标签:cores cal 工具 des als tom 了解 比例 聚合
scikit-learn提供了一些标准数据集(datasets),比如用于分类学习的iris 和 digits 数据集,还有用于归约的boston house prices 数据集。
其使用方式非常简单如下所示:
|
$ python >>> from sklearn import datasets >>> iris = datasets.load_iris() >>> digits = datasets.load_digits() |
每个datasets对象(如iris或digits)都是一个类Dictionary,即是一个Map容器。同时datasets对象都有两个重要属性:
data属性是一个二维的矩阵,每行表示一个测试的样本(samples),每列表示样本的特征值(feature),如下所示:
|
from sklearn import datasets digits = datasets.load_digits() print(digits.data) |
|
输出: [[ 0. 0. 5. …, 0. 0. 0.] [ 0. 0. 0. …, 10. 0. 0.] [ 0. 0. 0. …, 16. 9. 0.] …, [ 0. 0. 1. …, 6. 0. 0.] [ 0. 0. 2. …, 12. 0. 0.] [ 0. 0. 10. …, 12. 1. 0.]] |
target是测试样本的真实标签,如下所示:
|
from sklearn import datasets digits = datasets.load_digits() print(digits.target) |
|
输出: [0 1 2 …, 8 9 8] |
iris 和 digits 数据集还有一些不同的属性,可以在datasets.load_XXX()函数源码中查看详细内容,如datasets.load_digits()函数内容如下:
|
Def load_digits(n_class=10, return_X_y=False):
…
return Bunch(data=flat_data, target=target, target_names=np.arange(10), images=images, DESCR=descr) |
Estimator是scikit-learn实现的主要API,可以将其理解为模型(model),即是机器学习中的学习器(learner),通过estimator可以进行分类、回归和聚合等操作。
对于监督学习的任务可以分如下步骤进行:
c) 泛化性能度量:测量模型的泛化能力,即对其评分;
d) 模型进行预测:进行实际预测或应用。
scikit-learn已经实现了非常多机器学习模型,用户只需根据接口参数要求直接创建即可。
如下所示获取一个支持向量机模型:
|
from sklearn import svm clf = svm.SVC(gamma=0.001, C=100.) |
每个scikit-learn模型都提供一个fit(X, y)方法,用于训练模型,其中X参数是一个二维的矩阵,是指模型训练的数据集;y是一个一维数组,是指训练数据集的相应标签。如下所示的使用方式:
|
clf.fit(digits.data[:-1], digits.target[:-1]) |
每个scikit-learn模型都提供一个score()方法用于估计模型的性能,在训练完模型后,即可使用该方法进行估计性能。
如下所示的程序:
|
from __future__ import print_function from sklearn.datasets import load_iris from sklearn.cross_validation import train_test_split from sklearn.neighbors import KNeighborsClassifier
iris = load_iris() X = iris.data y = iris.target
#0.获取数据集,并将数据集分为训练数据和测试数据 X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=4)
#1.获取模型 knn = KNeighborsClassifier(n_neighbors=5) #2.训练模型 knn.fit(X_train, y_train) #3.度量性能 print(knn.score(X_test, y_test)) |
|
输出: 0.973684210526 |
在训练完模型后,即可进行数据预测。每个scikit-learn模型都提供一个predict(X)方法,其功能是预测指定的数据。其中X是一个二维矩阵,即希望被预测的数据;同时该方法会返回一个一维的数组,每个元素对应矩阵X中每行的预测标签。
如下所示的完整程序:
|
from sklearn import datasets from sklearn import svm
digits = datasets.load_digits() clf = svm.SVC(gamma=0.001, C=100.)
clf.fit(digits.data[:-1], digits.target[:-1]) y=clf.predict(digits.data[-1:])
print(y) |
|
[8] |
对于训练数据集和预测数据常需要先进行预处理,使得训练的模型泛化性能更高。其中本小结只简单介绍"特征缩放",更多功能可以参考[1]的预处理章节。
如下使用了preprocessing模块的scale()方法进行数据缩放:
|
from sklearn import preprocessing
a = np.array([[10, 2.7, 3.6], [-100, 5, -2], [120, 20, 40]], dtype=np.float64)
print(a) #比较在预处理前的数据 print(preprocessing.scale(a)) #比较在预处理后的数据
|
|
输出: [[ 10. 2.7 3.6] [-100. 5. -2. ] [ 120. 20. 40. ]] [[ 0. -0.85170713 -0.55138018] [-1.22474487 -0.55187146 -0.852133 ] [ 1.22474487 1.40357859 1.40351318]] |
scikit-learn的交叉验证功能是通过model_selection模块实现,
通常在(监督)学习实验中,通常会将一部分数据独立出来作为测试集合。scikit-learn的model_selection模块有个辅助函数 train_test_split 可以快速地将数据划分为训练集合与测试结合。
如下将采样到一个训练集合同时保留 40% 的数据用于测试(评估):
|
from sklearn import datasets from sklearn.model_selection import train_test_split
#0.获取数据集 iris = datasets.load_iris() print(iris.data.shape, iris.target.shape)
#1.进行原始数据集的分离操作 X_train, X_test, y_train, y_test = train_test_split(iris.data, iris.target, random_state=4)
#2.分离后的数据集 print(X_train.shape, y_train.shape) print(X_test.shape, y_test.shape) |
|
输出: (150, 4) (150,) (112, 4) (112,) (38, 4) (38,) |
PS:
在model_selection中还有其它多种函数能用于数据集分离操作,可以具体参考[1]的Model selection模块。
Estimator对象已提供一个score函数能够度量模型的性能,但是该方法需要先训练模型,然后测量模型的性能。即将数据集分为两部分,一部分先训练模型;另一部分用于度量模型。
model_selection提供一种cross-validation(交叉验证)的方式来度量模型的性能,这种方式不需要用户手动分离数据集和训练模型。用户直接测量模型的泛化性能,该函数为:cross_val_score。
|
def cross_val_score(estimator, X, y=None, groups=None, scoring=None, cv=None, n_jobs=1, verbose=0, fit_params=None, pre_dispatch=‘2*n_jobs‘): |
下面的例子演示了如何评估一个线性支持向量机在 iris 数据集上的精度,通过划分数据,可以连续5次评分:
|
from sklearn import datasets from sklearn import svm from sklearn.model_selection import cross_val_score
iris = datasets.load_iris() clf = svm.SVC(kernel=‘linear‘, C=1) scores = cross_val_score(clf, iris.data, iris.target, cv=5)
print(scores) |
|
输出: [ 0.96666667 1. 0.96666667 0.96666667 1. ] |
通过cross_val_score方法获取的是一个向量,用户可以对向量取平均分数和具有 95% 置信区间,如下所示的分数估计:
|
print("Accuracy: %0.2f (+/- %0.2f)" % (scores.mean(), scores.std() * 2)) |
|
输出: Accuracy: 0.98 (+/- 0.03) |
一个模型(Estimator)的泛化能力与它的训练数据集有很直接的关系,若训练数据集样本数少了则会出现"欠拟合"的模型,如图 11所示的第一个图;若训练数据集样本数多了则会出现"过拟合"的模型,如图 11所示的第三个图;如图 11所示的第二个图是数据集刚刚好的情况。
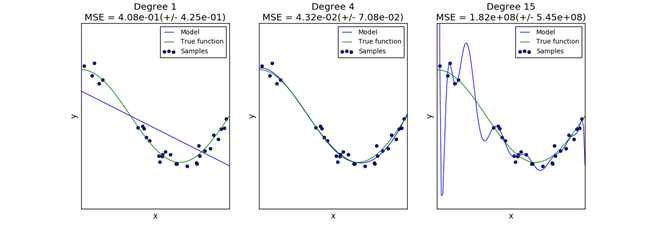
图 11
对于一维的特征向量可以图形化来描述过拟合和欠拟合的情况,若特征向量是多维的,则很难用图形化来评估数据集数量对模型的影响。
model_selection提供一个工具函数learning_curve来帮助用户了解数据集的样本数对模型泛化性能的影响,通过这个函数能够显示不同数量训练样本下模型的训练和验证分数。这里的训练分数是指进行训练模型的数据集来评估模型性能的分数;而验证分数是指在通过测试数据集对评估模型性能的分数。
如图 11所示是一个SVM模型在不同数据集样本数下,训练分数和交叉验证分数的学习曲线,通过两者分数的差异可以评估模型的拟合程度:
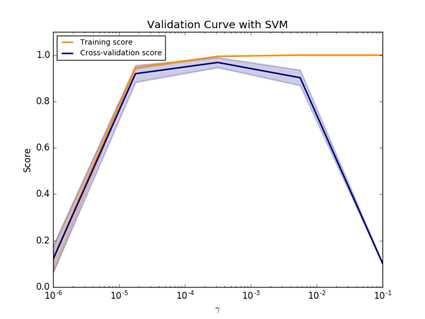
图 12
我们使用learning_curve函数的目标是获取使得Training分数和Cross-validation分数一样高的数据样本数。其中learning_curve函数声明头如下所示:
|
def learning_curve(estimator, X, y, groups=None, train_sizes=np.linspace(0.1, 1.0, 5), cv=None, scoring=None, exploit_incremental_learning=False, n_jobs=1, pre_dispatch="all", verbose=0): |
如下的使用示例:
|
from sklearn.model_selection import learning_curve from sklearn.svm import SVC from sklearn.datasets import load_iris
iris = load_iris() X = iris.data y = iris.target
train_sizes, train_scores, valid_scores = learning_curve(SVC(kernel=‘linear‘), X, y, train_sizes=[0.40, 0.80, 1], cv=5)
print(train_sizes) print(train_scores) print(valid_scores) |
|
输出: [ 48 96 120] [[ 1. 1. 1. 1. 1. ] [ 0.98958333 0.97916667 0.97916667 1. 0.97916667] [ 0.975 0.975 0.99166667 0.98333333 0.98333333]] [[ 0.66666667 0.66666667 0.66666667 0.66666667 0.66666667] [ 0.96666667 1. 0.93333333 0.9 1. ] [ 0.96666667 1. 0.96666667 0.96666667 1. ]] |
PS
scikit-learn的model_selection模块还提供另一个评估函数:Validation curve,该函数功能与learning_curve功能类似,不过Validation_curve函数支持调节不同模型的参数来验证性能。
scikit-learn提供模型持久化功能,即能够将训练好的模型保存起来,后续可以直接获取模型不需要重复训练,从而节约预测的时间。
Python提供了一个模块 pickle,能够实现模型持久化功能。其使用方式如下所示:
|
from sklearn import svm from sklearn import datasets
clf = svm.SVC() iris = datasets.load_iris() X, y = iris.data, iris.target clf.fit(X, y)
import pickle s = pickle.dumps(clf) clf2 = pickle.loads(s) y_predit = clf2.predict(X[0:1])
print(y_predit) #预测标签 print(y[0]) #真实标签 |
|
输出: [0] 0 |
在特殊情况下,可以使用joblib代替pickle模块,特别是在大数据集下效率更高,但只有pickle将模型保存到磁盘中,而不是保存为字符串形式,如下所示的使用:
|
from sklearn.externals import joblib joblib.dump(clf, ‘filename.pkl‘) clf = joblib.load(‘filename.pkl‘) |
[2].scikit-learn中文版网站;
标签:cores cal 工具 des als tom 了解 比例 聚合
原文地址:http://www.cnblogs.com/hlwfirst/p/7429359.html