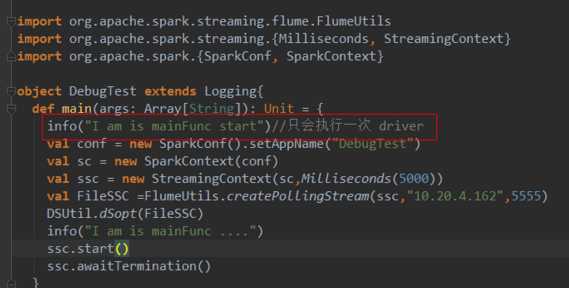
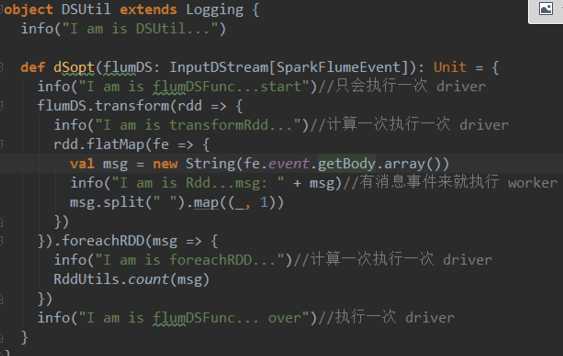
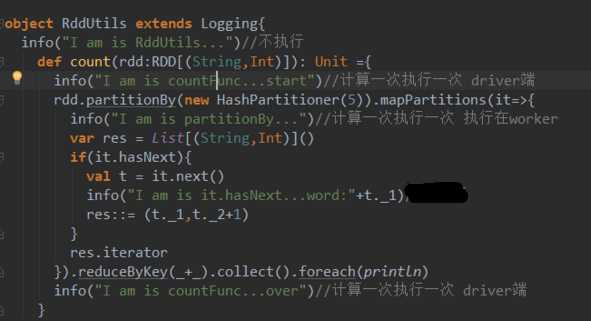
标签:otf div cti color 等等 代码执行 序列化 个人 流程
自己编写的spark代码执行流程
原文地址:http://www.cnblogs.com/irich/p/7479164.html