标签:oop www lov java 介绍 相对 padding gets java程序
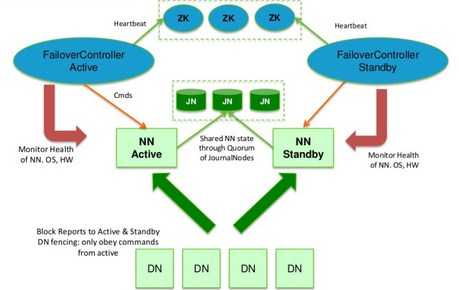
三:QJM HDFS高可用
原文地址:http://www.cnblogs.com/skyrim/p/7455548.html