标签:好的 无法 含义 文件 而且 jpeg 分享 问题 读取
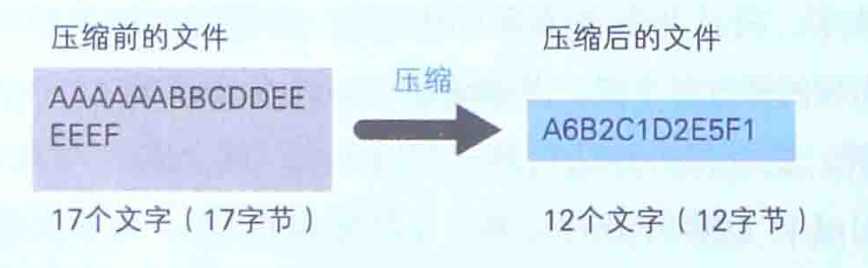
以示例来描述一下这个压缩机制:AAAAAABBCDDEEEEEF
由于半角字母中,1个字符是作为1个字节的数据被保存在文件中的。因此上述的文件大小就是17字节。好,那我们现在开始以“
上述的压缩方法称为RLE(Run Length Encoding,行程长度编码)算法。RLE算法是一种很好的压缩算法,经常被用于压缩传真的图像等。因为图像文件本质上也是字节数据的集合体。
然而,在实际的文本中,同样字符多次重复出现的情况并不多见。虽然针对相同数据经常连续出现的图像、文件等,RLE算法可以发挥不错的效果,但它并不适合文本文件的压缩。不过,因为该压缩机制非常简单,因此使用RLE算法的程序也相对更容易编写。
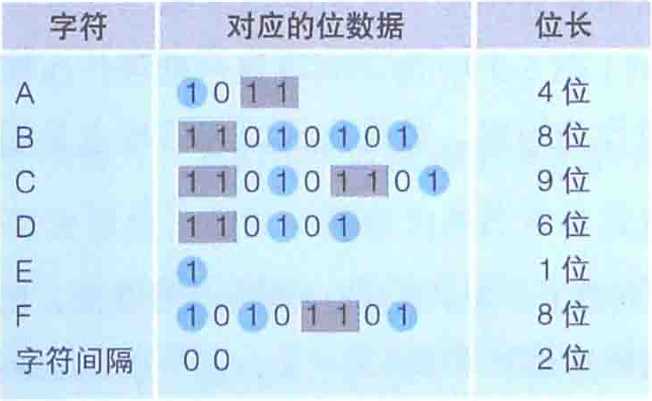
莫尔斯编码把一般文本中出现频率高的字符用短编码来表示。这里所说的出现频率,不是通过对出版物等文章进行统计调查得来的,而是根据印刷行业的印刷活字数目而确定的。如上表所示,假设表示短点的位是1,表示长点的位时11的话,那么E(嘀)这一字符的数据就可以用1位的1来表示,C(嗒嘀嗒嘀)这一字符的数据就可以用9位的110101101来表示。在实际的莫尔斯编码中。如果短点的长度是1,长点的长度就是3,短点和长点的间隔就是1.这里的长度指的是声音的长度。接下来,就让我们尝试一下用莫尔斯编码来表示前面提到的AAAAAABBCDDEEEEEF这个17个字符的文本。在莫尔斯编码中,各个字符之间需要加入表示间隔的符号。这里我们用00来进行区分。因此,就编程了A*6+B*2+C*1+D*2+E*5+F*1+字符间隔*16=4*6+8*2+9*1+6*2+1*5+8*1+2*16=106位=14字节。因为文件只能以字节位单位来存储数据,因此不满1字节的部分就要圆整成1个字节。如果所有字符占用的空间都是1个字节(8位),这样文本中列出来的17个字符=17字节,那么摩尔斯电码的压缩比率就是14/17=82%。
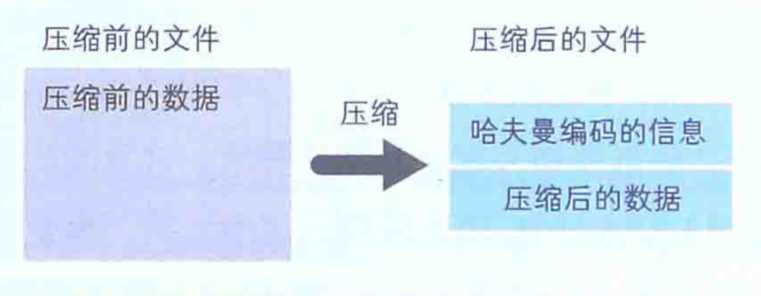
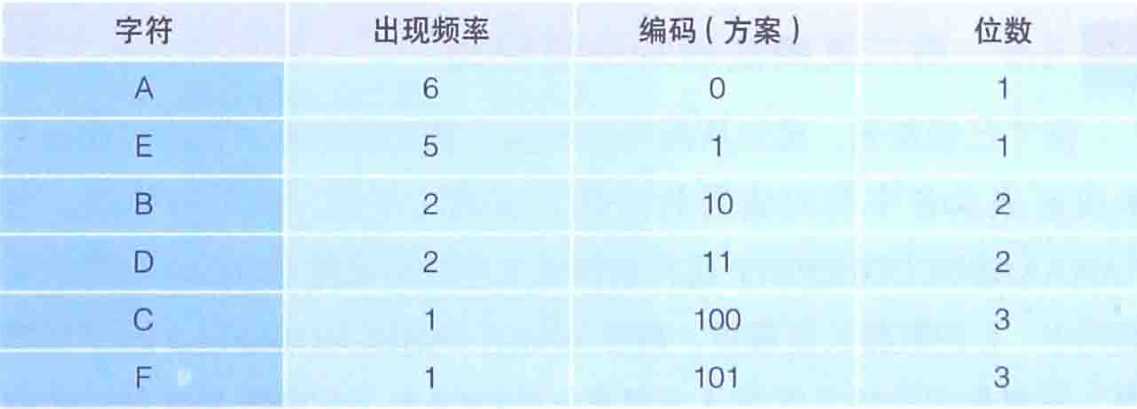
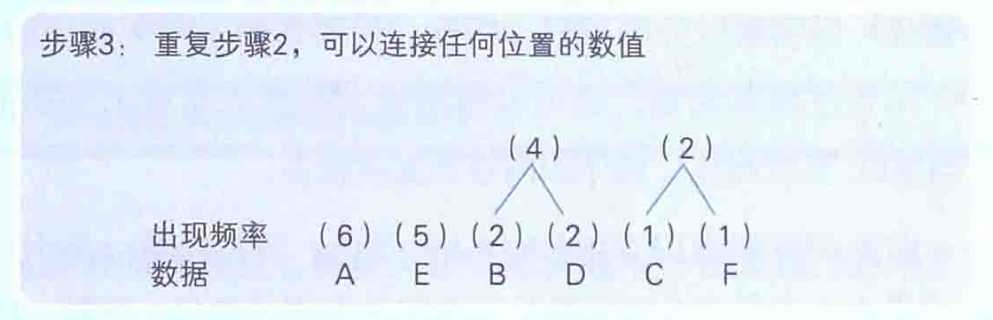
哈夫曼算法是指,为各压缩对象文件分别构造最佳的编码体系,并以该编码体系为基础来进行压缩。因此,用什么样式的编码(哈夫曼编码)对数据进行分割,就要由各个文件而定。用哈夫曼算法压缩过的文件中,存储着哈夫曼编码信息和压缩过的数据,如下图:
接下来,我们尝试一下把AAAAAABBCDDEEEEEF这些字符按照“出现频率高的字符用尽量少的位数编码来表示”这一原则进行整理。我们假定用下面的方案:



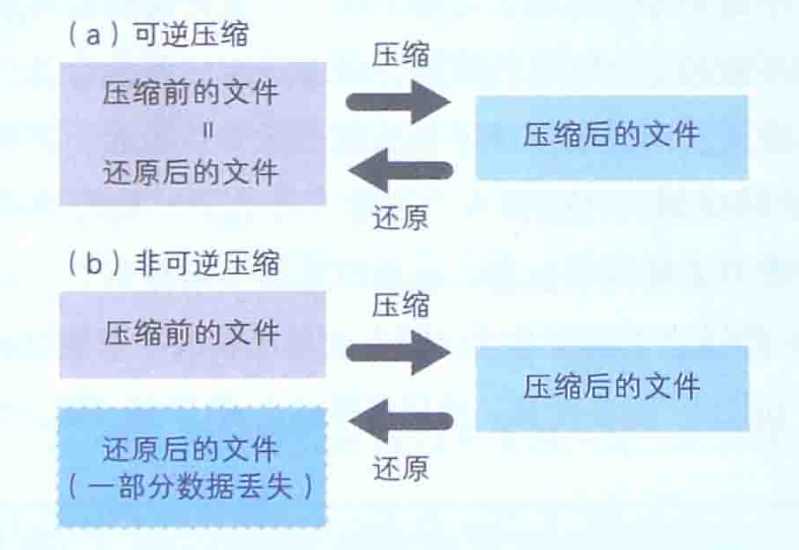
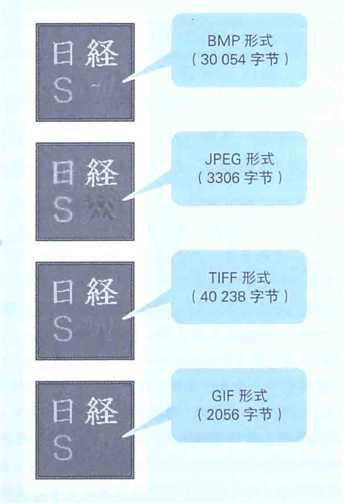
JPEG格式和GIF格式的图像文件有一些模糊,是因为他们是非可逆压缩,因此还原后会有一些模糊。而GIF格式的文件虽然是可逆压缩,但因为有色数不能超过256色的限制,所以还原后颜色信息会有一些缺失,进而导致了图像模糊。TIFF格式的图像文件虽然不模糊,但却比原始的BMP格式文件还要大,因为TIFF格式的文件中带有各种标签信息。
标签:好的 无法 含义 文件 而且 jpeg 分享 问题 读取
原文地址:http://www.cnblogs.com/Helius/p/7476522.html