标签:概念 通过 生成器 没有 images -- 多次 last 定义
迭代器、生成器这些概念名称真是让人头大,其实它们的原理特别简单、深刻。
在讲迭代器和生成器之前,必须要讲的一个概念就是可迭代对象。
可迭代对象之前需要聊一下Python中的那些内置数据结构--列表、字典、集合、元组等,这些数据结构就像一个装有内置数据的容器。
这里可以这么想--把数据想象成苹果,把列表、字典、集合、元组等想像成装苹果的袋子、盒子、篮子、筐子等装苹果的容器。
我们都能从这些容器中一个一个把所有苹果拿出来,这就像是我们经常使用 for循环,从列表、字典、集合、元组等中依次取出所有数据的操作。
就像袋子、盒子、篮子、筐子这些物品不能决定我们如何从它们内部拿出苹果一样,列表、字典、集合、元组等也不能决定我们如何从它们内部拿出数据。
是使用它们的人定义了一些规矩--可以一次拿一个出来,直到东西被拿完为止。而这个规矩就是可迭代协议。
符合可迭代协议的就是可迭代对象。列表、字典、集合、元组等这些我们常见的数据结构都是可迭代对象。
但是还有一些也满足我们那个规矩的比如:我们可以依次从一个 打开的文件句柄中拿出一行内容,我们还可以依次从一个 socket拿出指定长度的数据。 这些都是可迭代对象,因为它们都符合我们之前定下的那个规矩。
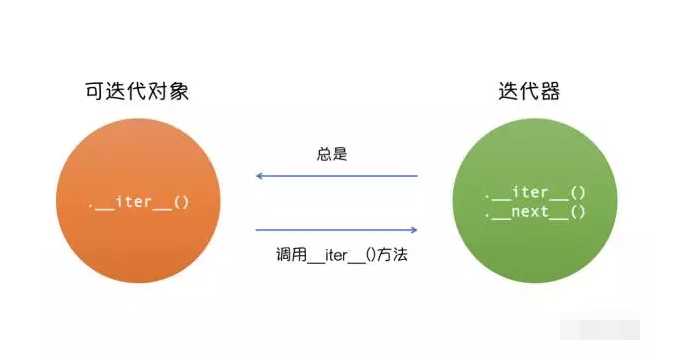
那如何证明它们都遵守了我们定下的规矩呢? 有一个条件,只要它们实现了 __iter__方法的话,我们就认为它们是符合我们的规矩的。 我们就可以认为它们是可迭代对象。
我们上面说完了可迭代对象和它必须有的一个方法( __iter__)。
那迭代器是什么呢?
我们只要执行可迭代对象的 __iter__方法就能得到一个 迭代器。 并且这个迭代器会有一个 __next__方法。
在这里我们就拿Python中的列表来举例:
>>> l = [1, 2, 3] # 这里是一个列表
>>> i = l.__iter__() # 调用__iter__方法
>>> i # 得到一个迭代器
<list_iterator object at 0x104db2a90>
那迭代器如何使用呢?
我们只要执行迭代器的 __next__方法就可以了。想象一下我们从一个袋子里一次拿出一个苹果来,直到最后我们在袋子底儿摸了一圈发现没有苹果了。
>>> i.__next__() # 拿一个数据
1
>>> i.__next__() # 拿一个数据
2
>>> i.__next__() # 拿一个数据
3
>>> i.__next__() # 在迭代器 i 中再也拿不出数据了
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
StopIteration
这里补充说明两点:
1.Python中内置的 iter和 next方法,其实就是执行的目标的 __iter__和 __next__方法。
>>> l = [1, 2, 3] # 这里是一个列表
>>> i = iter(l) # 使用Python内置的iter方法
>>> i # 得到一个迭代器
<list_iterator object at 0x104db2a58>
>>> next(i) # 使用Python内置的next方法拿一个数据
1
>>> next(i) # 拿一个数据
2
>>> next(i) # 拿一个数据
3
>>> next(i) # 在迭代器 i 中再也拿不出数据了
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
StopIteration
2.多次执行iter()或调用iter()得到的迭代器都是完全不同的对象。
你可以把它们想象成一次性塑料袋装的苹果,你执行一次iter()或调用一次iter(),你就得到一袋用一次性塑料袋装的苹果。(这个袋子是真的一次性,无法重复使用。)
>>> l = [1, 2, 3]
>>> i1 = iter(l) # 得到一个迭代器
>>> i2 = iter(l) # 得到一个迭代器
>>> i1 == i2 # 这两个迭代器是不同的迭代器
False
>>> id(i1) == id(i2)
False
>>> id(i1)
4376439496
>>> id(i2)
4376439608
3.迭代器是有状态的
当你调用迭代器的 __next__()取值的时候,并且已经被取出的值不会再次取出。
>>> l = [1, 2, 3]
>>> i1 = iter(l)
>>> i2 = iter(l)
>>> next(i1)
1
>>> next(i2)
1
>>> next(i1) # 能记住状态,从上一次结束的地方再开始
2
到现在为止,我们知道了可迭代对象和迭代器都是什么,并且也知道了它们的特点是什么。
那么生成器又是什么呢?
你现在回想一下,我们上面得到迭代器的过程是怎样的。 我们首先都是有一个可迭代对象,然后在这个可迭代对象基础上对它执行 __iter__()得到一个迭代器。 比如:我们先有一个列表 l=[1,2,3],然后在此基础上对它执行 __iter__()得到一个迭代器 i。在我们获取迭代器的时候,数据 l=[1,2,3]已经在内存中存在了。 也就是说,我们面前已经放着一袋真实的苹果,然后我们再把它变成一袋用一次性塑料袋装的苹果。
大概像是这样:
存在的数据 -得到-> 迭代器
>>> l = [1, 2, 3]
>>> i = iter(l)
>>> i
<list_iterator object at 0x104db2b70>
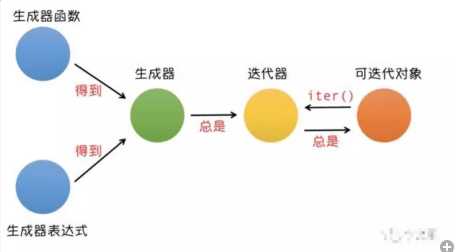
那我们如何针对现在还不存在的数据来获取对应的迭代器呢?也就是如何自己创造一个迭代器呢? 用生成器!生成器本质上就是一种特殊的迭代器。它也可以像迭代器那样依次取值。
未来的数据 -得到-> 生成器
比如:
我需要的数据是需要一系列运算得到的,比如10以内的奇数:
>>> l = [] # 先找一个存放数据的容器
>>> for i in range(11):
... if i%2 != 0: # 把符合条件的数据找到
... l.append(i) # 放进容器
...
>>> l # 得到结果
[1, 3, 5, 7, 9]
>>> i = iter(l) # 再执行iter()
>>> i # 得到迭代器
<list_iterator object at 0x104db2b70>
Python中有两种得到生成器的方式:
1.生成器表达式
在这之前我们先复习一下 列表推导式:
>>> l = [i for i in range(11) if i%2 != 0]
>>> l
[1, 3, 5, 7, 9]
生成器表达式就是把上面列表推导式的 []换成了 ():
>>> g = (i for i in range(11) if i%2 != 0)
>>> g
<generator object <genexpr> at 0x104da47d8>
2.yield关键字
简单的计算逻辑我们可以使用生成器表达式,复杂一点的我们只能通过带有 yield关键字的函数来处理了。 当一个函数内部通过yield来返回值的时候,这个函数返回的就是生成器。
>>> def func(): # 定义一个通过yield关键字返回值的函数
... for i in range(11):
... if i%2!=0:
... yield i # 返回符合条件的数据
...
>>> g = func() # 执行函数
>>> g # 得到一个生成器
<generator object func at 0x104da4830>
应用:
因为生成器的数据不是事先已经存在于内存中的,所以它会比把结果先放进内容,再转换成迭代器的方式更节省内存。 也就是说,当你今后再遇到类似下面的逻辑代码时:
def something():
result = []
for ... in ...:
result.append(i)
return result # 把结果全都获得并且放进内存
你都可以把它改写成如下生成器的方式:
def iter_something():
for ... in ...:
yield i # 找到一个符合要求的就"返回"(不同于return)
概念重要,实际应用更重要。编程本身就是一项技能,需要不断地刻意练习。
标签:概念 通过 生成器 没有 images -- 多次 last 定义
原文地址:http://www.cnblogs.com/huangxu/p/7472284.html