标签:video push from load file eva 业务 原因 oms
typedef struct index_node
{
uint32_t node_pos;//for up level loop
struct index_node *prev_p;//for loop
struct index_node *next_p;//for loop
uint32_t sum_data_num;//to do,can dynamic,if data_num is 0,the index_node equal NULL
uint32_t use_data_num;//for loop
uint32_t *data_p;
}INDEX_NODE;
修改之前
typedef struct index_hash_value
{
uint32_t my_pos;//for lock
uint32_t del_data_num;//for check if shrink
uint32_t use_data_num;//for check if shrink
uint32_t sum_node_num;//for loop,just ++
struct index_node head;//head count 1
}INDEX_HASH_VALUE;
修改之后
typedef struct index_hash_value
{
uint32_t my_pos;//for lock
uint32_t del_data_num;//for check if shrink
uint32_t use_data_num;//for check if shrink
uint32_t sum_node_num;//for loop,just ++
struct index_node *head_p;//head count 1
}INDEX_HASH_VALUE;
当只有head、last node节点时,发现last的prev_p和next_p指针与
head不一致,引发段错误。
1.在shrink_index函数中
1.2.generate new hash_values
index_hash_value new_one_hash_value = {0};//init 0
index_hash_value * p_hash_value = &new_one_hash_value;
1.3.erase old and insert new
{index_map.insert ( std::pair<std::string,index_hash_value>(index_hash_key,new_one_hash_value) );}
如果是成员变量,在index_map.insert的时候value以及里面的head内存地址会发生改变,而新分配的节点
new_one_hash_value里面last_node指向的还是局部变量new_one_hash_value中的head,所有后续遍历的时候会有问题。
指针隐式的指向了局部变量,使用的时候段错误。
不能,因为insert的时候是++,clear和shrink的时候不是从最后一个元素开始,如果-- 会造成my_pos有重复的问题。
if (!hit_hash_key) {return false;}
会导致产生的新2.generate new hash_values产生的内存不被销毁么?
不会,因为AutoLock_Mutex auto_lock0(&index_update_lock);保证了对index_map的update操作
都会被串行化,而之前已经有判断 if (query_out.size() <= 0 )
{return false;}
所以hit_hash_key应该为true。
shrink_index
clear_all_index
clear_index
delete_index
insert_index
all_query_index
cross_query_index
int main() { while(1) { Index_Core idx_core(128,3); for (int i = 1 ; i < 100;i++) for (char j = ‘a‘;j<=‘z‘;j++) { std::string str(i,j); for (int k = 0 ;k < 1000;k++) {idx_core.insert_index(str,k);} printf("insert %s\n",str.c_str()); } printf("==================\n"); for (int i = 1 ; i < 60;i++) for (char j = ‘a‘;j<=‘m‘;j++) { std::string str(i,j); for (int k = i ;k < 300;k++) {idx_core.delete_index(str,k);} printf("delete %s\n",str.c_str()); } for (int i = 1 ; i < 80;i++) for (char j = ‘a‘;j<=‘z‘;j++) { std::string str(i,j); idx_core.shrink_index(str); printf("shrink %s\n",str.c_str()); } for (int i = 1 ; i < 90;i++) for (char j = ‘a‘;j<=‘z‘;j++) { std::string str(i,j); idx_core.clear_index(str); printf("clear %s\n",str.c_str()); } fflush(stdout); sleep(1); } }
#define THREAD_NUM 1 Index_Core idx_core(8,64); void *myfunc(void *arg) { while(1) { #if 1 for (int i = 1 ; i < 15;i++) for (char j = ‘a‘;j<=‘z‘;j++) { std::vector<uint32_t> query_out; std::string str(i,j); idx_core.all_query_index(str,query_out); if (query_out.size() > 0) { printf("%s[%d]:",str.c_str(),query_out.size()); for (int k = 0 ; k < query_out.size(); k++) {printf("%d ",query_out[k]);} printf(":%s\n",str.c_str()); } } #endif fflush(stdout); sleep(1); } } int main(int argc,char *argv[]) { pthread_t tid[THREAD_NUM]; int id[THREAD_NUM] = {0}; for (int i = 0; i < THREAD_NUM; i++) { id[i] = i; if (pthread_create(&tid[i],NULL,&myfunc,(void*)&id[i]) != 0) { fprintf(stderr,"thread create failed\n"); return -1; } } while(1) { for (int i = 1 ; i < 10;i++) for (char j = ‘a‘;j<=‘z‘;j++) { std::string str(i,j); for (int k = 0 ;k < 30;k++) {idx_core.insert_index(str,k);} } #if 1 for (int i = 1 ; i < 10;i++) for (char j = ‘a‘;j<=‘m‘;j++) { std::string str(i,j); for (int k = (i+2);k < 10;k++) {idx_core.delete_index(str,k);} } #endif #if 1 for (int i = 1 ; i < 10;i++) for (char j = ‘a‘;j<=‘z‘;j++) { std::string str(i,j); idx_core.shrink_index(str); } #endif #if 1 for (int i = 3 ; i < 10;i++) for (char j = ‘a‘;j<=‘z‘;j++) { std::string str(i,j); idx_core.clear_index(str); } #endif // sleep(3); } for (int i = 0 ;i < THREAD_NUM; i++) pthread_join(tid[i],NULL); }
1.使用type或view分离检索数据
2.请求时携带归并数量,返回时携带分词结果。
2017/3/3
发现jsoncpp的可能bug,内存被破坏
且jsoncpp占用太多内存
187 Byte 数据 循环生成100w次,占用1G内存。
每个数据约耗1073Byte。
2017/3/7
aws ec2
rapidjson:
空对象
$1 = 96
{\"name\":\"json\",\"array\":[{\"cpp\":\"jsoncpp\"},{\"java\":\"jsoninjava\"},{\"php\":\"support\"}]},100Byte,10w,内存占用440M。
jspncpp:
空对象
$1 = 40
{\"name\":\"json\",\"array\":[{\"cpp\":\"jsoncpp\"},{\"java\":\"jsoninjava\"},{\"php\":\"support\"}]},100Byte,50w,内存占用700M。
cjson:
$1 = 64
{\"name\":\"json\",\"array\":[{\"cpp\":\"jsoncpp\"},{\"java\":\"jsoninjava\"},{\"php\":\"support\"}]},100Bye,50w,500M.
这也佐证了为什么sort函数之前jisuan_score时没问题,sort
之后取breif会core。
由于std::sort中重载<或>符号的时候,==情况必须返回false,否则会core,详见
http://blog.sina.com.cn/s/blog_79d599dc01012m7l.html
导致程序其他地方的问题,引发了jsoncpp的core。
分析:
1.core时除了注意发生core的位置,还要关注代码上下文或者相关的”代码环境“
2.问题除了直接产生,可能是别的问题影响了“代码环境”比如公用的堆,栈等
总结:
1.外部集成的库最好经过集成和压力测试,至少备注一下是个隐患风险点
2.参考外界代码时,尽量不要更改重要代码,如果不知道什么是重要,在完成功能的基础上,最好啥也不改。
原始的Reactor模型是:
分析:
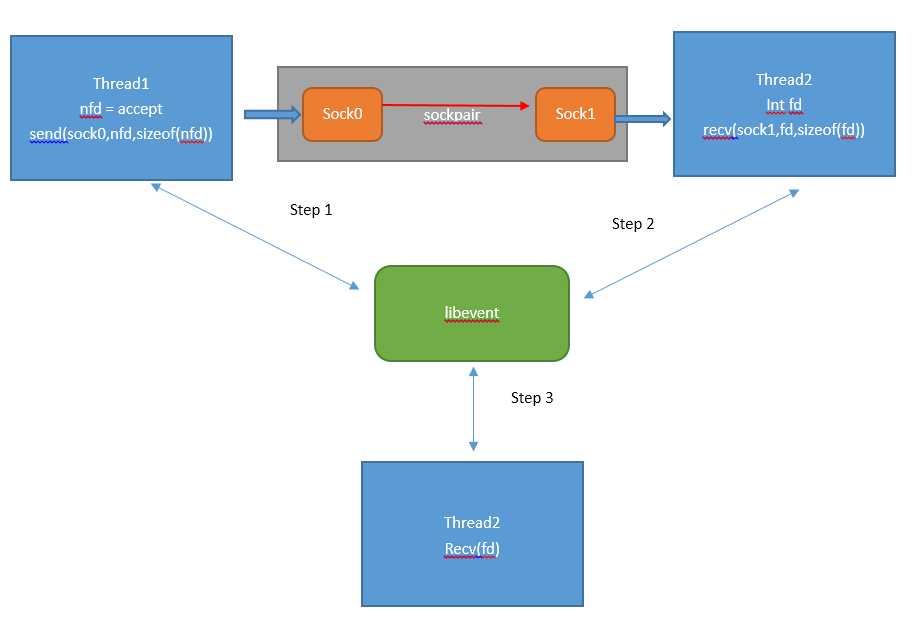
netstat 观察到close_wait过多
1.close_wait是被动关闭时,服务端没有调用close导致,说明服务端accept处理成功了
2.服务端没有close掉
原因:
thread1线程accept成功时向sock0发送了4字节的建连sock的fd
thread2线程异步的调用接收sock1的信息,如果接收全是4字节,没问题,但如果
有一次收到的buffer < 4字节,会导致数据不以4字节对齐,接收到的fd不是有效的连接fd。
修改:
多个线程使用同一个listenfd,并accept(加互斥锁)之后的nfd,加入本线程的异步事件调度。
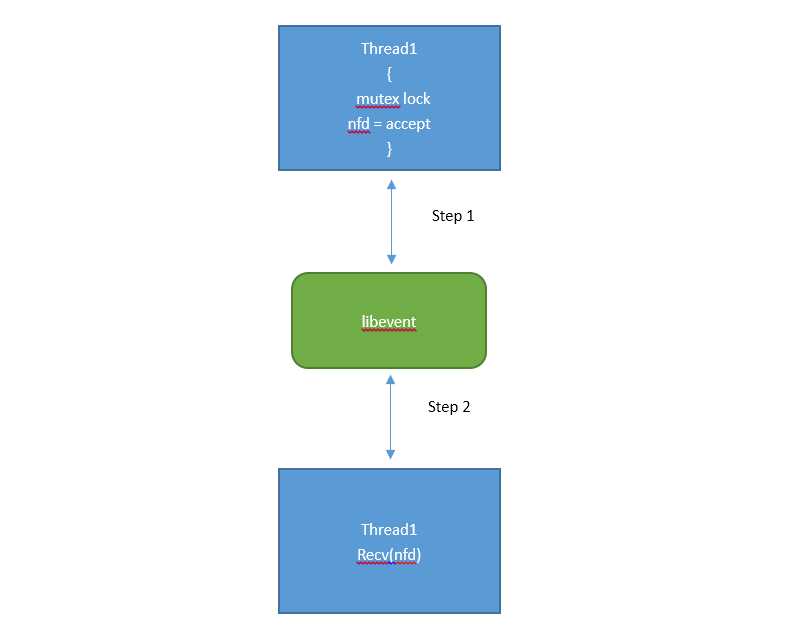
线程自适应的处理任务,任务处理不过来就accept不过来不建连,直接丢弃。
处理性能提高,减少了一个事件的注册和触发。
解决了close_wait堆积问题。
2017/3/16
编译时需要升级gcc到gcc 4.8
Makefile时要加上-lrt库,否则执行时候找不到clock_time函数?
2017/3/17
1.每到1w就output一次max_index_num
2.load_from_file 时load内容出错时,打印日志
to do:
max_index_num达到最大值时,如何处理?
下一版本解决,dump出全部di,另用一个search_engine加载,然后双buffer交换。
1.日志格式化(done 2017/5/4)
git:在service中生成log文件夹
2.增加日志,记录状态:
ret1 = parse_in_json();
ret2 = get_out_json();
3.加快or检索(done 2017/5/4)
检查每个term重要性,即term倒排的数量,超过一定阈值认为是不重要的,跳过,不参与召回
4.search_engine.h中policy_compute_score函数声明和定义不一致(done 2017/5/4)
5.load进去再dump数量不一致
1282887 dump.json.file
1284625 load.json.file
load时候部分没有load进去
cat comse.log | grep "json parse error" | wc -l
1739
应该是load入口和服务的add入口不一致,add进去,load没进去
6.dump日志的时候格式有问题(done 5/12)
把之前query的脏数据也输出了
recv和send发送数据的时候buff数据还有些脏数据没有被清理
解决方式:在recv和send后面追加\0
7.max_ret_num确定实际返回的数量(done 2017/5/10)
8.生成md5的json内容,字段颠倒有无问题(done 2017/5/16)
字段颠倒之后用json_writer.write输出的字符串都是按照字母序排列的
10.各个过程的耗时(done 1027/5/12)
11.增加view或type过滤(在打分时匹配type打0分,在search_filter阶段过滤0分,type:0代表所有)
12.传递参数过多,包个struct传递?
13.All_time打日志记录时间时,增加query和召回数量的打印
增加一个logid?
14.加快search的过程
A:对每个term有一个重要性分析,过滤掉重要性低的term?
B:在召回的过程中实现文本相关性的打分? 不符合程序的原始架构和策略一致性,召回,打分。。。
C:把词为key的term变成数字为key的term?
数字为key的term:测试1ms执行500次,使用的话需要记录term长度,使用map?
#include <iostream> //std::cout #include <algorithm> //std::lower_bound, std::upper_bound, std::sort #include <set> //std::vector #include <vector> //std::vector #include <string> //std::vector #include <sys/time.h> #define TIMER(FUNC) { struct timeval prev_time,cur_time; int count_time = 0; gettimeofday(&prev_time,NULL); gettimeofday(&cur_time,NULL); while(1) { gettimeofday(&cur_time,NULL); FUNC; count_time++; if (cur_time.tv_sec - prev_time.tv_sec >= 1) { prev_time = cur_time; printf("output timer count %d\n",count_time); fflush(stdout); count_time=0; } } } int test_string_set(std::vector<int> & term_list,std::set<int> & term4se_set ) { int or_terms_length = 0; int or_terms_num = 0; if ( term4se_set.size() > 0) { std::set<int>::iterator term_hash_it; for (int i = 0 ; i < term_list.size();i++) { term_hash_it = term4se_set.find(term_list[i]); if (term_hash_it != term4se_set.end()) { or_terms_length += term_list[i]; or_terms_num++; } } } int ret = (or_terms_num * 1000 + or_terms_length); return ret; } int main () { std::vector<int> term_list; term_list.push_back(1); term_list.push_back(8); term_list.push_back(16); term_list.push_back(3012); term_list.push_back(18); term_list.push_back(7); term_list.push_back(462); term_list.push_back(129992); std::set<int> term4se_set; term4se_set.insert(1); term4se_set.insert(16); term4se_set.insert(7); term4se_set.insert(8); term4se_set.insert(1234); term4se_set.insert(34111111); TIMER(test_string_set(term_list,term4se_set)); return 0; }
字符串为key的term:测试1ms执行311次
#include <iostream> //std::cout #include <algorithm> //std::lower_bound, std::upper_bound, std::sort #include <set> //std::vector #include <vector> //std::vector #include <string> //std::vector #include <sys/time.h> #define TIMER(FUNC) { struct timeval prev_time,cur_time; int count_time = 0; gettimeofday(&prev_time,NULL); gettimeofday(&cur_time,NULL); while(1) { gettimeofday(&cur_time,NULL); FUNC; count_time++; if (cur_time.tv_sec - prev_time.tv_sec >= 1) { prev_time = cur_time; printf("output timer count %d\n",count_time); fflush(stdout); count_time=0; } } } int test_string_set(std::vector<std::string> & term_list,std::set<std::string> & term4se_set ) { int or_terms_length = 0; int or_terms_num = 0; if ( term4se_set.size() > 0) { std::set<std::string>::iterator term_hash_it; for (int i = 0 ; i < term_list.size();i++) { term_hash_it = term4se_set.find(term_list[i]); if (term_hash_it != term4se_set.end()) { or_terms_length += term_list[i].size(); or_terms_num++; } } } int ret = (or_terms_num * 1000 + or_terms_length); return ret; } int main () { std::vector<std::string> term_list; term_list.push_back("book"); term_list.push_back("apple"); term_list.push_back("zoo"); term_list.push_back("school"); term_list.push_back("action"); term_list.push_back("gogogogo"); term_list.push_back("computer"); term_list.push_back("machine"); std::set<std::string> term4se_set; term4se_set.insert("abcd"); term4se_set.insert("action"); term4se_set.insert("computer"); term4se_set.insert("book"); term4se_set.insert("zzzzzzzzzzz"); term4se_set.insert("abcd"); TIMER(test_string_set(term_list,term4se_set)); return 0; }
已上线,效果提升1倍左右,符合测试的预期,但是内存占用较大。
==============================================
优化后
[2017-06-08 15:42:51]cal_time recall=5488|compute=64173|sort=5711|package=373 search_mode=2:recall_num=17417:query=《三生三世十里桃花》终极预告花絮首发
[2017-06-08 15:42:51]Thread[a1bb7700] Client[20]All_time[accept2recv_event=211,recv=4,parse_recv=53,do_policy=84612,send=213]:Send=HTTP/1.1 200 OK
20913 video 20 0 2393m 2.0g 1748 S 0.0 2.2 4:00.27 comse_test
==============================================
优化前
[2017-06-08 16:56:17]cal_time recall=5489|compute=127615|sort=5730|package=463 search_mode=2:recall_num=17417:query=《三生三世十里桃花》终极预告花絮首发
[2017-06-08 16:56:16]Thread[4f0ae700] Client[18]All_time[accept2recv_event=144,recv=4,parse_recv=46,do_policy=145616,send=188]:Send=HTTP/1.1 200 OK
23150 video 20 0 2979m 2.6g 1712 S 0.0 2.8 3:13.20 comse_test
==============================================
15.加快召回过程
使用bitmap节省空间,求交使用bit求交
16.title:
<我们的爱>第十二集看点
召回的关键词是 我们
bad原因一个作品名称的term由许多常见单词构成。
解决:term合并,n-gram,多层次检索,关键是各个层次之间的打分体系如何融合。
==============================================
16. 和max_ 过大
导致中间数据占用过多内存,output_buff会有限制不会吐出,浪费中间过程的内存和计算。
标签:video push from load file eva 业务 原因 oms
原文地址:http://www.cnblogs.com/dodng/p/6265992.html