标签:display 计算 最小 输出 输入 oss img min 优化
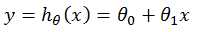
然后利用已知的数据对其中的参数进行求解,再将该函数用于新数据的预测,其中参数的求解过程称为“训练(Training) or 学习(Learning)”
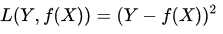
损失函数越小,就代表模型拟合的越好。
常见形式:
残差平方和(residual sum of squares)成本函数
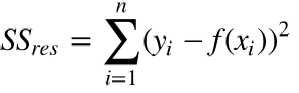
均方误差
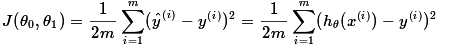
由于我们输入输出的 遵循一个联合分布,但是这个联合分布是未知的,所以无法计算。但是我们是有历史数据的,就是我们的训练集,
关于训练集的平均损失称作经验风险(empirical risk),即
,所以我们的目标就是最小化
,称为经验风险最小化。
为了平衡经验风险最小化目标与模型的复杂性(模型对数据的记性)引入结构风险,常用方法L1和L2范数。
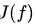
最终的优化函数是: ,即最优化经验风险和结构风险,而这个函数就被称为目标函数。
标签:display 计算 最小 输出 输入 oss img min 优化
原文地址:http://www.cnblogs.com/JueJi-2017/p/7492474.html