标签:mysql ima 数据集 rand 版本 分配 内部使用 set conf
消息队列是在乐视这边非常普遍使用的技术。在我们部门内部,不同的项目使用的消息队列实现也不一样。下面是支付系统的流转图(部门兄弟画的,借用一下):
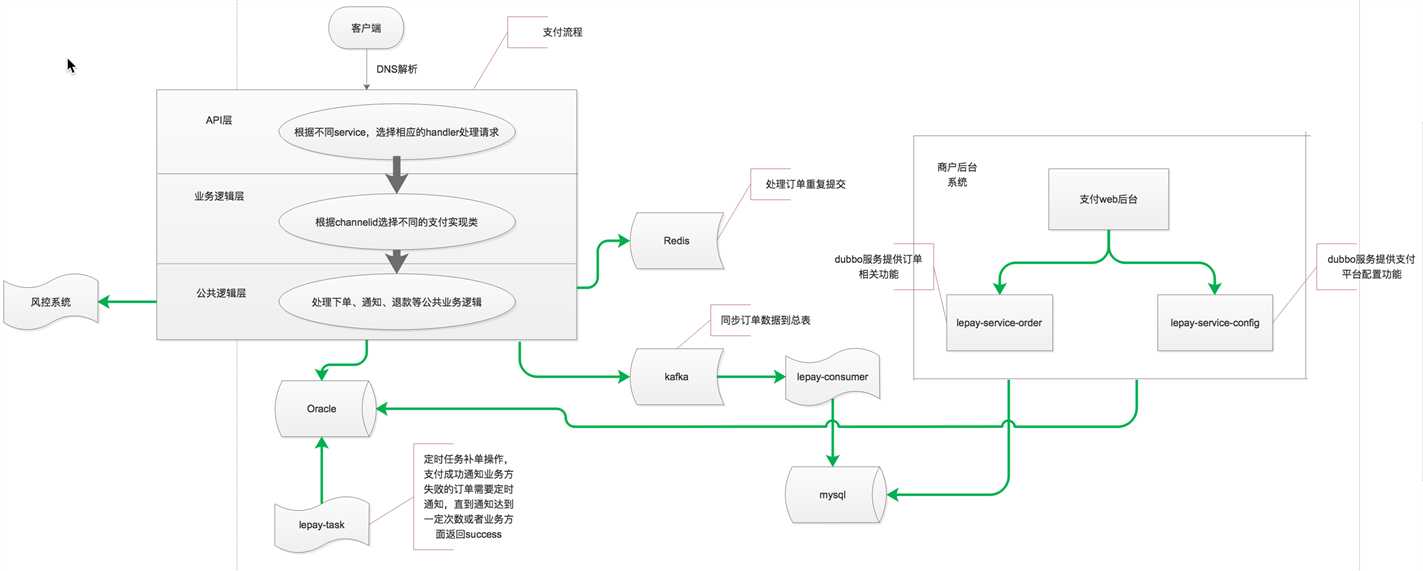
从图中可以看到,里面用到了kafka消息队列。作用是做数据库分库分表后的聚合,异步汇总到一张总表。里面也用到了redis,用来处理高并发下的订单重复提交。我们这边还使用了公司统一集群的apache qpid消息队列,是AMQP的一个实现,主要用于不同部门间的通信。一般的大公司都会有一些公司统一的集群,但是这种统一集群对开发者来说相对透明,所以部门间相互合作的时候用的多,自己部门内部用,避免采坑,大家宁愿自己搭一套。redis用处就更多了。阿里的阳哥自己做了一个异常日志监控平台,主要就是用redis做数据传输和存储。
别人做的东西我就不多说了。下午说说redis在我自己的框架中使用实战。这是epiphany离线数据的流程图。epiphany框架源码地址:https://github.com/xiexiaojing/epiphany。我们部门内部使用实例地址是:https://github.com/xiexiaojing/epiphany-demo。大家可以将里面的DAO部分数据做替换,替换成自己的数据库随便什么数据即可运行。
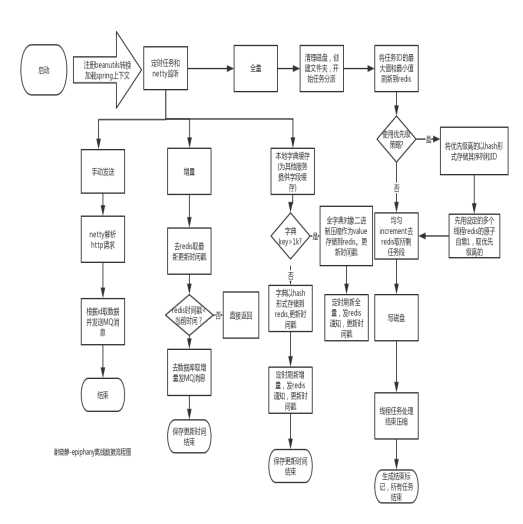
从图中可以看到处理过程基本都是在和redis打交道。Redis的基本数据结构是跳跃表。像这种跟存储打交道的,数据结构是必须要了解的。比如lucene搜索最初的版本也是用的跳跃表,后来改成基于图的有限自动机了。想了解具体了解跳跃表可以看我的另一篇文章《看Lucene源码必须知道的基本规则和算法》。像一些java写的框架,比如dubbo,spring IoC里,一提到注册,要注册到一个地方,在JVM的数据结构一般是hashmap。准确的说:spring IoC里是通过一个hashmap来持有载入的BeanDefinition对象实现注册的。
Redis持久化原理
Redis提供了两种方式对数据进行持久化,分别是RDB(Redis DataBase)和AOF(APPEND ONLY FILE)。RDB持久化方式能够在指定的时间间隔对数据进行快照存储。AOF持久化方式记录每次服务器写的操作,当服务器重启的时候会重新执行这些命令来恢复原始的数据,AOF命令以redis协议追加保存每次写操作到文件末尾。Redis还能对AOF文件进行后台重写,使得AOF文件的体积不至于过大。不过,我问过很多部门,出于性能考虑,他们的持久化都是不开启的。如果同时开启两种持久化方式,当redis重启的时候会优先载入AOF文件来恢复原始的数据,因为在通常情况下AOF文件保存的数据集要比RDB文件保存的数据集要完整。
了解一下持久化的C语言实现。Redis需要之执行RDB的时候,服务器会执行以下操作:redis调用系统函数fork(),创建一个子进程。子进程将数据集写入到一个临时RDB文件中。当子进程完成对临时RDB文件的写入时,redis用新的临时RDB文件替换原来的RDB文件,并删除旧RDB文件。在执行fork时linux操作系统(一般大公司的服务器都是这个系统)会使用写时复制(copy-on-write)策略,即fork函数发生的一刻父子进程共享同一内存数据,当父进程要更新其中某片数据时,操作系统会将该片数据复制一份以保证子进程的数据不收影响,所以新的RDB文件存储的是之执行fork那一刻的内存数据。RDB文件是经过压缩的二进制格式,所以占用的空间会小于内存的数据大小。但是压缩操作很占CPU,所以可以通过配置文件配置禁止压缩。
了解一下对应的redis命令。除了自动快照,还可以手动发送save或者bgsave命令让redis直行快照。save命令是在主进程上进行的,会阻塞其他请求。后者会fork子进程进行快照操作。
和mysql存储比较。RDB方式比较类似于mysql的mysqldump命令备份。而AOF更接近于binlog。
Redis内存优化
redis配置文件中有个maxmemory参数设置,如果没有设置会继续分配内存,因此可以逐渐吃掉所有可用内存。因此,通常建议配置一些限制和策略。这样做的优点是:不会导致因为内存饥饿而整机死亡。缺点是:Redis可能会返回内存不足的错误写命令。redis有6种过期策略。
1>volatile-lru:只对设置了过期时间的key进行LRU
2>allkeys-lur:对所有的key进行LRU
3>volatile-random:随机删除即将过期的key
4>allkeys-random:从所有的key中随时删除
5>volatile-ttl:删除即将过期的,ttl(tiime to live)剩余生存时间
6>noeviction:永不过期,返回错误
参数的设置可以采用命令方式,也可以采用配置文件方式(所有的配置都支持这两种),配置命令如
config set maxmemory-policy volatile-lru
还可以设置随机抽样数,如
config set maxmemory-samples 5 就是说每次进行淘汰的时候,会随机抽取5个key从里面淘汰最不经常使用的。
redis压缩列表(ziplist)。压缩列表是列表键和哈希键的底层实现之一。当一个列表键只包含少量表项,并且每个列表要么是小整数,要么是较短的字符串,那么redis就会使用压缩列表来作为列表键的底层实现。当一个哈席键只包含少量key-value对,且每个key和value要么是小整数,要么是较短字符串,那么redis就会使用ziplist作为哈希键的底层实现。

我在介绍自己的epiphany框架的时候(在上面流程图里也有体现),如果一个key里的结构是个hash,在小于1k的hash键的情况下我直接用hash,而大于1k,考虑到写入性能差,我就直接将hash打包压缩成一个大value来存储。考虑使用这两种策略的其中一个原因是小散列表使用的内存非常小,节省存储空间。
跑题时间:
这幅画的名字叫《洗尽铅华》

标签:mysql ima 数据集 rand 版本 分配 内部使用 set conf
原文地址:http://www.cnblogs.com/Leo_wl/p/7426642.html