <property> <name>yarn.resourcemanager.cluster-id</name> <value>ns</value> </property> <property> <name>yarn.resourcemanager.ha.rm-ids</name> <value>rm1,rm2</value> <property> <name>yarn.resourcemanager.hostname.rm1</name> <value>dscn1</value> </property> <property> <name>yarn.resourcemanager.hostname.rm2</name> <value>dscn2</value> </property> <property> <name>yarn.resourcemanager.webapp.address.rm1</name> <value>dscn1:8088</value> </property> <property> <name>yarn.resourcemanager.webapp.address.rm2</name> <value>dscn2:8088</value> </property> <property> <name>yarn.resourcemanager.zk-address</name> <value>dscn1:2181,dscn2:2181,dscn3:2181</value> </property> <property> <name>yarn.resourcemanager.recovery.enabled</name> <value>true</value> </property> <property> <name>yarn.resourcemanager.store.class</name> <value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value> </property> <property> <name>yarn.nodemanager.resource.memory-mb</name> <value>1024</value> </property> <property> <name>yarn.scheduler.minimum-allocation-mb</name> <value>256</value> </property> <property> <name>yarn.scheduler.maximum-allocation-mb</name> <value>1024</value> </property> </configuration>
7、masters
dscn1
dscn2
8、slaves
dscn1
dscn2
dscn3
上述几个文件配置完毕之后,按照如下顺序启动
1、在dscn1上
hdfs zkfc -formatZK
2、在3节点分别启动:
hadoop-daemon.sh start journalnode
3、在dscn1上:
hdfs namenode -format
hadoop-daemon.sh start namenode
4、在dscn2上:
hdfs namenode -bootstrapStandby
hadoop-daemon.sh start namenode
5、在dscn1和dscn2上:
hadoop-daemon.sh start zkfc
6、在3个节点分别启动:
hadoop-daemon.sh start datanode
7、在dscn1上:
start-yarn.sh
1、在dscn1上:
start-all.sh
2、在dscn1和dscn2上:
hadoop-daemon.sh start zkfc
stop-all.sh
安装是否正常,可以通过如下方式验证:
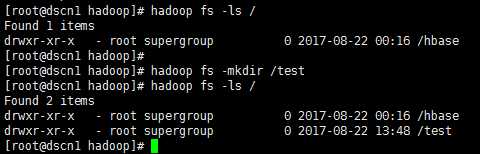
1、通过hadoop命令来操作hdfs
浏览hdfs根目录:hadoop fs -ls /
创建文件夹:hadoop fs -mkdir /test
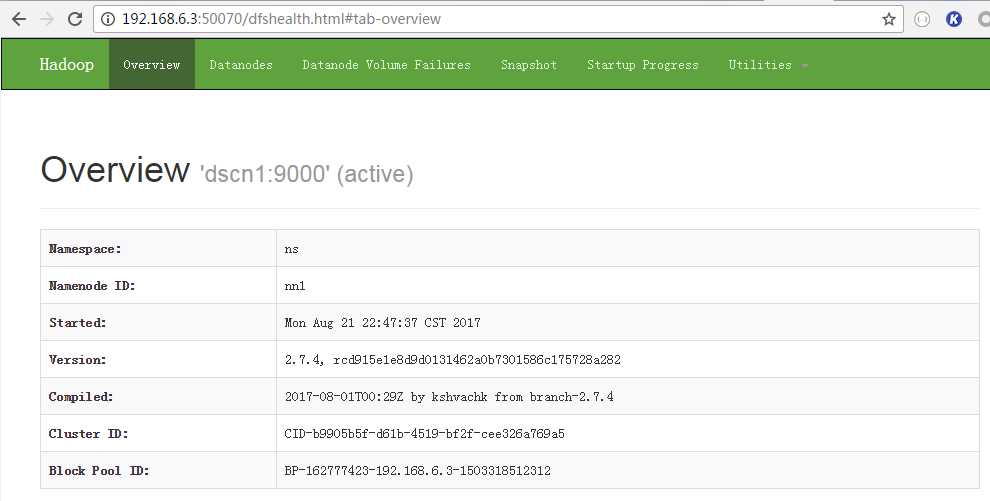
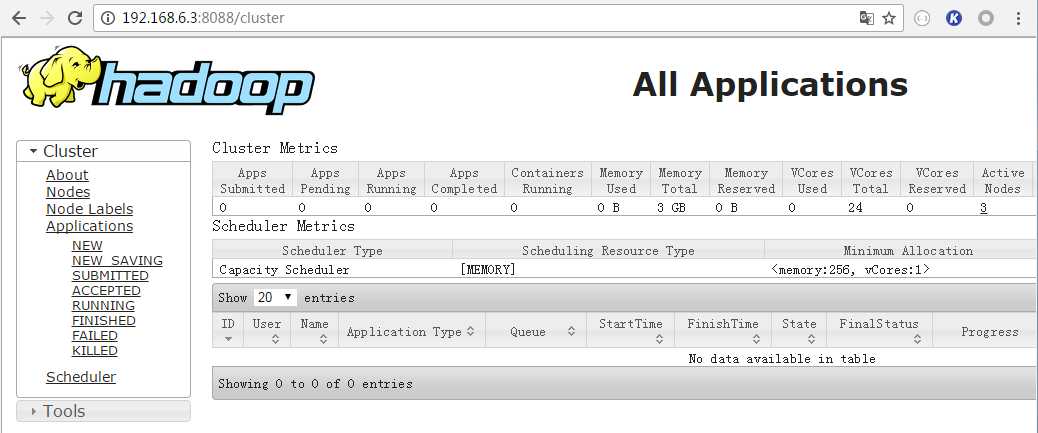
2、通过浏览器可以查看Hadoop集群状态
其中,两个namenode,需要有一个保持active状态
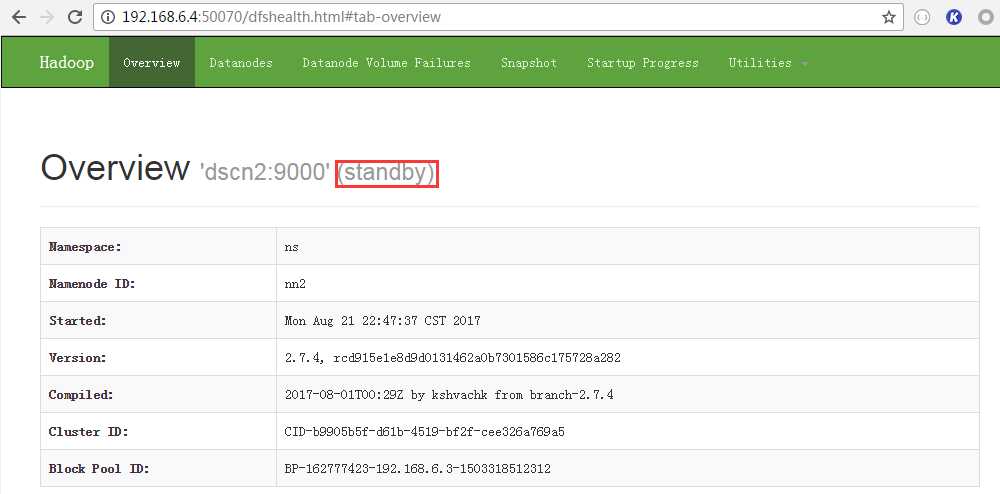
3、通过浏览器可以查看hadoop applications状态
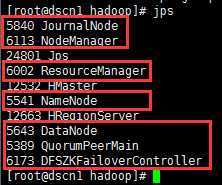
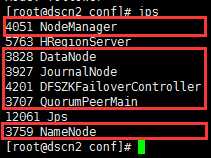
4、3个节点的jps进程如下:
dscn1:
dscn2:
dscn3:
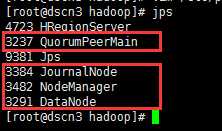
hbase的安装相对简单,主要完成以下文件的配置:
1、hbase-env.sh
export HBASE_MANAGES_ZK=false
export HBASE_CLASSPATH=/home/hadmin/hadoop-2.7.4/etc/hadoop
其中,第二个配置一定要注意,这个配置的目的是让HBase能够找到hadoop的配置文件,从而与hdfs建立练习,如果不配置这个,会出现如下错误:
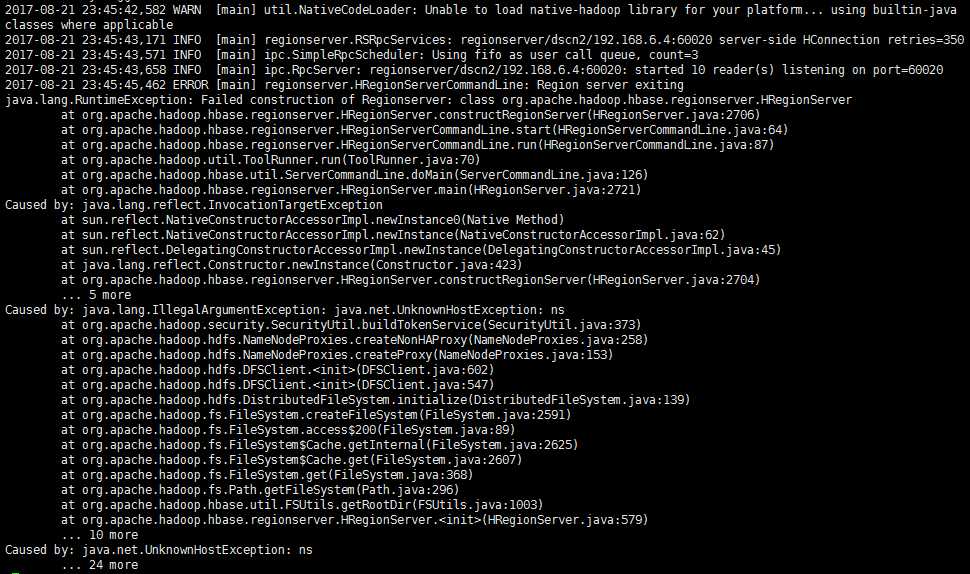
另外,官方文档上也提到了这点,并提供了2种解决方法,我这里采用的是"方法a"。

2、hbase-site.xml
<configuration>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.tmp.dir</name>
<value>/home/hadmin/data/hbase/tmp</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>dscn1,dscn2,dscn3</value>
</property>
<property>
<name>hbase.rootdir</name>
<value>hdfs://ns/hbase</value>
</property>
<property>
<name>hbase.master.port</name>
<value>60000</value>
</property>
<property>
<name>hbase.master.info.port</name>
<value>60010</value>
</property>
<property>
<name>hbase.regionserver.port</name>
<value>60020</value>
</property>
<property>
<name>hbase.regionserver.info.port</name>
<value>60030</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/home/hadmin/data/zk/data</value>
</property>
</configuration>
按照上述的配置文件完成配置之后,就可以启动HBase了
启动命令:/home/hadmin/hbase-1.3.1/bin/start-hbase.sh
停止命令:/home/hadmin/hbase-1.3.1/bin/stop-hbase.sh
启动之后,可以通过如下几个方面来验证HBase集群是否正常。
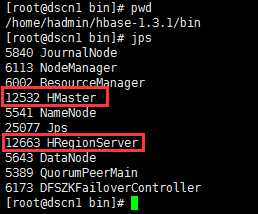
1、查看jps进程
dscn1:
dscn2:
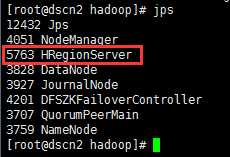
dscn3:
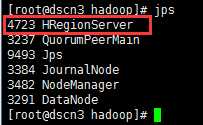
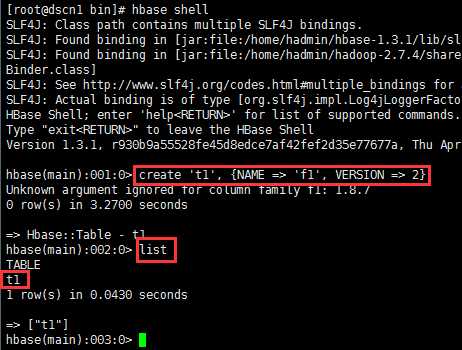
2、通过HBase shell控制台,创建表:
如下图所示:
建表命令:create ‘t1‘, {NAME => ‘f1‘, VERSION => 2}
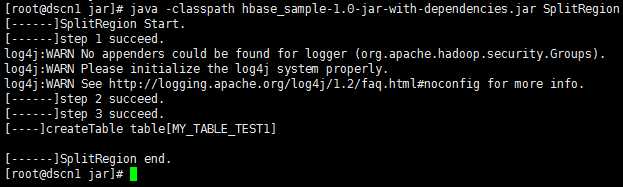
3、通过程序连接HBase,创建表:
如下程序中,建立了一张MY_TABLE_TEST1的表,并且进行了预分区。
建表程序如下:
import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.hbase.HBaseConfiguration; import org.apache.hadoop.hbase.HColumnDescriptor; import org.apache.hadoop.hbase.HTableDescriptor; import org.apache.hadoop.hbase.client.HBaseAdmin; import org.apache.hadoop.hbase.io.compress.Compression; import org.apache.hadoop.hbase.regionserver.BloomType; import org.apache.hadoop.hbase.util.Bytes; public class SplitRegion { private static final String TABLE_NAME = "MY_TABLE_TEST1"; private static final String COLUMN_FAMILY = "df"; public static void main(String[] args) throws Exception { System.out.print("[------]SplitRegion Start.\n"); Configuration configuration= HBaseConfiguration.create(); System.out.print("[------]step 1 succeed.\n"); configuration.set("hbase.zookeeper.quorum", "192.168.6.3,192.168.6.4,192.168.6.5"); HBaseAdmin admin = new HBaseAdmin(configuration); System.out.print("[------]step 2 succeed.\n"); String table_name = TABLE_NAME; if (admin.tableExists(table_name)) { admin.disableTable(table_name); System.out.println("[----]disableTable table[" + table_name + "]\n"); admin.deleteTable(table_name); System.out.println("[----]deleteTable table[" + table_name + "]\n"); } HTableDescriptor desc = new HTableDescriptor(table_name); HColumnDescriptor family = new HColumnDescriptor(COLUMN_FAMILY.getBytes()); //过期时间 family.setTimeToLive(3 * 60 * 60 * 24); //按行过滤 family.setBloomFilterType(BloomType.ROW); desc.addFamily(family); System.out.print("[------]step 3 succeed.\n"); byte[][] splitKeys = { Bytes.toBytes("0"), Bytes.toBytes("2"), Bytes.toBytes("4"), Bytes.toBytes("6"), Bytes.toBytes("8"), }; admin.createTable(desc, splitKeys); System.out.println("[----]createTable table[" + table_name + "]\n"); System.out.print("[------]SplitRegion end.\n"); } }
工程pom.xml如下:
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <artifactId>hbase_sample</artifactId> <groupId>hbase_sample</groupId> <version>1.0</version> <modelVersion>4.0.0</modelVersion> <dependencies> <dependency> <groupId>org.apache.hbase</groupId> <artifactId>hbase-client</artifactId> <version>1.3.1</version> </dependency> <dependency> <groupId>org.apache.hbase</groupId> <artifactId>hbase-server</artifactId> <version>1.3.1</version> </dependency> <dependency> <groupId>org.apache.hbase</groupId> <artifactId>hbase-common</artifactId> <version>1.3.1</version> </dependency> </dependencies> <build> <sourceDirectory>src/main/java</sourceDirectory> <outputDirectory>target/classes</outputDirectory> <plugins> <plugin> <artifactId>maven-compiler-plugin</artifactId> <version>3.1</version> <configuration> <source>1.7</source> <target>1.7</target> </configuration> </plugin> <plugin> <artifactId>maven-assembly-plugin</artifactId> <version>2.4</version> <configuration> <descriptorRefs> <descriptorRef>jar-with-dependencies</descriptorRef> </descriptorRefs> </configuration> <executions> <execution> <id>make-assembly</id> <phase>package</phase> <goals> <goal>single</goal> </goals> </execution> </executions> </plugin> </plugins> </build> </project>
通过maven,将程序编译完成,上传jar包只服务器,运行程序结果如下:
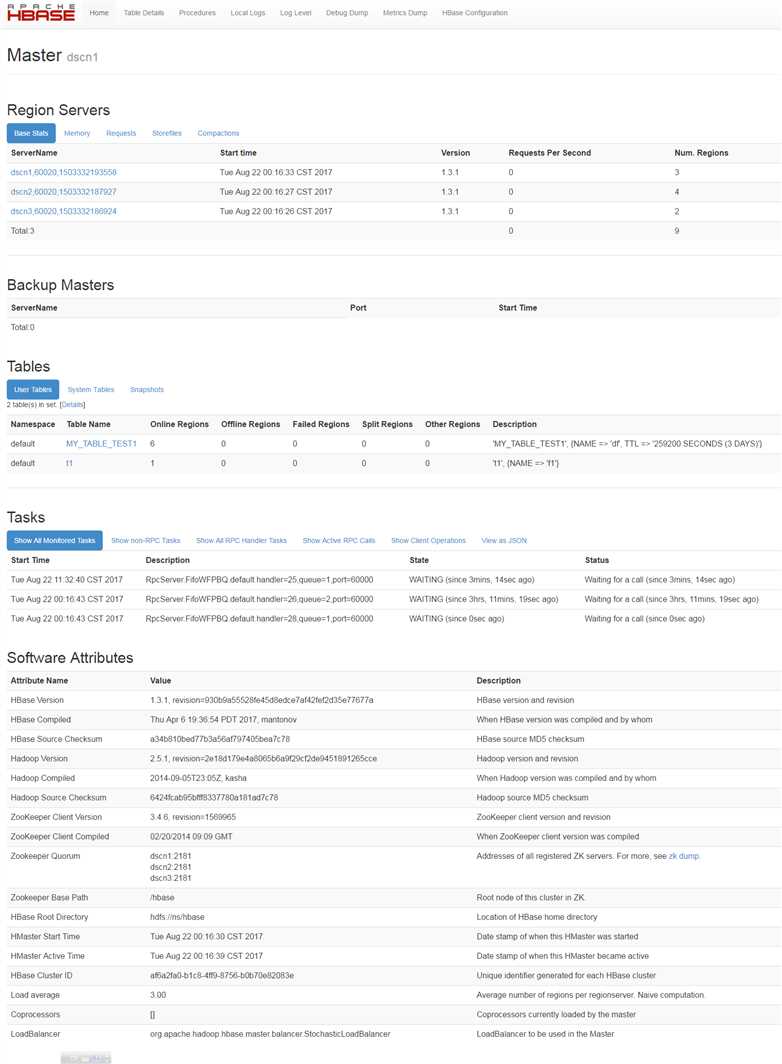
4、通过浏览器访问HBase管理界面:
地址:http://192.168.6.3:60010/
从图中可以看到,有3个Region Server,并有通过命令创建的【t1】表,以及通过程序创建的【MY_TABLE_TEST1】表。
<configuration> <!-- RegionServer的共享目录,用来持久化HBase。 默认情况下HBase是写到/tmp的。不改这个配置,数据会在重启的时候丢失。 --> <property> <name>hbase.rootdir</name> <value>hdfs://ns/hbase</value> </property> <!-- HBase的运行模式。false是单机模式,true是分布式模式。 若为false, HBase和Zookeeper会运行在同一个JVM里面。 默认: false --> <property> <name>hbase.cluster.distributed</name> <value>true</value> </property> <!-- Zookeeper集群的地址列表,用逗号分割。 如果在hbase-env.sh设置了HBASE_MANAGES_ZK,这些ZooKeeper节点就会和HBase一起启动。 默认: localhost。 部署的zookeeper越多,可靠性就越高,但是部署只能部署奇数个,主要为了便于选出leader。最好给每个zookeeper 1G的内存和独立的磁盘,可以确保高性能。hbase.zookeeper.property.dataDir可以修改zookeeper保存数据的路径。 --> <property> <name>hbase.zookeeper.quorum</name> <value>dscn11,dscn12,dscn13</value> </property> <!-- 本地文件系统的临时文件夹。 可以修改到一个更为持久的目录上。(/tmp会在重启时清除) 默认:${Java.io.tmpdir}/hbase-${user.name} --> <property> <name>hbase.tmp.dir</name> <value>/home/hadmin/data/hadoop</value> </property> <!-- 最大HStoreFile大小。 若某个列族的HStoreFile增长达到这个值,这个Hegion会被切割成两个。 默认:10737418240(10G) 小region对split和compaction友好,因为拆分region或compact小region里的storefile速度很快,内存占用低。 缺点是split和compaction会很频繁。 特别是数量较多的小region不停地split, compaction,会导致集群响应时间波动很大,region数量太多不仅给管理上带来麻烦,甚至会引发一些Hbase的bug。 一般512以下的都算小region。 大region,则不太适合经常split和compaction,因为做一次compact和split会产生较长时间的停顿,对应用的读写性能冲击非常大。 此外,大region意味着较大的storefile,compaction时对内存也是一个挑战。 当然,大region也有其用武之地。如果你的应用场景中,某个时间点的访问量较低, 那么在此时做compact和split,既能顺利完成split和compaction,又能保证绝大多数时间平稳的读写性能。 既然split和compaction如此影响性能,有没有办法去掉? compaction是无法避免的,split倒是可以从自动调整为手动。 只要通过将这个参数值调大到某个很难达到的值,比如100G,就可以间接禁用自动split(RegionServer不会对未到达100G的region做split)。 再配合RegionSplitter这个工具,在需要split时,手动split。 手动split在灵活性和稳定性上比起自动split要高很多,相反,管理成本增加不多,比较推荐online实时系统使用。 内存方面,小region在设置memstore的大小值上比较灵活,大region则过大过小都不行,过大会导致flush时app的IO wait增高,过小则因store file过多影响读性能。 --> <property> <name>hbase.hregion.max.filesize</name> <value>1073741824</value> </property> <!-- RegionServers受理的RPC Server实例数量。 对于Master来说,这个属性是Master受理的handler数量 默认: 10 RegionServer的请求处理IO线程数。 这个参数的调优与内存息息相关。 较少的IO线程,适用于处理单次请求内存消耗较高的Big PUT场景(大容量单次PUT或设置了较大cache的scan,均属于Big PUT)或ReigonServer的内存比较紧张的场景。 较多的IO线程,适用于单次请求内存消耗低,TPS要求非常高的场景。设置该值的时候,以监控内存为主要参考。 这里需要注意的是如果server的region数量很少,大量的请求都落在一个region上,因快速充满memstore触发flush导致的读写锁会影响全局TPS,不是IO线程数越高越好。 --> <property> <name>hbase.regionserver.handler.count</name> <value>600</value> </property> <!-- 如果memstore有hbase.hregion.memstore.block.multiplier倍数的hbase.hregion.flush.size的大小,就会阻塞update操作。 这是为了预防在update高峰期会导致的失控。如果不设上界,flush的时候会花很长的时间来合并或者分割,最坏的情况就是引发out of memory异常。 默认: 2 当一个region里的memstore占用内存大小超过hbase.hregion.memstore.flush.size两倍的大小时,block该region的所有请求,进行flush,释放内存。 虽然我们设置了region所占用的memstores总内存大小,比如64M,但想象一下,在最后63.9M的时候,我Put了一个200M的数据, 此时memstore的大小会瞬间暴涨到超过预期的hbase.hregion.memstore.flush.size的几倍。 这个参数的作用是当memstore的大小增至超过hbase.hregion.memstore.flush.size 2倍时,block所有请求,遏制风险进一步扩大。 调优: 这个参数的默认值还是比较靠谱的。如果你预估你的正常应用场景(不包括异常)不会出现突发写或写的量可控,那么保持默认值即可。 如果正常情况下,你的写请求量就会经常暴长到正常的几倍,那么你应该调大这个倍数并调整其他参数值, 比如hfile.block.cache.size和hbase.regionserver.global.memstore.upperLimit/lowerLimit,以预留更多内存,防止HBase server OOM。 --> <property> <name>hbase.hregion.memstore.block.multiplier</name> <value>8</value> </property> <!-- 当memstore的大小超过这个值的时候,会flush到磁盘。 这个值被一个线程每隔hbase.server.thread.wakefrequency检查一下。 默认:134217728(128M) --> <property> <name>hbase.hregion.memstore.flush.size</name> <value>33554432</value> </property> <!-- 默认值:0.4 这个参数的作用是防止内存占用过大,当ReigonServer内所有region的memstores所占用内存总和达到heap的40%时, HBase会强制block所有的更新并flush这些region以释放所有memstore占用的内存。 调优:这是一个Heap内存保护参数,默认值已经能适用大多数场景。 参数调整会影响读写,如果写的压力大导致经常超过这个阀值,则调小读缓存hfile.block.cache.size增大该阀值,或者Heap余量较多时,不修改读缓存大小。 如果在高压情况下,也没超过这个阀值,那么建议你适当调小这个阀值再做压测,确保触发次数不要太多,然后还有较多Heap余量的时候,调大hfile.block.cache.size提高读性能。 还有一种可能性是?hbase.hregion.memstore.flush.size保持不变,但RS维护了过多的region,要知道 region数量直接影响占用内存的大小。 --> <property> <name>hbase.regionserver.global.memstore.size</name> <value>0.5</value> </property> <!-- BucketCache工作模式。heap、offheap和file 默认:none 这三种工作模式在内存逻辑组织形式以及缓存流程上都是相同的,参见上节讲解。不同的是三者对应的最终存储介质有所不同。 其中heap模式和offheap模式都使用内存作为最终存储介质, heap模式分配内存会从JVM提供的heap区分配,而后者会直接从操作系统分配。这两种内存分配模式会对HBase实际工作性能产生一定的影响。 影响最大的无疑是GC ,相比heap模式,offheap模式因为内存属于操作系统,所以基本不会产生CMS GC,也就在任何情况下都不会因为内存碎片导致触发Full GC。 除此之外,在内存分配以及读取方面,两者性能也有不同, 比如,内存分配时heap模式需要首先从操作系统分配内存再拷贝到JVMheap,相比offheap直接从操作系统分配内存更耗时; 但是反过来,读取缓存时heap模式可以从JVM heap中直接读取,而offheap模式则需要首先从操作系统拷贝到JVM heap再读取,显得后者更费时。 file模式和前面两者不同,它使用Fussion-IO或者SSD等作为存储介质,相比昂贵的内存,这样可以提供更大的存储容量,因此可以极大地提升缓存命中率。 --> <property> <name>hbase.bucketcache.ioengine</name> <value>offheap</value> </property> <!-- 分配给HFile/StoreFile的block cache占最大堆(-Xmx setting)的比例。 默认0.25意思是分配25%。设置为0就是禁用,但不推荐。 storefile的读缓存占用Heap的大小百分比,0.2表示20%。该值直接影响数据读的性能。 当然是越大越好,如果写比读少很多,开到0.4-0.5也没问题。 如果读写较均衡,0.3左右。如果写比读多,果断默认吧。 设置这个值的时候,你同时要参考?hbase.regionserver.global.memstore.upperLimit?, 该值是memstore占heap的最大百分比,两个参数一个影响读,一个影响写。如果两值加起来超过80-90%,会有OOM的风险,谨慎设置。 --> <property> <name>hfile.block.cache.size</name> <value>0.3</value> </property> <!-- bucketcache的大小,小于1时为整体内存的比例,大于等于1时为cache的实际容量,单位M。默认0 --> <property> <name>hbase.bucketcache.size</name> <value>25600</value> </property> <!-- hdfs的副本数 默认:3 --> <property> <name>dfs.replication</name> <value>1</value> </property> <!-- 是否使用HBase Replication(集群复制)功能 默认:false HBase默认此特性是关闭的,需要在集群上(所有集群)进行设定并重启集群, --> <property> <name>hbase.replication</name> <value>true</value> </property> <!-- --> <property> <name>replication.source.maxretriesmultiplier</name> <value>300</value> </property> <!-- --> <property> <name>replication.source.sleepforretries</name> <value>1</value> </property> <!-- --> <property> <name>replication.sleep.before.failover</name> <value>30000</value> </property> </configuration>
====HBase集群操作命令(待更新)====
====HBase集群备份及恢复(待更新)====
====HBase集群复制(待更新)====
====HBase快照(待更新)====
--END--
标签:with 写锁 dep for output ice 单位 info stat
原文地址:http://www.cnblogs.com/quchunhui/p/7411389.html