标签:一起 元字符 部分 技术分享 涵盖 emacs grep border pre
作为程序员,相信大家经常会遇到很多关于文本查找替换的问题,比如下面2个例子。
hello
world
This
is
my first
chapter
2. 下面是一系列需要从数据库删除的表,它们之间用 , 隔开,需要输出相应的删除语句。
Customer, Order, Type, Company, Address, Ship, Color, Product, Message, WareHouse, Bin, BindleOp, BITable, BIVar, Build, BuildVersion, CCToken, Color, ColorLink, ColorType, ColorPrefix
客观来说,这2个例子都不是太困难,很多童鞋会说,这还不简单,不就是手动删除,手动创造一些SQL语句吗?对,这么说没有问题,但是如果这些例子包含上百行,上千行,这种手动的方式还能那么从容吗?就算我们有大量的时间来完成这种工作,采取一种更有效率的方式来完成它不是更能节约时间吗?如果你对这个问题的答案是肯定的,那么请接着往下面看。
首先揭晓答案,要想快速的处理这两个例子,我们需要一种特殊的,强大的,精确的基于文本的搜索替换语法,这语法的名字叫正则表达式。在本系列文章中,我们从零开始,一点一点学习如何使用这个强大的工具来加速我们的文本处理。
本章是第一章,我们将会学习正则表达式的基本语法。
正则表达式分为很多流派,但是基本都出自于PERL而且在很大程度上是相容的,所以我们在学习初期不用太在意流派之分。正则表达式使用一种叫模式的串来匹配目标串,模式和目标串都是由数字,字母和一些特殊字符等组成的字符串,并没有什么不同,比如最简单的,我们可以说,模式’abc’匹配目标串’abc’。乍一看,似乎没什么特别之处——确实如此,正则表达式的强大之处不在于此,在于其包含的元字符。
|
元字符 |
解释 |
例子 |
|
* |
匹配前一个字符或者表达式0次或多次 |
‘ba*’ 可以匹配’b’, ‘ba’ 和 ‘baa’ |
|
+ |
匹配前一个字符或者表达式至少1次 |
‘ba+’可以匹配’ba’, ‘baa’ 但是不能匹配’b’ |
|
? |
匹配前一个字符或者表达式至多1次 |
‘ba?’可以匹配’ba’,’b’ 但是不能匹配’baa’ |
|
. |
匹配除换行符之外的任意单一字符 |
‘.’可以匹配’a’, ‘b’ 和 ‘c’ |
|
[] |
标记括号表达式的开始和结束 |
[1-4]可以匹配’1’,’2’,’3’,’4’ ,等同于[1234].[a-b]可以匹配’a’和’b’. 同时我们也可以使用[a-zA-Z]的模式来匹配所有的字符 |
|
{} |
标记量词表达式的开始和结束,规定匹配前一个字符或者表达式的次数范围 |
‘a{2,3}’ 可以匹配’aa’和’aaa’,即,匹配字符’a’2次到3次 |
|
() |
标记子表达式的开始和结束,子表达式可以被捕获 |
‘a(.)’可以匹配’a1’,’a2’和’an’ |
|
| |
选择表达式,可以选择匹配其中的某一项 |
‘a(b|c)d’可以匹配’abd’和’acd’ |
|
^ |
锚点,匹配字符串开始位置 |
‘^abc’ 匹配以’abc’开头的串 |
|
当它出现在括号表达式的第一个位置,表示取所有不在括号表达式里面的值 |
‘[^abc]’ 不能匹配 ‘a’, ‘b’ 和 ‘c’ |
|
|
$ |
锚点,匹配字符串结束位置 |
‘abc$’匹配以’abc’结尾的串 |
|
\ |
转义元字符,和紧跟在它后面的字符组合使用,一般来说,转义元字符的解读规则是, 下接字母表示特殊含义 下接数字表示捕获 下接元字符表示退出元字符的本来含义 |
‘\d’表示数字匹配 ‘\1’表示捕获的第一个子表达式 ‘\(‘表示想要匹配一个左括号而不把这个左括号解释为子表达式的开始 |
|
\d |
匹配数字,等同于[0-9] |
‘\d+’ 可以匹配’1’, ‘12’,至少匹配一个数字 |
|
\D |
匹配非数字,等同于[^0-9] |
|
|
\w |
匹配数字字母和下划线,等同于[A-Za-z0-9_] |
‘\w+’ 可以匹配’hello…’中的’hello’ |
|
\W |
匹配非数字字母和下划线,等同于[^A-Za-z0-9_] |
‘\W+’可以匹配’hello…’中的’…’ |
|
\b |
匹配单词边界 |
‘o\b’匹配’hello’ 但是不能匹配’yellow’ |
|
\B |
匹配非单词边界 |
‘o\B’匹配’yellow’ 但是不能匹配’hello’ |
|
\s |
匹配所有空白字符,包括回车,制表符,空格等 |
|
|
\S |
匹配所有非空白字符 |
|
|
\t |
匹配制表符 |
|
|
\r |
匹配回车 |
|
|
\n |
匹配新行 |
|
怎么样,有没有感觉被吓到或者好复杂的感觉?这里还不是所有的元字符哦,有一些元字符只有在我们对正则表达式有更高要求的时候,才会使用到,所以这里就先不介绍了,毕竟第一章也不能把大家给吓着了,对吧~
请放心,这里已经涵盖了大部分我们在工作中需要的元字符,多加练习就会很快熟练起来。在各种主流操作系统下,都有很多文字编辑软件支持正则表达式查找替换,像WINDOWS下面的NOTEPAD++, 基于LINUX的GREP,VIM,EMACS等。
笔者所使用的是WINDOWS下面的NOTEPAD++,在NOTEPAD++下面开启正则表达式的查找和替换方法如下:
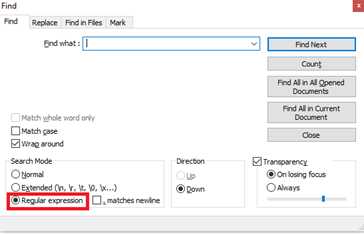
之后就可以使用强大的正则表达式了,拿例1来说,我们直接使用模式’^$\r\n’匹配空行,并进行替换,就可以达到我们的目的。在这个模式当中,锚点^$一起使用,匹配没有任何字符的行,\r\n匹配回车换行符,删除之后,就达到了去掉空行的目的。
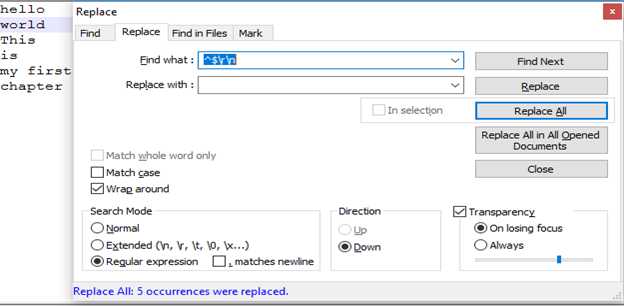
至于例2,大家可以自己试着先做一下,我们下一章揭晓正确答案。希望大家自己多加练习并喜欢上这个强大的工具。比如,大家可以试着做一些简单的练习,像匹配11位电话号码,匹配合法的电子邮箱地址,匹配一些特定开头或者结尾的字符串,匹配检查一些常见的拼写错误,多多练习就能体会到正则表达式的优美和编写它的乐趣。我们下一章见。
标签:一起 元字符 部分 技术分享 涵盖 emacs grep border pre
原文地址:http://www.cnblogs.com/deatharthas/p/7451326.html