标签:ado 全文搜索 将不 企业级 面向 域名 multi 同步 工具
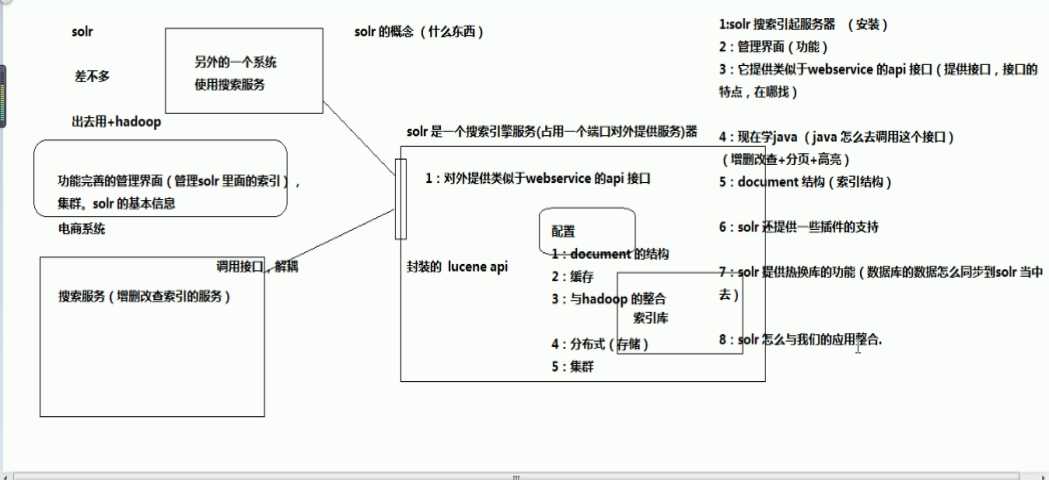
采用Java开发,基于Luncene的全文搜索服务器,同时对其进行了扩展(扩展了面向抽象编程的地方,比如分词器,查询),提供了比Lucene更为丰富的查询语言(比如,过滤器),同时实现了可配置(跟hadoop整合,之前索引结构写在代码中,现在提前定义好)、可扩展并对查询性能进行了优化,并且提供了一个完善的功能管理界面,是一款非常优秀的全文搜索引擎。
服务器 占用一个端口来提供服务 比如 可以加缓存
Solr是一个独立的企业级搜索应用服务器,它对外提供类似于Web-service的API接口。用户可以通过http请求,向搜索引擎服务器提交一定格式的XML文件,生成索引;也可以通过Http G SolrJ操作提出查找请求(也可以提交json格式),并得到XML格式的返回结果.
2.1 Luncene是一套信息检索工具包,但并不包含搜索引擎系统,它包含了索引结构,读写索引工具、相关性工具(其他的搜索组件)、排序等功能,因此在使用luncene时你扔需要关注搜索引擎系统,例如数据获取、解析、分词等方面的东西。
2.2 首先solr是基于luncene做的,solr的目标是打造一款企业级的搜索引擎系统,因此它更接近于我们认识到的搜索引擎系统,它是一个搜索引擎服务,通过各种API可以让你的应用使用搜索服务,而不需要将搜索逻辑耦合在应用中。而且solr可以根据配置文件定义数据解析的方式,更像是一个搜索框架,它也支持主从(集群中的方式)、热换库(索引的数据与数据库的同步)等操作,还添加了高亮、facet(搜索组件)等搜索引擎常见功能的支持。
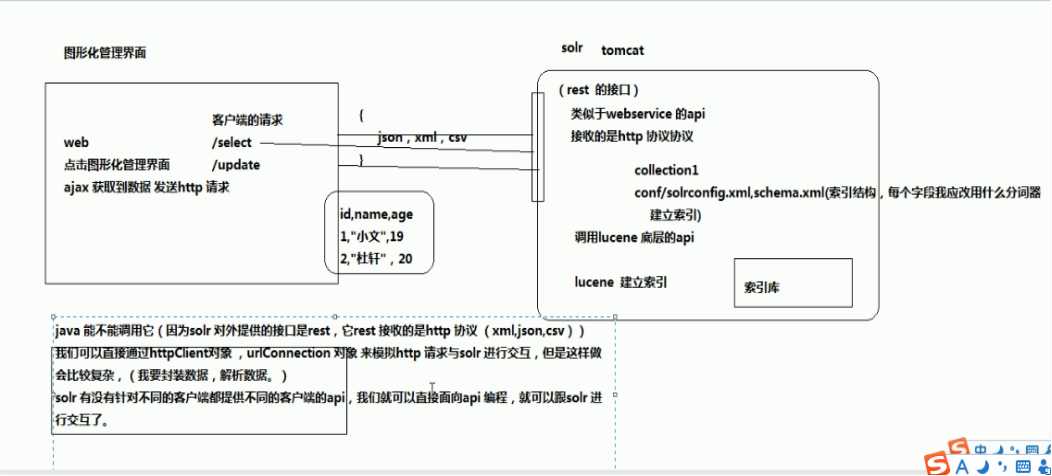
使用solrj 使用solrJava版的solrj来跟tomcat进行交互
schema.xml中 <field name=”id”(分词器名称) type=”string”(类型) indexed=”true”(是否建立索引) stored=”true”(是否存储) required=”是否是必须存在” multiValued=”false” (是否允许有多个值)/>
<dy>
schema.xml 是用来定义索引数据中的域的,包括域名称,域类型,域是否索引,是否分词,是否存储,是否标准化即 Norms ,是否存储项向量等等。
为了改进性能,可以采取以下几种措施:
solrconfig .xml 文件包含了大部分的参数用来配置Solr本身的。
标签:ado 全文搜索 将不 企业级 面向 域名 multi 同步 工具
原文地址:http://www.cnblogs.com/hotazhou/p/7500572.html