标签:客户端 key 通信 rom set .com 分配 3.0 统计分析
转载至: http://lxw1234.com/archives/2015/04/101.htm mark - 参考学习
环境配置:
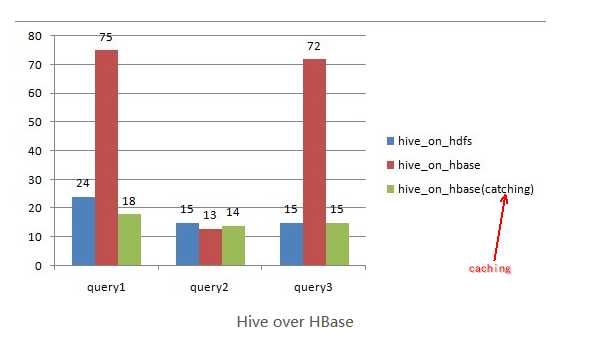
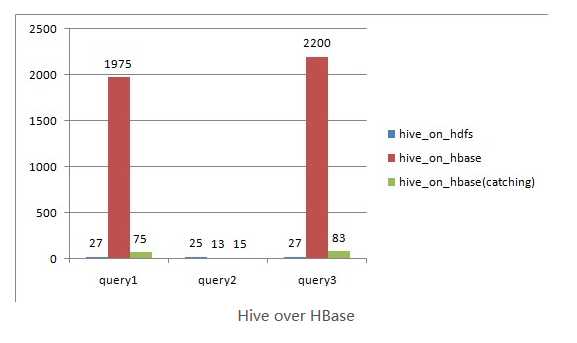
查询性能比较:
query1:
query2(根据key过滤)
query3(根据value过滤)
on_hdfs (20万记录,150M,TextFile on HDFS)
on_hbase(20万记录,160M,HFile on HDFS)
on_hdfs (2500万记录,2.7G,TextFile on HDFS)
on_hbase(2500万记录,3G,HFile on HDFS)
小结:
Hive over HBase原理
Hive与HBase利用两者本身对外的API来实现整合,主要是靠HBaseStorageHandler进行通信,利用 HBaseStorageHandler,Hive可以获取到Hive表对应的HBase表名,列簇以及列,InputFormat和 OutputFormat类,创建和删除HBase表等。
Hive访问HBase中表数据,实质上是通过MapReduce读取HBase表数据,其实现是在MR中,使用HiveHBaseTableInputFormat完成对HBase表的切分,获取RecordReader对象来读取数据。
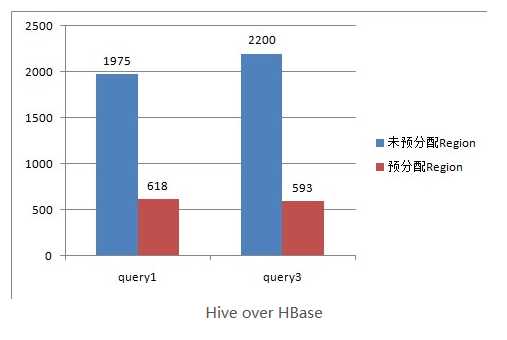
对HBase表的切分原则是一个Region切分成一个Split,即表中有多少个Regions,MR中就有多少个Map;
读取HBase表数据都是通过构建Scanner,对表进行全表扫描,如果有过滤条件,则转化为Filter。当过滤条件为rowkey时,则转化为对rowkey的过滤;
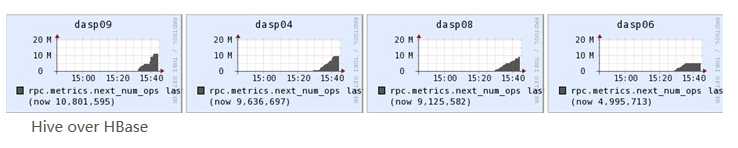
Scanner通过RPC调用RegionServer的next()来获取数据;
性能瓶颈分析
1、Map Task
下图是给该表预分配了15个Region,并且控制key均匀分布在每个Region上之后,查询的耗时对比,其本质上是Map数增加。
2. Scan RPC 调用:
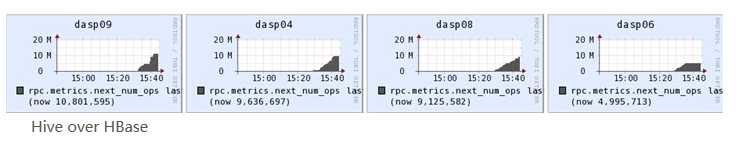

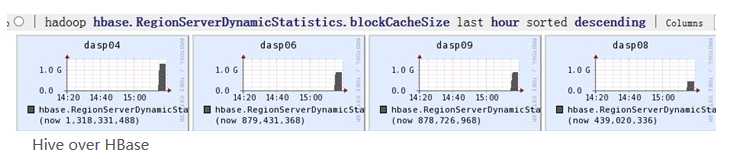
扫描器批量(Scanner Batch):缓存是面向行一级的操作,而批量则是面向列一级的操作。批量可以控制每一次next()操作要取回多少列。比如,在扫描器中设置setBatch(5),则一次next()返回的Result实例会包括5列。
3、小结:在使用Hive over HBase,对HBase中的表做统计分析时候,需要特别注意以下几个方面
Hive over HBase和Hive over HDFS性能比较分析
标签:客户端 key 通信 rom set .com 分配 3.0 统计分析
原文地址:http://www.cnblogs.com/tgzhu/p/7484073.html