标签:des style blog http io 使用 ar 2014 div
题记:最近零碎的时间都在学习Andrew Ng的machine learning,因此就有了这些笔记。
梯度下降是线性回归的一种(Linear Regression),首先给出一个关于房屋的经典例子,
| 面积(feet2) | 房间个数 | 价格(1000$) |
| 2104 | 3 | 400 |
| 1600 | 3 | 330 |
| 2400 | 3 | 369 |
| 1416 | 2 | 232 |
| 3000 | 4 | 540 |
| ... | ... | .. |
上表中面积和房间个数是输入参数,价格是所要输出的解。面积和房间个数分别表示一个特征,用X表示。价格用Y表示。表格的一行表示一个样本。现在要做的是根据这些样本来预测其他面积和房间个数对应的价格。可以用以下图来表示,即给定一个训练集合,学习函数h,使得h(x)能符合结果Y。
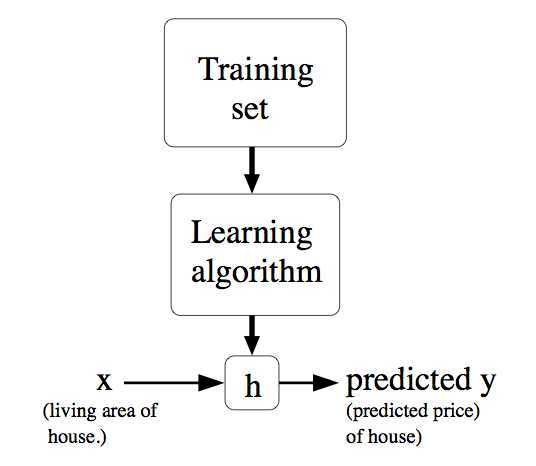
可以用以下式子表示一个样本:
![]()
θ表示X映射成Y的权重,x表示一次特征。假设x0=1,上式就可以写成:
![]()
分别使用x(j),y(j)表示第J个样本。我们计算的目的是为了让计算的值无限接近真实值y,即代价函数可以采用LMS算法
![]()
![]()
要获取J(θ)最小,即对J(θ)进行求导且为零:
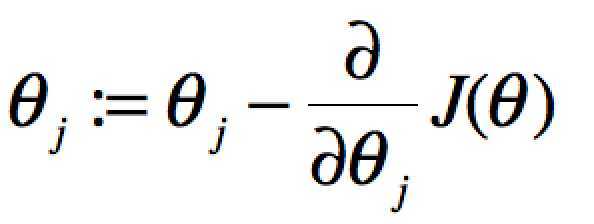
当单个特征值时,上式中j表示系数(权重)的编号,右边的值赋值给左边θj从而完成一次迭代。
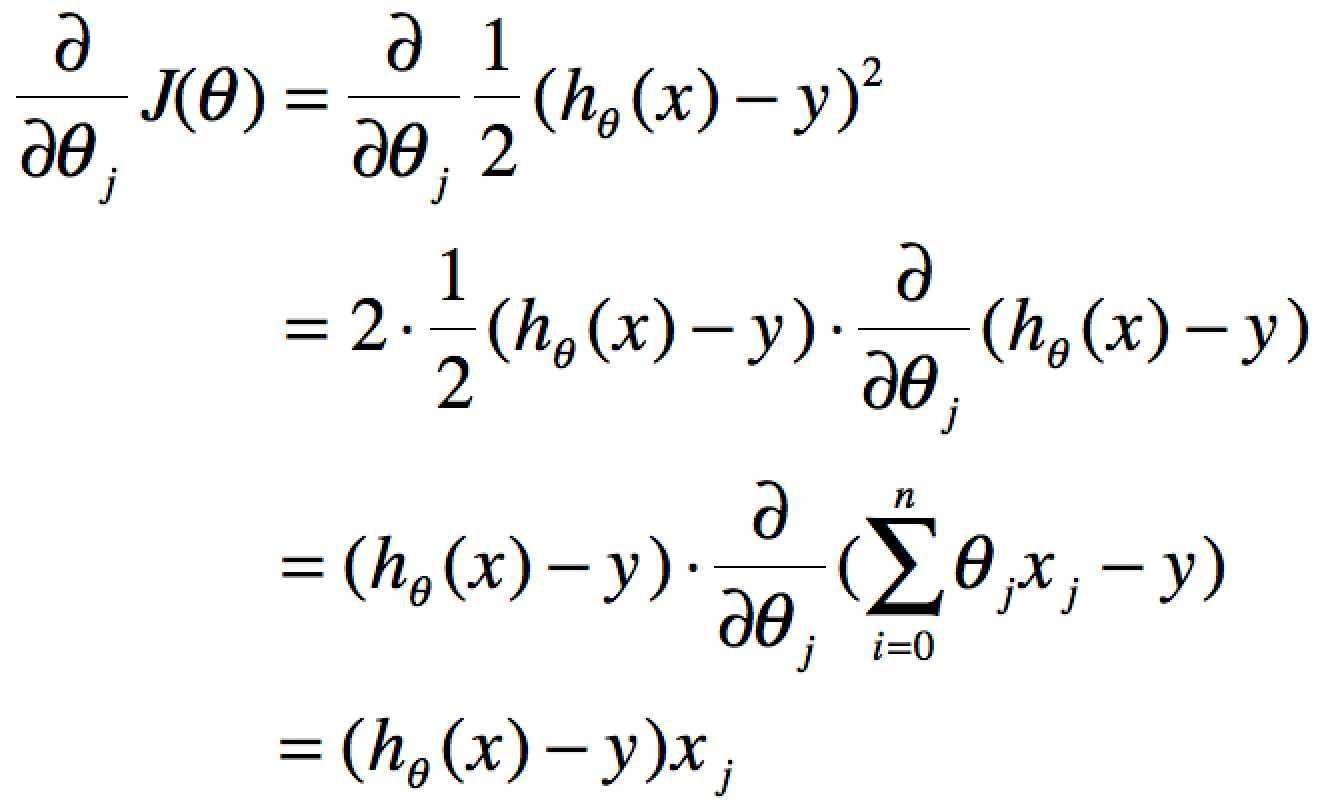
单个特征的迭代如下:
![]()
多个特征的迭代如下:
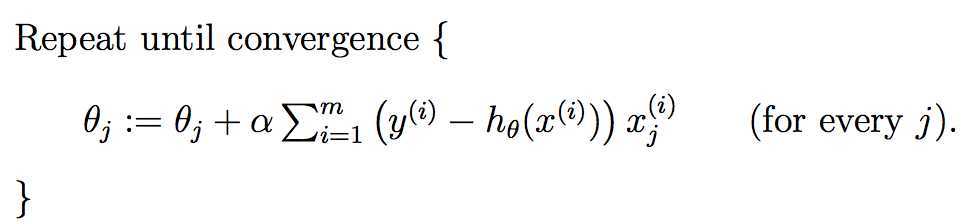
上式就是批梯度下降算法(batch gradient descent),当上式收敛时则退出迭代,何为收敛,即前后两次迭代的值不再发生变化了。一般情况下,会设置一个具体的参数,当前后两次迭代差值小于该参数时候结束迭代。注意以下几点:
机器学习(1)之梯度下降(gradient descent)
标签:des style blog http io 使用 ar 2014 div
原文地址:http://www.cnblogs.com/rcfeng/p/3958926.html