标签:manage query img max ext 字典 分享 entry png
IK分词器就是一款中国人开发的,扩展性很好的中文分词器,它支持扩展词库,可以自己定制分词项,这对中文分词无疑是友好的。
jar包下载链接:http://pan.baidu.com/s/1o85I15o 密码:p82g
下载好之后,将IK对应的jar复制到项目的D:\tomcat\webapps\solr\WEB-INF\lib下面,然后在WEB-INF下面创建一个classes的目录,将其余三个文件(IKAnalyzer.cfg.xml , ext.dic和stopword.dic)复制到这个classes目录下。
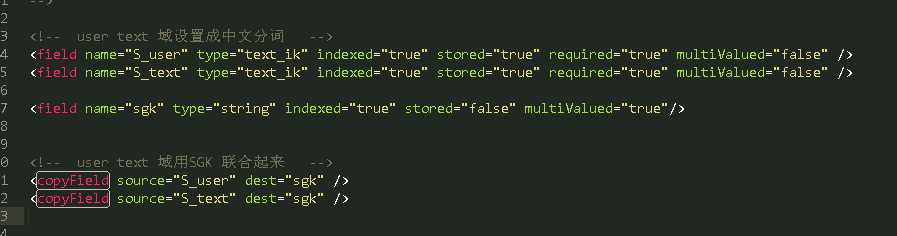
打开D:\solrhome\core_demo\conf 下的managed-schema,添加:
<!-- K分词 -->
<fieldType name="text_ik" class="solr.TextField">
<analyzer type="index" isMaxWordLength="false" class="org.wltea.analyzer.lucene.IKAnalyzer"/>
<analyzer type="query" isMaxWordLength="true" class="org.wltea.analyzer.lucene.IKAnalyzer"/>
</fieldType>

同时,把需要分词的字段,设置为text_ik。type属性=text_ik,也就是我们自定义的IK中文分词
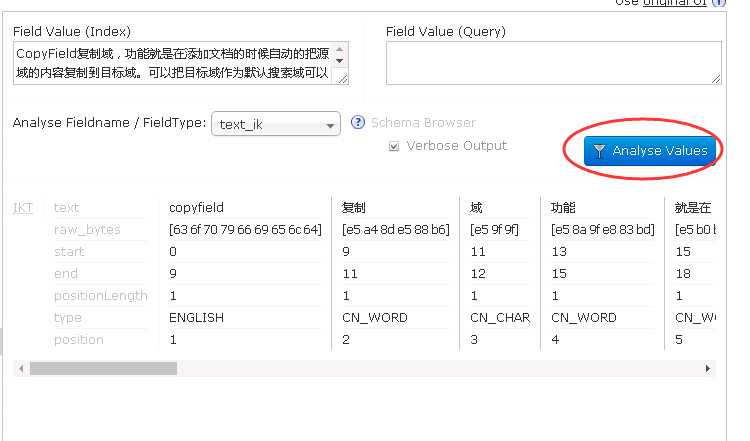
现在我们测试中文分词
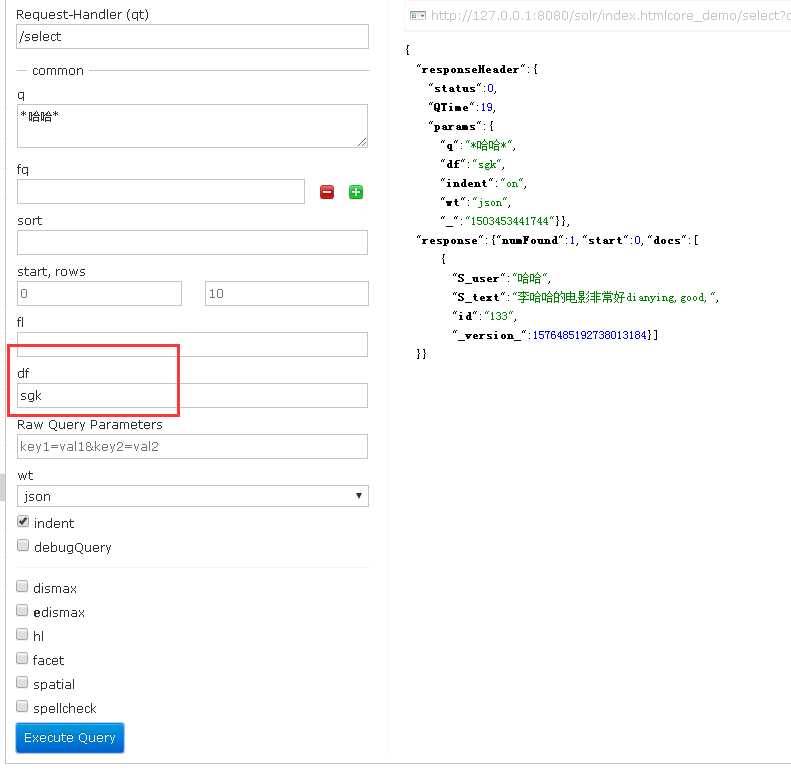
另外,解释一下IK的配置,其中IKAnalyzer.cfg.xml为配置文件,主要用来配置扩展词库,禁止词词库等
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict">ext.dic;</entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords">stopword.dic;</entry>
</properties>
这里说下useSmart,我试过,当设置为true时,分词粒度比较小,支取权重比较高的分词,当设置为false时,分词粒度比较小,能匹配多个词;
到这里,IKAnalyzer就算配置完毕,可以直接在后台调试分词了
标签:manage query img max ext 字典 分享 entry png
原文地址:http://www.cnblogs.com/xiumuzidiao/p/7419568.html