标签:过程 tip png 1.0 gray 无法 增加 时间片 服务器编程
1. 每个请求创建一个线程,使用阻塞式 I/O 操作
这是最简单的线程模型,1个线程处理1个连接的全部生命周期。该模型的优点在于:这个模型足够简单,它可以实现复杂的业务场景,同时,线程个数是可以远大于CPU个数的。然而,线程个数又不是可以无限增大的,为什么呢?因为线程什么时候执行是由操作系统内核调度算法决定的,调度算法并不会考虑某个线程可能只是为了一个连接服务的,时间片到了就执行一下,哪怕这个线程一执行就会不得不继续睡眠。这样来回的唤醒、睡眠线程在次数不多的情况下,是廉价的,但如果操作系统的线程总数很多时,它就是昂贵的(被放大了),因为这种技术性的调度损耗会影响到线程上执行的业务代码的时间。举个例子,当我们所追求的是并发处理数十万连接,当几千个线程出现时,系统的执行效率就已经无法满足高并发了。换言之,该模型的扩展性及其糟糕,根本无法有效满足高并发,海量连接的业务场景。
2. 使用线程池,同样使用阻塞式 I/O 操作
这是针对模型1的改进,但仍未从根本上解决问题
3. 使用非阻塞I/O + I/O复用
4. Leader/Follower 等高级模式
对高并发编程,目前只有一种模型,也是本质上唯一有效的玩法。网络连接上的消息处理,可以分为两个阶段:等待消息准备好、消息处理。当使用默认的阻塞套接字时(例如上面提到的1个线程捆绑处理1个连接),往往是把这两个阶段合而为一,这样操作套接字的代码所在的线程就得睡眠来等待消息准备好,这导致了高并发下线程会频繁的睡眠、唤醒,从而影响了CPU的使用效率。
高并发编程方法当然就是把两个阶段分开处理。即,等待消息准备好的代码段,与处理消息的代码段是分离的。当然,这也要求套接字必须是非阻塞的,否则,处理消息的代码段很容易导致条件不满足时,所在线程又进入了睡眠等待阶段。那么问题来了,等待消息准备好这个阶段怎么实现?它毕竟还是等待,这意味着线程还是要睡眠的!解决办法就是,线程主动查询,或者让1个线程为所有连接而等待!这就是IO多路复用了。多路复用就是处理等待消息准备好这件事的,但它可以同时处理多个连接!它也可能“等待”,所以它也会导致线程睡眠,然而这不要紧,因为它一对多、它可以监控所有连接。这样,当我们的线程被唤醒执行时,就一定是有一些连接准备好被我们的代码执行了。
作为一个高性能服务器程序通常需要考虑处理三类事件: I/O事件,定时事件及信号。本文将首先首先从整体上介绍两种高校的事件处理模型:Reactor和Proactor。
首先来回想一下普通函数调用的机制:程序调用某函数,函数执行,程序等待,函数将结果和控制权返回给程序,程序继续处理。Reactor释义“反应堆”,是一种事件驱动机制。和普通函数调用的不同之处在于:应用程序不是主动的调用某个API完成处理,而是恰恰相反,Reactor逆置了事件处理流程,应用程序需要提供相应的接口并注册到Reactor上,如果相应的时间发生,Reactor将主动调用应用程序注册的接口,这些接口又称为“回调函数”。
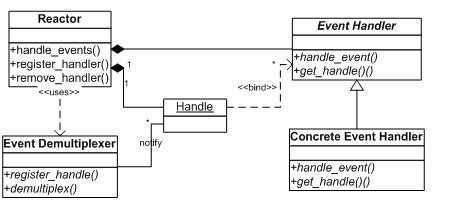
Reactor模式是处理并发I/O比较常见的一种模式,中心思想就是,将所有要处理的I/O事件注册到一个中心I/O多路复用器上,同时主线程阻塞在多路复用器上;一旦有I/O事件到来或是准备就绪(区别在于多路复用器是边沿触发还是水平触发),多路复用器返回并将相应I/O事件分发到对应的处理器中。
Reactor模型有三个重要的组件:
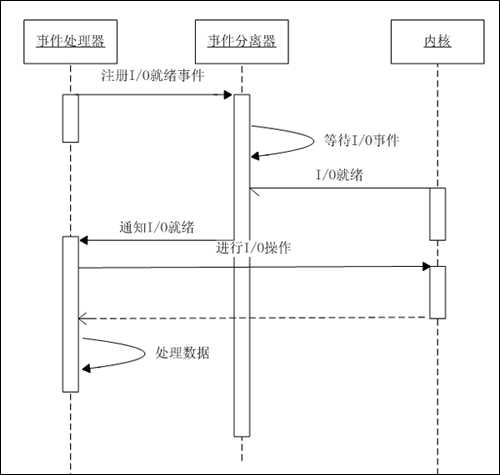
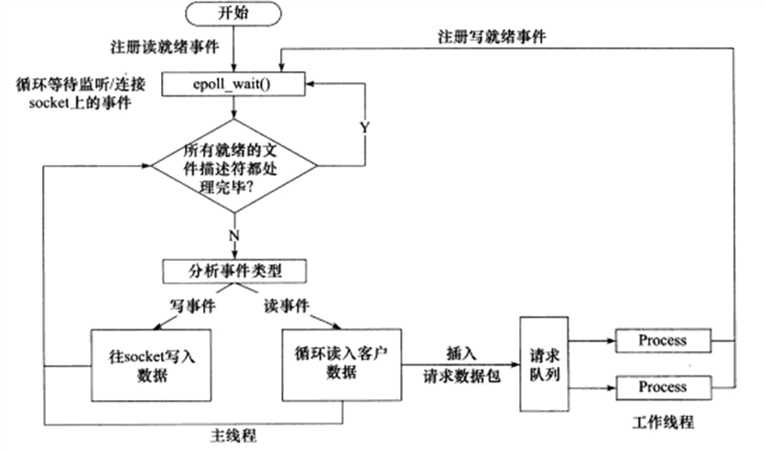
具体流程如下:
1. 注册读就绪事件和相应的事件处理器;
2. 事件分离器等待事件;
3. 事件到来,激活分离器,分离器调用事件对应的处理器;
4. 事件处理器完成实际的读操作,处理读到的数据,注册新的事件,然后返还控制权。
Reactor模式是编写高性能网络服务器的必备技术之一,它具有如下的优点:
Reactor模型开发效率上比起直接使用IO复用要高,它通常是单线程的,设计目标是希望单线程使用一颗CPU的全部资源,但也有附带优点,即每个事件处理中很多时候可以不考虑共享资源的互斥访问。可是缺点也是明显的,现在的硬件发展,已经不再遵循摩尔定律,CPU的频率受制于材料的限制不再有大的提升,而改为是从核数的增加上提升能力,当程序需要使用多核资源时,Reactor模型就会悲剧, 为什么呢?
如果程序业务很简单,例如只是简单的访问一些提供了并发访问的服务,就可以直接开启多个反应堆,每个反应堆对应一颗CPU核心,这些反应堆上跑的请求互不相关,这是完全可以利用多核的。例如Nginx这样的http静态服务器。
如果程序比较复杂,例如一块内存数据的处理希望由多核共同完成,这样反应堆模型就很难做到了,需要昂贵的代价,引入许多复杂的机制。
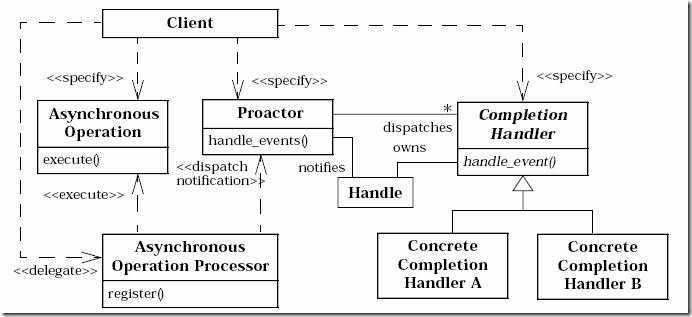
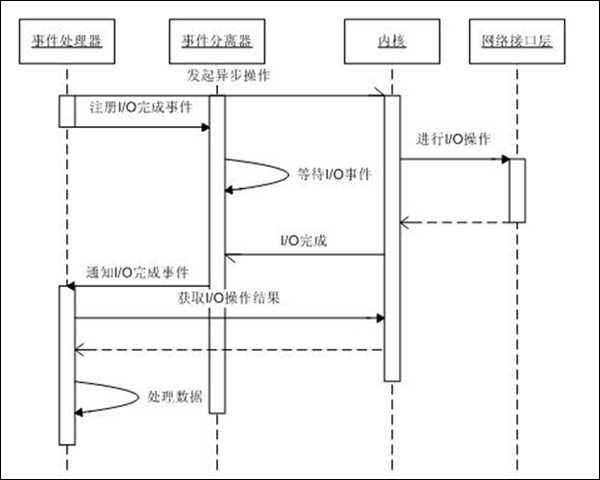
具体流程如下:
从上面的处理流程,我们可以发现proactor模型最大的特点就是Proactor最大的特点是使用异步I/O。所有的I/O操作都交由系统提供的异步I/O接口去执行。工作线程仅仅负责业务逻辑。在Proactor中,用户函数启动一个异步的文件操作。同时将这个操作注册到多路复用器上。多路复用器并不关心文件是否可读或可写而是关心这个异步读操作是否完成。异步操作是操作系统完成,用户程序不需要关心。多路复用器等待直到有完成通知到来。当操作系统完成了读文件操作——将读到的数据复制到了用户先前提供的缓冲区之后,通知多路复用器相关操作已完成。多路复用器再调用相应的处理程序,处理数据。
Proactor增加了编程的复杂度,但给工作线程带来了更高的效率。Proactor可以在系统态将读写优化,利用I/O并行能力,提供一个高性能单线程模型。在windows上,由于没有epoll这样的机制,因此提供了IOCP来支持高并发, 由于操作系统做了较好的优化,windows较常采用Proactor的模型利用完成端口来实现服务器。在linux上,在2.6内核出现了aio接口,但aio实际效果并不理想,它的出现,主要是解决poll性能不佳的问题,但实际上经过测试,epoll的性能高于poll+aio,并且aio不能处理accept,因此linux主要还是以Reactor模型为主。
在不使用操作系统提供的异步I/O接口的情况下,还可以使用Reactor来模拟Proactor,差别是:使用异步接口可以利用系统提供的读写并行能力,而在模拟的情况下,这需要在用户态实现。具体的做法只需要这样:
我们知道,Boost.asio库采用的即为Proactor模型。不过Boost.asio库在Linux平台采用epoll实现的Reactor来模拟Proactor,并且另外开了一个线程来完成读写调度。
在《Linux高性能服务器编程》一书中(PS:一本好书,推荐购买阅读!)为我们提供一种精妙的设计思路:
两个模式的相同点,都是对某个IO事件的事件通知(即告诉某个模块,这个IO操作可以进行或已经完成)。在结构上两者也有相同点:demultiplexor负责提交IO操作(异步)、查询设备是否可操作(同步),然后当条件满足时,就回调注册处理函数。
不同点在于,异步情况下(Proactor),当回调注册的处理函数时,表示IO操作已经完成;同步情况下(Reactor),回调注册的处理函数时,表示IO设备可以进行某个操作(can read or can write),注册的处理函数这个时候开始提交操作。
至于两种模式孰优孰劣的问题,笔者以为差异并不是特别大。两种模式的设计思想均足以很好的胜任高并发,海量连接的应用要求。当然,就目前笔者有限的了解,Reactor的应用实例还是更多一些,尤其是在Linux平台下。
笔者水平有限,疏谬之处,万望斧正!
标签:过程 tip png 1.0 gray 无法 增加 时间片 服务器编程
原文地址:http://www.cnblogs.com/enumhack/p/7472878.html