标签:页面 互联网 代码 请求 算法实现 python 数据流 取出 使用
团队项目开发人员:邵文强,宁培强,邵瀚庆,潘新宇,李国峰,张晓亮
项目分析:
1. 引言
1.1 目的:为网络数据爱好者更好的收集数据
1.2背景:软件系统名称:网络爬虫
1.3 定义 :网络爬虫 搜索引擎Web url信息互联网
1.4 参考资料 百度搜索
2.任务概述
2.1 目标
系统流程图:
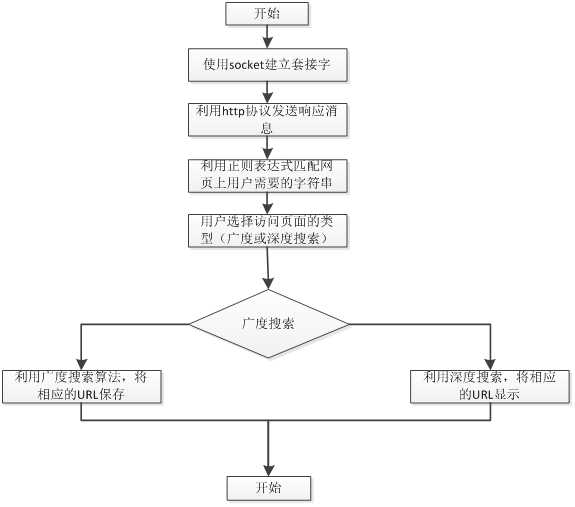
1) 客户端向服务器发送自己设定好的请求
2)通过通过http将Web服务器上协议站点的网页代码提取出来
3)亘古一定的正则表达式提取出需要的信息
4)采用深度优先so8usuo从网页中某个链接出发,访问该连接的网页,并通过递归算 法实现一次向下访问
5)采用广度优先搜索从网页中某个链接出发,访问该链接网页上的所有连接,访问完
成后,再通过递归算法实现下一层的访问
2.2 运行系统
支持所有系统
3.需求规定
3.1功能规定
从网站某一个页面开始,读取网页的内容,找到在网页中的其他链接地址,然后通过 这些链接地址寻找下一个网页。
3.2使用库
urllib
4.运行环境规定
4.1支持软件
本系统采用python制作 测试软件python2.7
4.2 数据流图
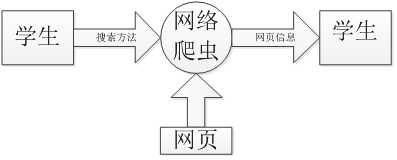
标签:页面 互联网 代码 请求 算法实现 python 数据流 取出 使用
原文地址:http://www.cnblogs.com/ligf/p/7491716.html