标签:bin 技术 优先 http 本地 缓存 最小 jdk1.7 tor
一:基本属性
1.查看属性

2.解释属性
NAME:列簇名
BLOOMFILTER:布隆过滤器,用于对storefile的过滤
共有三种类型:
ROW:行健过滤
ROWCOL:行列过滤
NONE:无
VERSIONS:版本数
MIN_VERSIONS:最小版本数
TTL:版本存货活时间
BLOCKSIZE:数据块的大小,默认64KB
IN_MEMORY:激进内存,赋予一些列簇在缓存中具有较高的优先级
BLOCKCACHE:数据块缓存,可以将常用的列簇设为true,不常使用的设为false。
二:关于压缩问题COMPRESSION
1.需要hadoo具有压缩支持bin/hadoop checknative
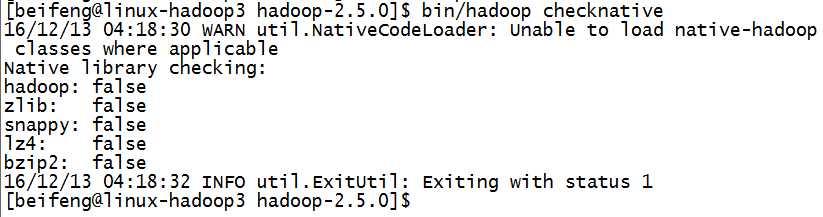
)所以,需要安装压缩本地库
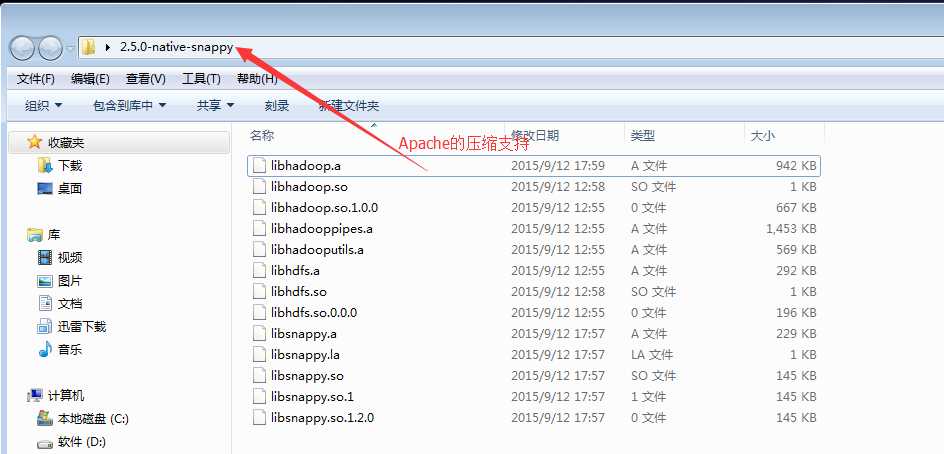
)同时,上传jar包
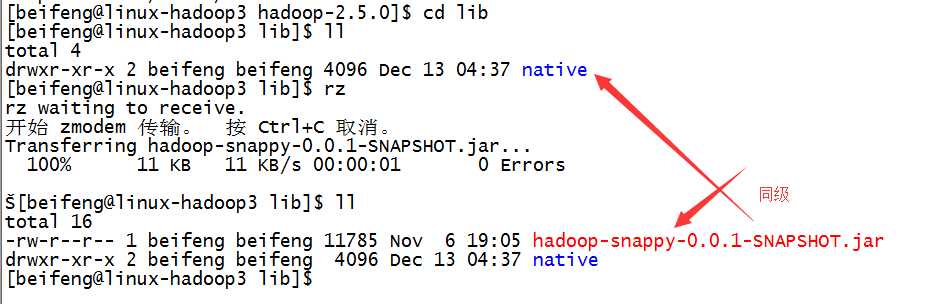
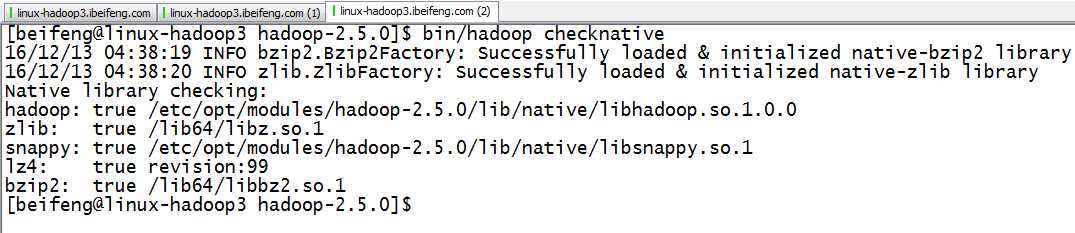
2.再次检查hadoop
3.将jar包上传到hbase的lib中

4.将hadoop的native拷贝到hbase的lib下

5.新建文件

6.拷贝native到jdk
hbase-0.98.6-hadoop2] $ cp ../hadoop-2.5.0/lib/native/* ../jdk1.7.0_67/jre/lib/amd64/
7.重启集群
8.测试

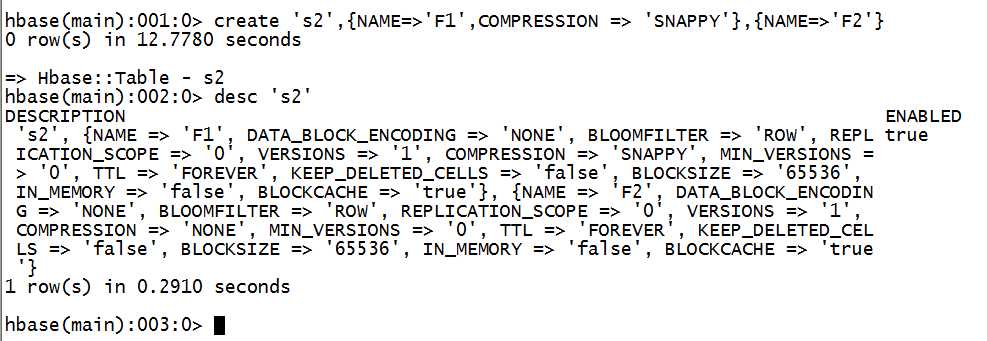
三:创建
create ‘s2‘,{NAME=>‘F1‘,COMPRESSION => ‘SNAPPY‘},{NAME=>‘F2‘}
标签:bin 技术 优先 http 本地 缓存 最小 jdk1.7 tor
原文地址:http://www.cnblogs.com/RHadoop-Hive/p/7413955.html