标签:设置 使用 更新 取数 编程语言 src com 数据源 它的
1、storm介绍
storm是一种用于事件流处理的分布式计算框架,它是有BackType公司开发的一个项目,于2014年9月加入了Apahche孵化器计划并成为其旗下的顶级项目之一。Storm可以方便地在一个计算机集群中编写与扩展复杂的实时计算,Storm用于实时处理,就好比 Hadoop 用于批处理。Storm保证每个消息都会得到处理,而且它很快——在一个小集群中,每秒可以处理数以百万计的消息。更棒的是你可以使用任意编程语言来做开发。storm源码:githup
storm特点:
简单的编程模型:可以在storm之上使用各种编程语言,默认支持Clojure、Java、Ruby和Python,要增加对其他语言的支持,只需实现一个简单的storm通信协议即可
容错性:Storm会管理工作进程和节点的故障
水平扩展:计算是在多个线程、进程和服务器之间进行的
可靠的消息处理:Storm保障每个消息至少能得到一次完整处理。任务失败时,它会负责从消息源重试消息
快速:系统的设计保证了消息能够得到快速的处理,使用?MQ作为其底层消息队列
本地模式:Storm有一个本地模式,可以在处理过程中完全模拟集群模式,这可以让你快速进行开发和单元测试
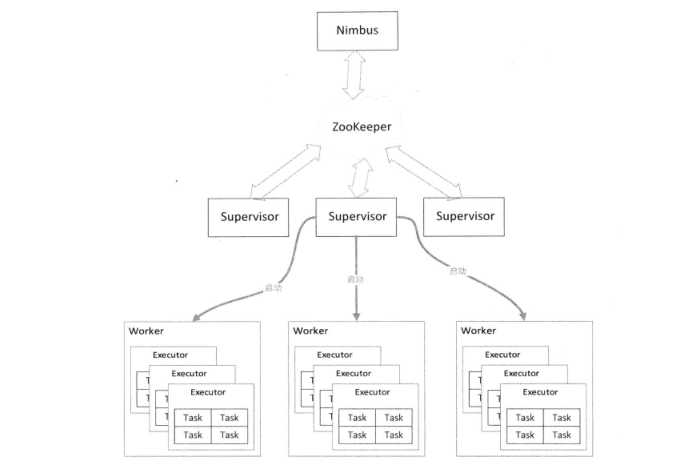
2、总体架构
storm中涉及的术语
Nimbus:主节点运行的一个守护进程,用于分配代码、布置任务以及故障的检测
Supervisor:工作几点运行的一个守护进程,用于监听工作,开始并终止工作进程
Zookeeper:Nimbus和Supervisor都能快速失败,而且是无状态的,二者的协调工作由zookeeper进行协调
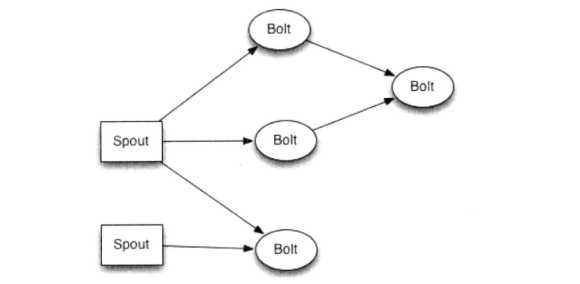
Stream(消息流):被处理的数据
Spout(消息源):数据源
Bolt(消息处理者):封装了数据处理逻辑
Worker(工作进程):工作进程,一个工作进程中可以包含一个或多个Executor线程
Executor:运行Spout或Bolt处理逻辑的线程
Task(任务):Storm中最小处理单元,一个Executor中可以包含一个或多个Task,消息的分发都是从一个Task到另一个Task进行的
Stream Grouping(消息分组策略):定义了消息的分发策略,定义了Bolt节点以何种方式接收数据。消息可以随机分配(Shullf Grouping,随机分组),或根据字段值分配 (Fields Grouping),或者广播(All Grouping,全部分组),或者总是发给同一个Task(Global Grouping ,全局分组), 也可以不关心数据是如何分组的(None Grouping,无分组),或者由自定义逻辑来决定,即由消息发送者决定应该由消息接收者组建的那个Task来处理该消息(Direct Grouping,直接分组)
Topology(计算拓扑):由消息分组方式连接起来的Spout和Bolt的节点网络,它定义了运算处理的拓扑结构,处理的是不断流动的信息。除非杀死Topology,否则它 将永远运行下去
3、storm在zookeeper中的数据存贮及使用
(1)存贮
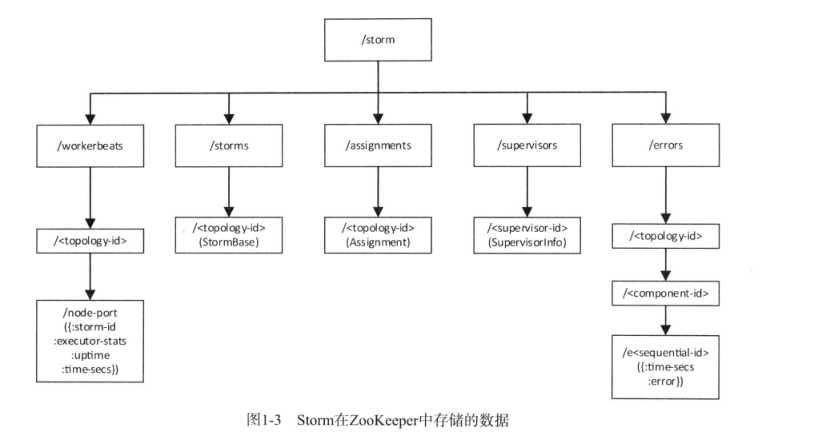
storm采用zookeeper来存贮Nimbus、Supervisor、Worker以及Executor之间共享的元数据,这些模块在重启之后,可以通过对应的元数据进行恢复。因此storm的模块是无状态的,这是保障其可靠性行和扩展性的基础。storm早zookeeper中存贮的数据目录结构如下图所示:
/storm/workbeats/<topology-id>/node-port:它存贮了由node和port指定的Worker的运行状态和一些统计信息。主要包括storm-id(topology-id)、当前Worker上所有的Executor的统计信息(如发送的消息数目、
接收的消息数目等)、当前Worker的启动时间以及最后一次更新这些信息的时间。在一个topology-id下面,可能有多个node-port节点,他的内容在运行过程中会被更新
/storm/storms/topology-id:它存贮topology本身的信息,包括它的名字、启动时间、运行状态、要使用的Worker的数量以及每个组建的并行度设置。它的内容在运行过程中是不变的
/storm/assignments/topology-id:它存贮了Nimbus为每个Topolog分配的任务信息,包括该Topology在Nimbus机器本地的存贮目录,被分到的Supervisor机器到主机名的映射关系,每个Executor运行
在哪个Worker上以及每个Executor的启动时间。该节点的信息在运行过程中会被更新
/storm/supervisor/topology-id:它存贮了 Supervisor机器本身的运行统计信息,主要包括最近一次更新时间、主机名、supervisor-id、已经使用的端口列表、所有的端口列表以及运行时间,该节点的数据在运行
过程中也会被更新
/storm/errors/topology-id/componemt-id/sequential-id:它存贮了运行过程中每个组件上发生的错误信息,sequential-id是一个递增的序列号,每个组件最多只会保存最近的10条错误信息,它的内容在运行过程
中是不变的(但是有可能被删除)
(2)storm和zk的数据交互
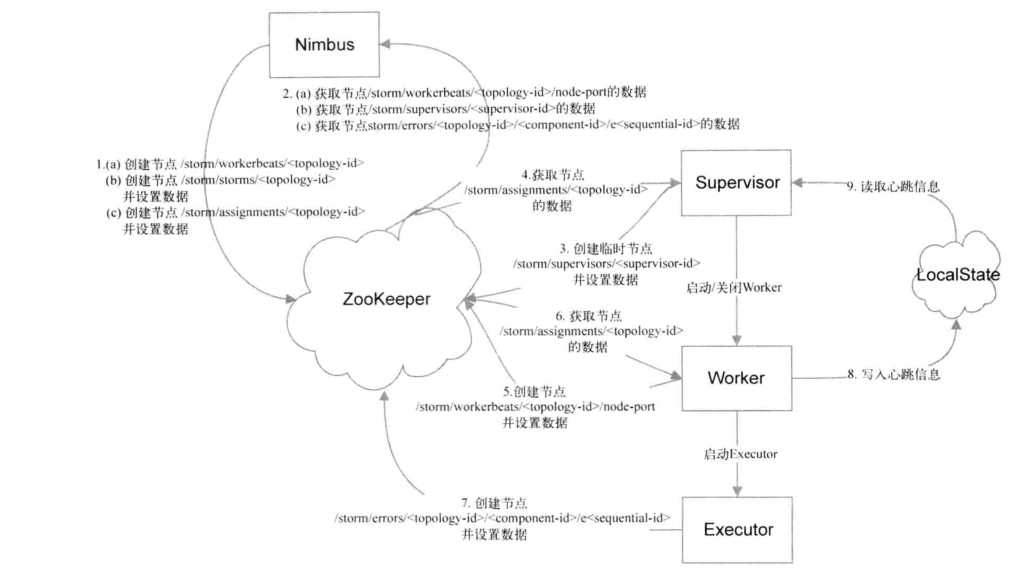
1、Nimbus
Nimbus创建时会创建以下三个节点:
a、/storm/workbeats/topology-id
b、/storm/storms/topology-id
c、/storm/assignments/topology-id
其中对于Nimbus只会创建目录不会设置数据(数据是worker设置的),b和c在创建的同时设置数据。a和b只有再提交新的topology的时候才会创建,并且b中的数据设置完后就不会再变化,
c是再第一次为该topology分配任务的时候创建,若任务分配计划有变,Nimbus就会更新它的内容
Nimbus从zk中获取数据时的路径,包括:
a、/storm/workbeats/topology-id
b、/storm/supervisor/topology-id
c、/storm/errors/topology-id
Nimbus需要从路径a中读取当前已被分配的Worker的运行状态。根据该信息可以得知Worker的状态以及Worker下面所有Executor的统计信息,这些信息会通过UI呈现给用户。
从路径b可以获取所有的Supervisor的状态,当有Supervisor不再活跃时会将它的任务分配到其它的空闲的Supervisor上去。
从路径c中获取所有的错误信息并通过UI呈现给用户
Storm集群中的机器数量时可以动态增减,当机器增减的时候会引起zookeeper中元数据的变化,Nimbus通过从zk中读取这些元数据不断地调整任务分配,所以Storm具有良好的可扩展性。
当Nimbus挂掉时,其他的节点时可以继续工作的,但是不能提交新的Topology,也不能重新进行任务的分配和负载调整,因此目前Nimbus存在单点的问题
2、Supervisor
supervisor除了zk‘来创建和获取元数据外,还可以监控制定的本地文件来检测有它启动的所有的Worker的状态。
-
-
- 箭头3表示Supervisor在zk中创建的节点时/storm/supervisor/topology-id,当有新节点加入时会在该路径下创建一个节点。但是这个节点是临时的,当Supervisor和zk的链接稳定时,这个节点会一直存在,当和zk的连接断开时,该节点会被自动删除。所以该目录下都是当前活跃的机器,。这是Storm可以进行任务分配的基础,也是Storm具有容错性以及扩展性的基础
- 箭头4表示Supervisor需要获取元数据的路径是/storm/assignments/topology-id,它是Nimbus写入的对Topology任务分配的信息,Supervisor可以从该路径获取Nimbus分配给他的所有任务。Supervisor在本地保存着上次的分配信息,对比这两部分的信息可以得知分配信息是否有变化。若发生变化,则需要关闭被移除任务所对应的所有Worker,并启动新的Worker执行新的任务
- 箭头9表示Supervisor会从LocalState中获取由它启动的所有Worker的心跳信息。Supervisor会每隔一段时间检查一次这些心跳信息,当没有某个Worker的心跳信息时,这个Worker就是被kill掉,然后由Nimbus重新分配这个Worker的任务
3、Worker
-
-
- 箭头5表示Worker在zk中创建的路径是/storm/workbeats/topology-id/node-port,当Worker启动时将创建一个对应的节点。Nimbus在创建的时候只会创建/storm/workbeats/topology-id节点,但是不会设置里面的数据,里面的数据由Worker创建,这样做的目的时避免多个Worker同时创建路径冲突
- 箭头6表时Worker会从/storm/workbeats/topology-id节点中获取分配给它的任务并执行
- 箭头8表示Worker在Local State中保存心跳信息,这些心跳信息都保存在本地文件中,Worker用这些信息和Supervisor保持心跳,每隔几秒会更新一次心跳信息
4、Executor
Executor只会利用zk来记录错误信息
-
-
- 箭头7标志Executor在zk中创建的路径是/storm/errors/topology-id/componemt-id/sequential-id,
5、总结
-
-
- Nimnus和Supervisor之间通过/storm/supervisor/topology-id对应的数据进行心跳保持。Supervisor在创建这个路径时采用的时临时节点模式,只要Supervisor死掉这个节点就会被删除,Nimbus就会将分配给这个Supervisor的任务重新进行分配
- Worker和Supervisor之间/storm/workbeats/topology-id/node-port中的数据进行心跳的维持,NImbus会每隔一段时间获取该路径下的数据,同时Nimbus还会在它的内存中保存上一次的信息。如果发现某个Worker的心跳信息有一段时间没有更新就认为该worker已经死掉,就会将分配给该Worker的任务重新分配
- Worker和Supervisor之间维持心跳时通过本地文件(基于LocalState)
storm学习笔记(一)
标签:设置 使用 更新 取数 编程语言 src com 数据源 它的
原文地址:http://www.cnblogs.com/gulang-jx/p/7419678.html