标签:原理 上进 性能 方式 https ase 网页 没有 分割
本文不没有任何知识可讲,只是帖上自己测试的结果。
想看底层原理的可以直接关闭。
不过对于急着要选方案的人,倒提供一些帮助。
先说一些无关紧要的废话:
====================================================================================================================================================
先说说为什么会有这篇文章。
我在做练习的时候,参考一些老代码,发现了CRITICAL_SECTION这个类型。以前没有用过。查了一下,三个要点:windows使用;互斥效果;比mutex快。
后来又翻了些网页查看两者的一些简介。很统一的结果,CRITICAL_SECTION比mutex快,而且Linux上没有类似的接口(注:可能是我搜索的方式不对,加上本人对Linux研究不多,所以没有找到)。
对于刚打算使用c++11制作全新技术接口版本的服务器的我来说,很遗憾啊,Linux没有。难道我只能用这种慢速的锁?而我又不想写太多差异化的代码,能用标准库最好,等到真的某个模块成为新能瓶颈的时候再针对某个模块在Linux上做差异处理。
所以我还是想使用标准库来完成这个事情。
于是,我搜索“CRITICAL_SECTION c++11”。
两篇很重要的文章出现在了搜索结果里,是因为这两篇文章而产生了本文。
https://stackoverflow.com/questions/23519630/are-there-c11-critical-sections
https://stackoverflow.com/questions/9997473/stdmutex-performance-compared-to-win32-critical-section
====================================================================================================================================================
第一篇文章的精要在:
虽然Linux上没有临界区这样的接口,而mutex又是需要陷入内核去处理的东西。但是呢这些都是规定,仅仅是为了兼容POSIX协议做的。而mutex慢主要是POSIX需要跨进程。但是呢,在不同的系统和版本上面,就可以有私人定制,就如同windows上的CRITICAL_SECTION。一旦我不再兼容POSIX,就可以做一些自己的花活。而同时在兼容POSIX的平台上,继续遵循POSIX的规定。
以上精要,你可以在第一个连接的第一个回复里面的追问里面得到。
这给我提供了一个很重要的信息:c++11是没有临界区这样的用法。而且mutex的跨进程也不是所有的系统和版本都需要的,仅仅是某些版本需要。在不需要的版本上std::mutex可能是有特殊的用法和优化可以媲美临界区。
总之,mutex和mutex不一样
有了这个想法,我决定自己写代码试试。
然而不幸的是,当我准备写的时候,我想,这种问题应该也会有其他人这样想吧,说不定能搜到呢?
在搜索结果里,我就看到了第二篇。
第二篇文章的精要在:
std::mutex慢。CRITICAL_SECTION更快。但是如果采用合理的方式来分割任务,两者可以达到几乎相同的效果。
第二篇文章是含有两个人的测试代码的。第一个人的测试代码是直接比对两种用法的时间差异。但是很遗憾,他使用的是vs2012。这个版本对c++11的支持并不算完美。第二个人的测试代码是将任务做了分割,分给不同的cpu,又延长了执行间隔,减少访问冲突。使用的是vs2013,这一传说中对c++11支持很完善的版本
看到这里,我有些冷,就不太想写测试代码了。原因是开发工具,人家已经更新到了一个合理的版本,其次在结构上进行了划分,而划分之后才打个平手。
似乎所有的结果都是唯一的。
但是!中间好几年了。万一有变化呢?即使没有,自己测试一下总归实在一些。所以还是自己做了个测试。结果很意外。
先说思路:
在同一进程中,开启4个线程,2个用std::mutext去抢,两个用CRITICAL_SECTION去抢;
两组方式各自使用自己组的变量;
只记录计算次数,不做结果正确判断;
以下是测试代码

1 #include <iostream> 2 #include <mutex> 3 #include <thread> 4 #include <Windows.h> 5 #include <chrono> 6 7 using namespace std; 8 9 mutex g_Mutex_Lock, g_Mutex_finish; 10 CRITICAL_SECTION g_CS_Lock, g_CS_finish; 11 uint64_t g_Mutext_Num = -1; 12 uint64_t g_CS_Num = -1; 13 const int32_t g_Count = 10000000; 14 once_flag g_Mutex_flag, g_CS_flag; 15 chrono::time_point<chrono::system_clock> g_Mutex_StartTime, g_CS_StartTime; 16 int32_t g_Mutex_Complete = 0; 17 int32_t g_CS_Complete = 0; 18 19 uint64_t Calculate(uint64_t num, int index) 20 { 21 if (index % 2) 22 { 23 return (num / 0x5555) * 0xaaaa; 24 } 25 else 26 { 27 return (num / 0x6666) * 0x9999; 28 } 29 } 30 31 void mutexTimeStart() 32 { 33 g_Mutex_StartTime = chrono::system_clock::now(); 34 } 35 36 void mutexCalculate() 37 { 38 call_once(g_Mutex_flag, mutexTimeStart); 39 40 for (int i = 0; i < g_Count; ++i) 41 { 42 g_Mutex_Lock.lock(); 43 g_Mutext_Num = Calculate(g_Mutext_Num, i); 44 g_Mutex_Lock.unlock(); 45 } 46 g_Mutex_finish.lock(); 47 ++g_Mutex_Complete; 48 if (2 == g_Mutex_Complete) 49 { 50 chrono::duration<double> elapsed_seconds = chrono::system_clock::now() - g_Mutex_StartTime; 51 printf("mutex finished use: %f\n", elapsed_seconds.count()); 52 } 53 g_Mutex_finish.unlock(); 54 } 55 56 void csTimeStart() 57 { 58 g_CS_StartTime = chrono::system_clock::now(); 59 } 60 61 void csCalculate() 62 { 63 call_once(g_CS_flag, csTimeStart); 64 for (int i = 0; i < g_Count; ++i) 65 { 66 EnterCriticalSection(&g_CS_Lock); 67 g_CS_Num = Calculate(g_CS_Num, i); 68 LeaveCriticalSection(&g_CS_Lock); 69 } 70 EnterCriticalSection(&g_CS_finish); 71 ++g_CS_Complete; 72 if (2 == g_CS_Complete) 73 { 74 chrono::duration<double> elapsed_seconds = chrono::system_clock::now() - g_CS_StartTime; 75 printf("cs finished use: %f\n", elapsed_seconds.count()); 76 } 77 LeaveCriticalSection(&g_CS_finish); 78 } 79 80 81 void main() 82 { 83 InitializeCriticalSection(&g_CS_Lock); 84 InitializeCriticalSection(&g_CS_finish); 85 86 thread t3(csCalculate); 87 t3.detach(); 88 thread t4(csCalculate); 89 t4.detach(); 90 91 thread t1(mutexCalculate); 92 t1.detach(); 93 thread t2(mutexCalculate); 94 t2.detach(); 95 96 int tStop; 97 cin >> tStop; 98 }
测试环境:win10企业版(已经更新到最新)+vs2015企业版+i7-6700HQ(2.6G×8)
64位release版结果:
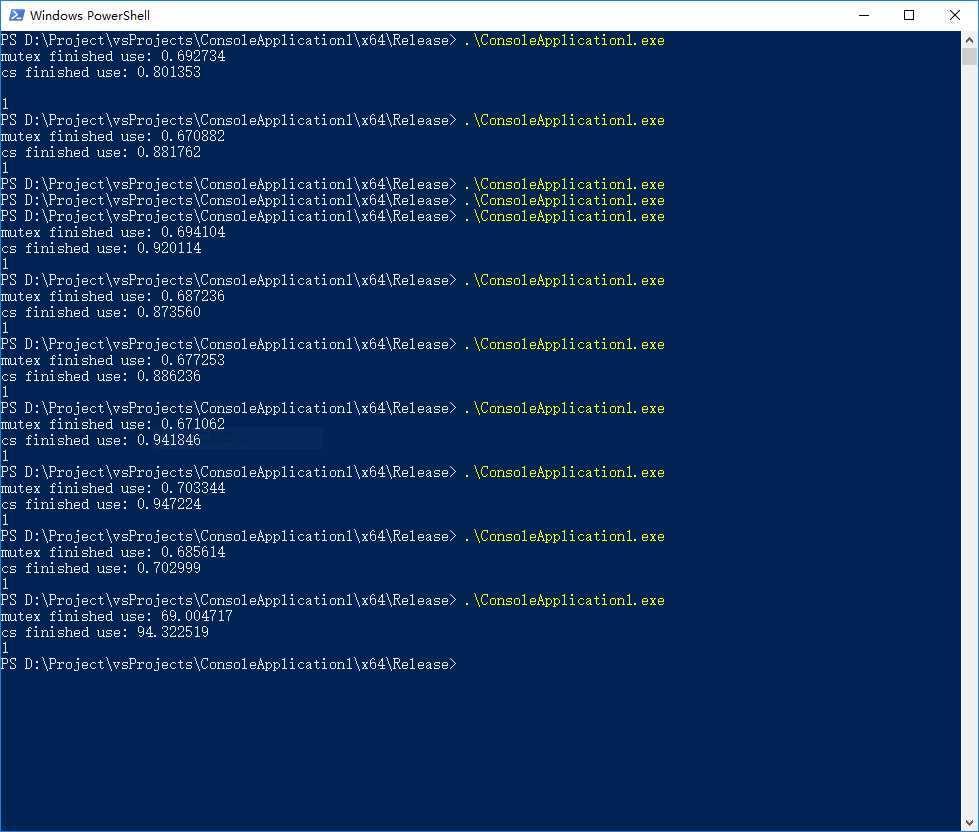
图中除最后一个外,都是循环1千万次的结果。最后一个是10亿次的结果。
再上一个64位debug版的1亿次的截图(原谅我没有等带10亿次的结果,你们不知道,我测试1千万的结果是n秒。然后头绕一热直接跳了两级,一运行,发现没出结果,然后一算,就傻了,关掉减个0)。
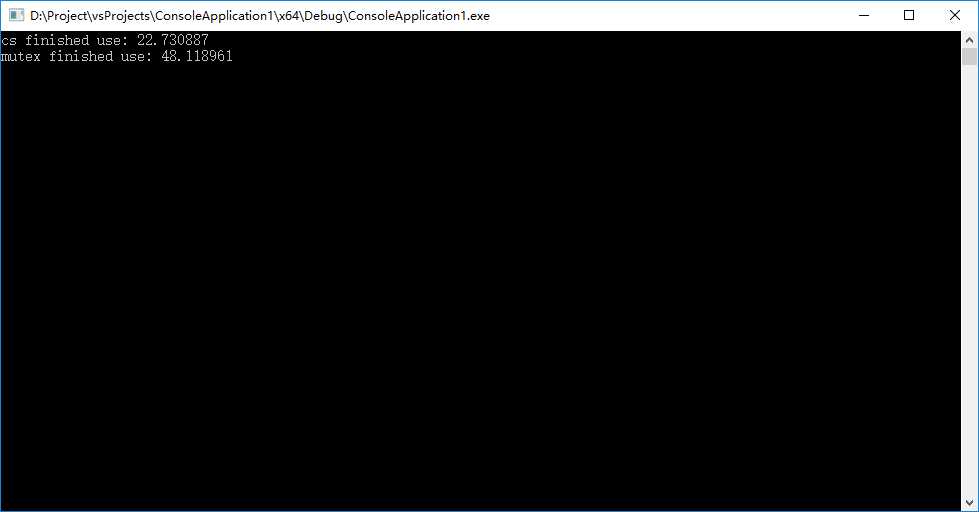
无论前面有多少经历,无论多少推测。结果胜过一切,我可以继续安心的、开心的使用std继续进行我的练习了。
本次测试结果:
1、性能不是瓶颈,不要考虑太多。优化都是在原有的基础上逐步修改改出来的成果,不是动手的时候,脑子就有现成的方案。何况性能并没有走到瓶颈。
2、没有什么比电脑跑出来的结果更靠谱。毕竟电脑才是所有理论知识最终产物的执行者。
3、随时间的推移,技术在改良。使用通用的接口,每次技术更替,你也在享受免费的红利。
最后,如果有朋友发现我的代码中存在影响测试结果的错误,请留言指出。我不想自己错了,还误导别人。
标签:原理 上进 性能 方式 https ase 网页 没有 分割
原文地址:http://www.cnblogs.com/saucerman/p/7438250.html
