标签:put pat exce org ril mit get smi on()
此例子摘自hadoop基础教程。
其中sales.txt内容如下
客户编号 客户消费额度 消费时间
001 35.99 2012-03-15 002 12.29 2004-07-02 004 13.42 2005-12-20 003 499.99 2010-12-20 001 78.95 2012-04-02 002 21.99 2006-11-30 002 93.45 2008-09-10 001 9.99 2012-05-17
accounts.txt内容如下:
客户编号 姓名 注册时间
001 John AllenStandard 2012-03-15 002 Abigail SmithPremium 2004-07-13 003 April StevensStandard 2010-12-20 004 Nasser HafezPremium 2001-04-23
我们的目标是通过reduce端联结求出每个客户姓名 消费的次数 消费额
代码如下:
import java.io.*;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.*;
import org.apache.hadoop.mapreduce.lib.input.*;
import org.apache.hadoop.mapreduce.lib.output.*;
public class ReduceJoin {
//sales.txt的处理 客户ID 消费额度 消费时间
public static class SalesRecordMapper extends Mapper<Object, Text, Text, Text> {
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
String record = value.toString();
String[] parts = record.split("\t");
context.write(new Text(parts[0]), new Text("sales\t"+parts[1]));
}
}
//accounts.txt的处理 客户id 客户姓名 办卡时间
public static class AccountRecordMapper extends Mapper<Object, Text, Text, Text> {
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
String record = value.toString();
String[] parts = record.split("\t");
context.write(new Text(parts[0]), new Text("accounts\t"+parts[1]));
}
}
//reduce
public static class ReduceJoinReducer extends Reducer<Text, Text, Text, Text> {
public void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
String name = "";
double total = 0.0;
int count = 0;
for(Text t:values) {
String[] parts = t.toString().split("\t");
if(parts[0].equals("sales")) {
count++;
total += Float.parseFloat(parts[1]);
}else if(parts[0].equals("accounts")) {
name = parts[1];
}
}
String str = String.format("%d\t%f", count, total);
context.write(new Text(name), new Text(str));
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = new Job(conf, "Reduce端join");
job.setJarByClass(ReduceJoin.class);
job.setReducerClass(ReduceJoinReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
System.out.println(args[0]);
MultipleInputs.addInputPath(job, new Path(args[0]), TextInputFormat.class, SalesRecordMapper.class);
MultipleInputs.addInputPath(job, new Path(args[1]), TextInputFormat.class, AccountRecordMapper.class);
Path outputPath = new Path(args[2]);
FileOutputFormat.setOutputPath(job, outputPath);
outputPath.getFileSystem(conf).delete(outputPath);
System.exit(job.waitForCompletion(true)?0:1);
}
}
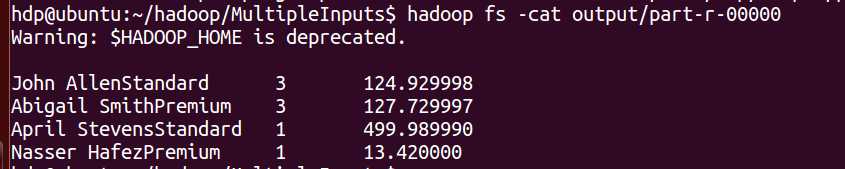
结果截图
标签:put pat exce org ril mit get smi on()
原文地址:http://www.cnblogs.com/xingxing1024/p/7461098.html