标签:请求转发 ras 网络 eve hbase 自己的 node 角色 间隔
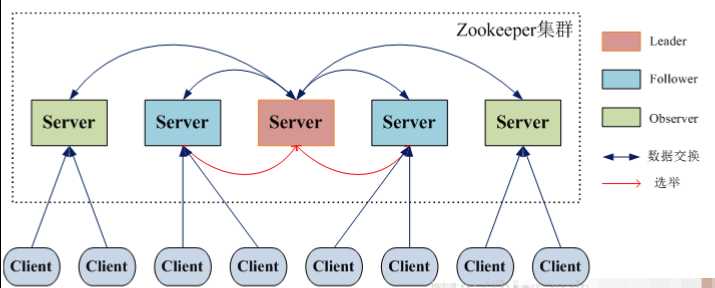
一、ZooKeeper的角色
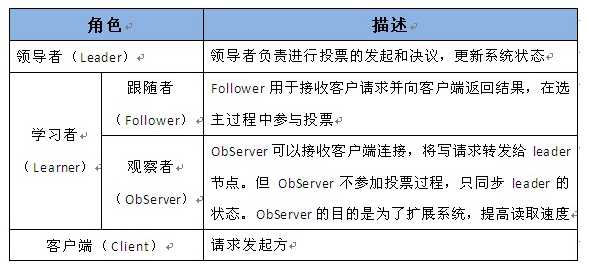
领导者(Leader),负责进行投票的发起和决议,更新系统状态。
学习者(Learner),包括跟随者(Follower)和观察者(Observer),Follower用于接受客户端请求并想客户端返回结果,在选主过程中参与投票Observer可以接受客户端连接,将写请求转发给Leader,但Observer不参加投票过程,只同步Leader的状态,Observer的目的是为了扩展系统,提高读取速度。
客户端(Client),请求发起方。
ZooKeeper的核心是原子广播,这个机制保证了各个Server之间的同步。实现这个机制的协议叫做Zab协议。Zab协议有两种模式,它们分别是恢复模式(选主)和广播模式(同步)。当服务启动或者在领导者崩溃后,Zab就进入了恢复模式,当领导者被选举出来,且大多数Server完成了和Leader的状态同步以后,恢复模式就结束了。状态同步保证了Leader和Server具有相同的系统状态。
为了保证事务的顺序一致性,ZooKeeper采用了递增的事务id号(zxid)来标识事务。所有的提议(proposal)都在被提出的时候加上了zxid。实现中zxid是一个64位的数字,它高32位是epoch用来标识Leader关系是否改变,每次一个Leader被选出来,它都会有一个新的epoch,标识当前属于那个Leader的统治时期。低32位用于递增计数。
每个Server在工作过程中有三种状态:
二、ZooKeeper的读写机制
1、ZooKeeper是一个由多个Server组成的集群
2、一个Leader,多个Follower
3、每个server保存一份数据副本
4、全局数据一致
5、分布式读写
6、更新请求转发,由Leader实施
三、ZooKeeper的保证(Consistency Guarantees)
ZooKeeper是一个高效的、可扩展的服务,read和write操作都被设计为快速的,read比write操作更快。
1、顺序一致性(Sequential Consistency):从一个客户端来的更新请求会被顺序执行。
2、原子性(Atomicity):更新要么成功要么失败,没有部分成功的情况。
3、唯一的系统镜像(Single System Image):无论客户端连接到哪个Server,看到系统镜像是一致的。
4、可靠性(Reliability):更新一旦有效,持续有效,直到被覆盖。
5、时间线(Timeliness):保证在一定的时间内各个客户端看到的系统信息是一致的。
四、ZooKeeper节点数据操作流程
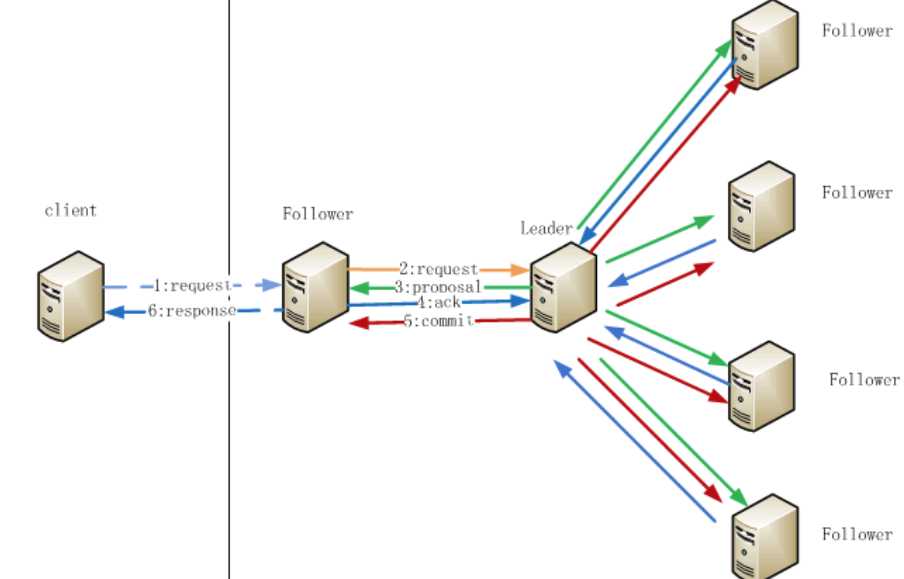
注:
Follower主要有四个功能:
Follower的消息循环处理如下几种来自Leader的消息:
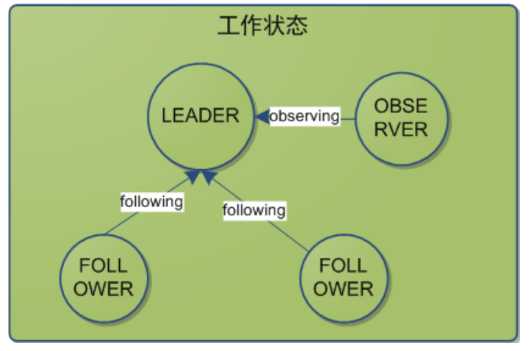
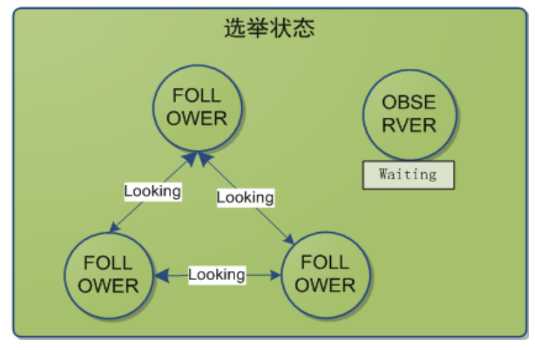
五、ZooKeeper Leader选举
半数通过:
1、A提案说,我要选自己,B你同意吗?C你同意吗?B说,我同意选A;C说,我同意选A。(注意,这里超过半数了,其实在现实世界选举已经成功了。但是计算机世界是很严格,另外要理解算法,要继续模拟下去。)
2、接着B提案说,我要选自己,A你同意吗;A说,我已经超半数同意当选,你的提案无效;C说,A已经超半数同意当选,B提案无效。
3、接着C提案说,我要选自己,A你同意吗;A说,我已经超半数同意当选,你的提案无效;B说,A已经超半数同意当选,C的提案无效。
4、选举已经产生了Leader,后面的都是Follower,只能服从Leader的命令。而且这里还有个小细节,就是其实谁先启动谁当头。
六、zxid
ZNode节点的状态信息中包含zxid, 那么什么是zxid呢?
ZooKeeper状态的每一次改变, 都对应着一个递增的Transaction id, 该id称为zxid. 由于zxid的递增性质, 如果zxid1小于zxid2, 那么zxid1肯定先于zxid2发生。
创建任意节点, 或者更新任意节点的数据, 或者删除任意节点, 都会导致ZooKeeper状态发生改变, 从而导致zxid的值增加。
七、ZooKeeper工作原理
1、ZooKeeper的核心是原子广播,这个机制保证了各个Server之间的同步。实现这个机制的协议叫做Zab协议。Zab协议有两种模式,它们分别是恢复模式和广播模式。当服务启动或者在领导者崩溃后,Zab就进入了恢复模式,当领导者被选举出来,且大多数server的完成了和Leader的状态同步以后,恢复模式就结束了。状态同步保证了Leader和Server具有相同的系统状态
2、一旦Leader已经和多数的Follower进行了状态同步后,他就可以开始广播消息了,即进入广播状态。这时候当一个Server加入ZooKeeper服务中,它会在恢复模式下启动,发现Leader,并和Leader进行状态同步。待到同步结束,它也参与消息广播。ZooKeeper服务一直维持在Broadcast状态,直到Leader崩溃了或者Leader失去了大部分的Followers支持。
3、广播模式需要保证proposal被按顺序处理,因此zk采用了递增的事务id号(zxid)来保证。所有的提议(proposal)都在被提出的时候加上了zxid。实现中zxid是一个64为的数字,它高32位是epoch用来标识Leader关系是否改变,每次一个Leader被选出来,它都会有一个新的epoch。低32位是个递增计数。
4、当Leader崩溃或者Leader失去大多数的Follower,这时候zk进入恢复模式,恢复模式需要重新选举出一个新的Leader,让所有的Server都恢复到一个正确的状态。
5、每个Server启动以后都询问其它的Server它要投票给谁。
6、对于其他Server的询问,Server每次根据自己的状态都回复自己推荐的Leader的id和上一次处理事务的zxid(系统启动时每个Server都会推荐自己)
7、收到所有Server回复以后,就计算出zxid最大的哪个Server,并将这个Server相关信息设置成下一次要投票的Server。
8、计算这过程中获得票数最多的的Sever为获胜者,如果获胜者的票数超过半数,则改Server被选为Leader。否则,继续这个过程,直到Leader被选举出来
9、Leader就会开始等待Server连接
10、Follower连接Leader,将最大的zxid发送给Leader
11、Leader根据Follower的zxid确定同步点
12、完成同步后通知Follower已经成为UPTODATE状态
13、Follower收到UPTODATE消息后,又可以重新接受Client的请求进行服务了
八、数据一致性与paxos算法
据说Paxos算法的难理解与算法的知名度一样令人敬仰,所以我们先看如何保持数据的一致性,这里有个原则就是:
总结:
ZooKeeper作为Hadoop项目中的一个子项目,是Hadoop集群管理的一个必不可少的模块,它主要用来控制集群中的数据,如它管理Hadoop集群中的NameNode,还有Hbase中Master Election、Server之间状态同步等。
关于Paxos算法可以查看文章ZooKeeper全解析——Paxos作为灵魂
推荐书籍:《从Paxos到ZooKeeper分布式一致性原理与实践》
九、Observer
1、ZooKeeper需保证高可用和强一致性;
2、为了支持更多的客户端,需要增加更多Server;
3、Server增多,投票阶段延迟增大,影响性能;
4、权衡伸缩性和高吞吐率,引入Observer
5、Observer不参与投票;
6、Observers接受客户端的连接,并将写请求转发给Leader节点;
7、加入更多Observer节点,提高伸缩性,同时不影响吞吐率
十、 为什么ZooKeeper集群的数目,一般为奇数个?
1、Leader选举算法采用了Paxos协议;
2、Paxos核心思想:当多数Server写成功,则任务数据写成功如果有3个Server,则两个写成功即可;如果有4或5个Server,则三个写成功即可。
3、Server数目一般为奇数(3、5、7)如果有3个Server,则最多允许1个Server挂掉;如果有4个Server,则同样最多允许1个Server挂掉由此,我们看出3台服务器和4台服务器的的容灾能力是一样的,所以为了节省服务器资源,一般我们采用奇数个数,作为服务器部署个数。
十一、ZooKeeper的数据模型
1、层次化的目录结构,命名符合常规文件系统规范
2、每个节点在ZooKeeper中叫做znode,并且其有一个唯一的路径标识
3、节点ZNode可以包含数据和子节点,但是EPHEMERAL类型的节点不能有子节点
4、ZNode中的数据可以有多个版本,比如某一个路径下存有多个数据版本,那么查询这个路径下的数据就需要带上版本
5、客户端应用可以在节点上设置监视器
6、节点不支持部分读写,而是一次性完整读写
ZooKeeper会维护一个具有层次关系的数据结构,它非常类似于一个标准的文件系统,如图所示:
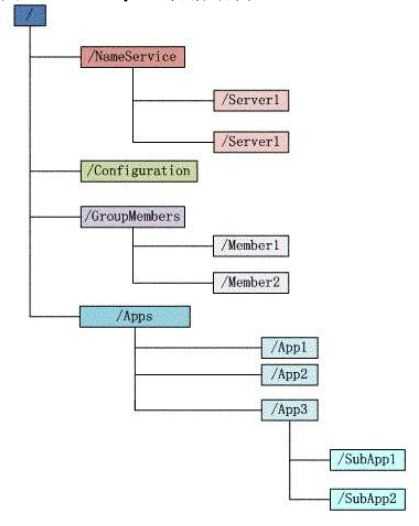
ZooKeeper这种数据结构有如下这些特点:
十二、ZooKeeper的节点
1、ZNode有两种类型,短暂的(ephemeral)和持久的(persistent)
2、ZNode的类型在创建时确定并且之后不能再修改
3、短暂zNode的客户端会话结束时,ZooKeeper会将该短暂ZNode删除,短暂ZNode不可以有子节点
4、持久ZNode不依赖于客户端会话,只有当客户端明确要删除该持久ZNode时才会被删除
5、ZNode有四种形式的目录节点
6、PERSISTENT(持久的)
7、EPHEMERAL(暂时的)
8、PERSISTENT_SEQUENTIAL(持久化顺序编号目录节点)
9、EPHEMERAL_SEQUENTIAL(暂时化顺序编号目录节点)
十三、ZooKeeper Session
Client和Zookeeper集群建立连接,整个Session状态变化如图所示:
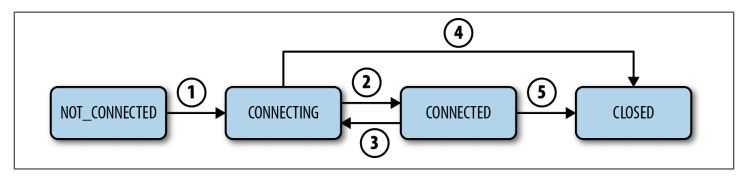
如果Client因为Timeout和ZooKeeper Server失去连接,Client处在CONNECTING状态,会自动尝试再去连接Server,如果在Session有效期内再次成功连接到某个Server,则回到CONNECTED状态。
注意:如果因为网络状态不好,Client和Server失去联系,Client会停留在当前状态,会尝试主动再次连接Zookeeper Server。Client不能宣称自己的Session expired,Session expired是由ZooKeeper Server来决定的,client可以选择自己主动关闭Session。
十四、ZooKeeper watch
Zookeeper watch是一种监听通知机制。Zookeeper所有的读操作getData(),getChildren()和 exists()都可以设置监视(watch),监视事件可以理解为一次性的触发器,官方定义如下: a watch event is one-time trigger, sent to the client that set the watch, whichoccurs when the data for which the watch was set changes。watch的三个关键点:
1、(一次性触发)One-time trigger
2、(发送至客户端)Sent to the client
3、(被设置watch的数据)The data for which the watch was set
ZooKeeper中的监视是轻量级的,因此容易设置、维护和分发。当客户端与ZooKeeper服务器失去联系时,客户端并不会收到监视事件的通知,只有当客户端重新连接后,若在必要的情况下,以前注册的监视会重新被注册并触发,对于开发人员来说这通常是透明的。只有一种情况会导致监视事件的丢失,即:通过exists()设置了某个ZNode节点的监视,但是如果某个客户端在此ZNode节点被创建和删除的时间间隔内与ZooKeeper服务器失去了联系,该客户端即使稍后重新连接ZooKeeper服务器后也得不到事件通知。
十五、Zab: Broadcasting State Updates
ZooKeeper Server接收到一次Request,如果是Follower,会转发给Leader,Leader执行请求并通过Transaction的形式广播这次执行。ZooKeeper集群如何决定一个Transaction是否被commit执行?通过“两段提交协议”(a two-phase commit):
Zab协议保证:
“两段提交协议”最大的问题是如果Leader发送了PROPOSAL消息后crash或暂时失去连接,会导致整个集群处在一种不确定的状态(Follower不知道该放弃这次提交还是执行提交)。ZooKeeper这时会选出新的leader,请求处理也会移到新的Leader上,不同的Leader由不同的epoch标识。切换Leader时,需要解决下面两个问题:
Never forget delivered messages
Leader在COMMIT投递到任何一台Follower之前Crash,只有它自己Commit了。新Leader必须保证这个事务也必须Commit。
Let go of messages that are skipped
Leader产生某个proposal,但是在Crash之前,没有Follower看到这个proposal。该Server恢复时,必须丢弃这个proposal。
ZooKeeper会尽量保证不会同时有2个活动的Leader,因为2个不同的Leader会导致集群处在一种不一致的状态,所以Zab协议同时保证:
这里的quorum是一半以上的Server数目,确切的说是有投票权力的Server(不包括Observer)。
十六、ZooKeeper写流程:
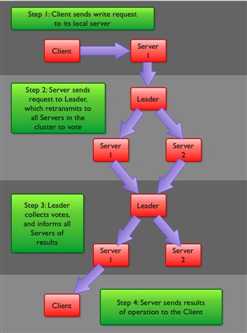
客户端首先和一个Server或者Observe(可以认为是一个Server的代理)通信,发起写请求,然后Server将写请求转发给Leader,Leader再将写请求转发给其他Server,Server在接收到写请求后写入数据并相应Leader,Leader在接收到大多数写成功回应后,认为数据写成功,相应Client。
ZooKeeper的写数据流程主要分为以下几步:
参考:
http://www.cnblogs.com/raphael5200/p/5285583.html(以上内容大部分转自此篇文章)
http://www.cnblogs.com/lpshou/archive/2013/06/14/3136738.html
http://www.cnblogs.com/edison2012/p/5654011.html(以上内容小部分转自此篇文章)
http://blog.csdn.net/u010330043/article/details/51209939(以上内容小部分转自此篇文章)
http://blog.csdn.net/xuxiuning/article/details/51218941
http://cailin.iteye.com/blog/2014486/
http://blog.chinaunix.net/uid-13875633-id-4551483.html
http://www.cnblogs.com/xubiao/p/5551426.html
http://blog.csdn.net/xlgen157387/article/details/53572760
http://zhengchao730.iteye.com/blog/1839755
http://blog.chinaunix.net/uid-26748613-id-4536290.html
http://liufengyi2006123-sina-com.iteye.com/blog/1886255
标签:请求转发 ras 网络 eve hbase 自己的 node 角色 间隔
原文地址:http://www.cnblogs.com/EasonJim/p/7481373.html