标签:style blog http color 使用 strong for 文件 数据
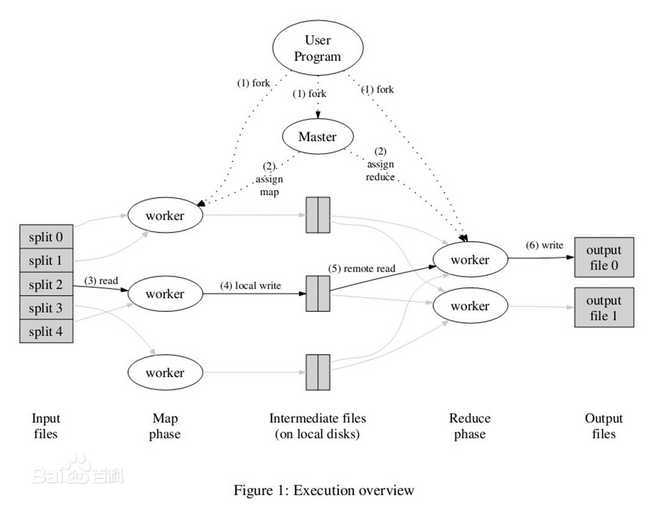
一切都是从最上方的user program开始的,user program链接了MapReduce库,实现了最基本的Map函数和Reduce函数。
函数说明 pid_t fork( void)
一个现有进程可以调用fork函数创建一个新进程。由fork创建的新进程被称为子进程。fork函数被调用一次但返回两次。两次返回的唯一区别是子进程中返回0值而父进程中返回子进程ID。子进程是父进程的副本,它将获得父进程数据空间、堆、栈等资源的副本。注意,子进程持有的是上述存储空间的“副本”,这意味着父子进程间不共享这些存储空间。
标签:style blog http color 使用 strong for 文件 数据
原文地址:http://www.cnblogs.com/kaituorensheng/p/3958862.html